
Vous pouvez lire le billet sur le blog La Minute pour plus d'informations sur les RSS !
Canaux
4823 éléments (58 non lus) dans 55 canaux
 Dans la presse
(50 non lus)
Dans la presse
(50 non lus)
-
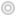 Cybergeo
(20 non lus)
Cybergeo
(20 non lus) -
Revue Internationale de Géomatique (RIG)
-
SIGMAG & SIGTV.FR - Un autre regard sur la géomatique
(7 non lus)
-
Mappemonde
(20 non lus)
-
Dans les algorithmes
(3 non lus)
Du côté des éditeurs
(3 non lus)
-
Imagerie Géospatiale
-
Toute l’actualité des Geoservices de l'IGN
(1 non lus)
-
arcOrama, un blog sur les SIG, ceux d ESRI en particulier (2 non lus)
-
arcOpole - Actualités du Programme
-
Géoclip, le générateur d'observatoires cartographiques
-
Blog GEOCONCEPT FR
Toile géomatique francophone
(5 non lus)
-
Géoblogs (GeoRezo.net)
-
Conseil national de l'information géolocalisée
-
 Geotribu
(1 non lus)
Geotribu
(1 non lus) -
Les cafés géographiques
(3 non lus)
-
UrbaLine (le blog d'Aline sur l'urba, la géomatique, et l'habitat)
-
Icem7
-
Séries temporelles (CESBIO)
-
Datafoncier, données pour les territoires (Cerema)
-
Cartes et figures du monde
-
SIGEA: actualités des SIG pour l'enseignement agricole
-
Data and GIS tips
-
Neogeo Technologies
(1 non lus)
-
ReLucBlog
-
L'Atelier de Cartographie
-
My Geomatic
-
archeomatic (le blog d'un archéologue à l’INRAP)
-
Cartographies numériques
-
Veille cartographie
-
Makina Corpus
-
Oslandia
-
Camptocamp
-
Carnet (neo)cartographique
-
Le blog de Geomatys
-
GEOMATIQUE
-
Geomatick
-
CartONG (actualités)

Toile géomatique francophone (4 non lus)
-
sur Conférence de Michel Bruneau sur le Cambodge, Institut de Géographie (Paris), samedi 18 janvier 2025
Publié: 6 January 2025, 1:12pm CET par r.a.
Samedi 18 janvier 2025, de 10h à 12h, à l’Institut de Géographie, 191 rue Saint-Jacques, 75005 Paris, le géographe Michel Bruneau viendra animer une conférence sur le Cambodge.
Dans son ouvrage Parcours d’un géographe de transitions (L’Harmattan, 2023), Michel Bruneau revient sur le chemin qui l’a conduit de la géographie tropicale à la géographie critique. Après sa thèse sur la Thaïlande, il est devenu un éminent spécialiste de l’Asie du Sud-Est qui a proposé notamment un modèle d’organisation de l’espace du Cambodge.
Source : Michel Bruneau, Carte reproduite dans BAGF ( [https:]] )
Au-delà d’une meilleure compréhension de l’organisation de l’espace cambodgien, il faudra se demander si la relation entre les structures territoriales de l’Etat-nation actuel et celles de la période précoloniale est toujours lisible.
A lire sur le site des Cafés Géo : Les Cafés Géo » Michel Bruneau, un « géographe de transitions »
-
sur Géohistoire des humains sur la Terre
Publié: 2 January 2025, 10:31pm CET par r.a.

Café de Flore, Paris, mardi 17 décembre 2024, C. Grataloup et D. Oster (de droite à gauche, photo de M. Huvet-Martinet)
Ce mardi soir, un public nombreux assiste au Café géo dont le sujet porte sur la « géohistoire des humains sur la Terre ». Pour aborder cette question un unique intervenant : Christian Grataloup, le géohistorien bien connu qui incarne largement la réflexion géohistorique depuis de nombreuses années. Auteur d’un livre d’une ambition rare (Géohistoire. Une autre histoire des humains sur la Terre, Les Arènes, 2023), C. Grataloup se propose durant cette soirée d’éclairer ce que l’histoire des sociétés doit à leur espace. Rien que cela !
DO : Ton livre Géohistoire paru l’année dernière marque l’aboutissement d’un long cheminement dans ta réflexion géohistorique. C’est peut-être pour cela que tu as choisi de le titrer sobrement Géohistoire, même si un sous-titre plus explicite l’accompagne : Une autre histoire des humains sur la Terre.
CG : En fait, le titre Géohistoire est un choix éditorial qui montre bien que l’expression créée par Fernand Braudel est tout à fait passée dans le domaine public.
DO : Les médias qui t’ont interviewé n’ont pas manqué de te demander une énième fois ta définition de la géohistoire. Tu réponds souvent qu’il s’agit d’éclairer ce que l’histoire des sociétés doit à leur espace. Dans ce livre tu évoques une synthèse de deux types de relations : les relations entre les sociétés et les relations avec le reste de la biosphère. Peux-tu préciser cet objectif ?
CG : La géohistoire assume sa bâtardise (histoire et géographie). Il faut articuler constamment les logiques d’organisation spatiale avec les processus de temporalité. Il faut tenir compte de tous ces éléments. Certains journalistes aiment dire que je suis le plus historien des géographes. Mais peut-être suis-je le plus géographe des historiens ?
Pour moi, par exemple, un des éléments clés du livre est la distance, c’est-à-dire l’éloignement ou la proximité entre les différentes sociétés, soit un élément géographique fondamental de l’évolution historique. Je parle d’un « singulier pluriel » pour une seule espèce humaine et des sociétés très différentes les unes des autres. L’histoire humaine est prise entre proximité et mobilité. Cette diversité des sociétés est un élément essentiel en même temps que le regroupement, les fusions, les diminutions, par exemple du nombre des langues D’où l’importance à mes yeux de la carte des langues au XVe siècle (17 000 à cette époque contre 6 000 aujourd’hui).
DO : Ton travail consiste à faire de la géohistoire à l’échelle mondiale comme le prouvent les titres de la plupart de tes livres. Mais il est bien sûr possible de faire de la géohistoire à une autre échelle, par exemple nationale ou locale.
CG : C’est vrai qu’aujourd’hui, en France, la géohistoire est rangée dans la catégorie de l’histoire globale. Je pense que la première est particulièrement bien adaptée à la seconde. Mais le problème de distance entre les différents acteurs sociaux est le même à toutes les échelles. Par exemple, c’est ce que j’ai essayé de faire avec l’Atlas historique de la France (Les Arènes-L’Histoire, 2019).
DO : On te questionne souvent sur ton utilisation de l’histoire contrefactuelle qu’on appelle aussi l’histoire des possibles. Peux-tu rappeler ce qu’est ce type d’histoire et pourquoi tu y as recours quelquefois ?
CG : L’uchronie raisonnée est une démarche expérimentale dans un processus temporel, elle aide à la réflexion et notamment permet de relativiser. Par exemple, si le monde avait été tissé par les Polynésiens, le monde aurait été totalement différent de ce qu’il est devenu à partir du XVIe siècle, lorsque les Européens ont influencé considérablement les interrelations entre les sociétés humaines.
DO : Abordons maintenant l’histoire des humains sur la Terre avec la préhistoire, plus précisément le paléolithique, avant donc la révolution néolithique. C’est le moment où l’animal humain sort de la savane arborée pour migrer vers des environnements très divers. Une carte très intéressante représente l’aire de diffusion des homo erectus, elle est titrée très pertinemment « sortir de son écosystème : le propre des humains ». Peux-tu expliquer ce titre ?
CG : Il y a actuellement des discussions à propos de la traduction du titre de l’ouvrage (5 traductions en cours). Les Néerlandais ont choisi de titrer le livre en utilisant l’expression De la savane à la ville. Ceci pour dire que ce qui me semble caractériser l’espèce humaine par rapport à tous les autres primates, c’est son ubiquité : il y a des humains partout. Ce processus a commencé il y a 2 millions d’années quand homo erectus est sorti d’Afrique ; les différentes espèces humaines ont su vivre dans des milieux qui n’étaient pas biologiquement le leur grâce à la maîtrise du feu, à la maîtrise du vêtement, à la construction de logements complexes, donc grâce à leur capacité à produire des micro-milieux. C’est vrai pour Sapiens depuis 300 000 ans.
Ce qui est à l’origine d’une part, de l’unité de l’espèce, et d’autre part, du fractionnement en de multiples sociétés (diversité des langues, des modes de vie, etc.)
DO : Sapiens vit donc dans tous les milieux. On peut parler de diffusion-dispersion avec pour corollaire le fractionnement en sociétés sans contact. A cet endroit du livre, tu cites la controverse de Valladolid et La Planète des singes de l’écrivain Pierre Boulle. Pourquoi cela ?
CG : Selon l’Eglise, ce qui prouvait l’humanité des populations autochtones rencontrées lors des « Grandes Découvertes » c’était l’interfécondité entre ces populations et les Européens. Quant au livre La planète des singes, il montre à sa manière comment le romancier Pierre Boulle s’est emparé de la question d’une commune espèce humaine.
DO : Evoquons maintenant l’avènement du Néolithique qui se caractérise par la domestication du vivant (végétaux et animaux) et la sédentarisation des populations. Au lieu du néolithique tu préfères parler des néolithiques, sans doute à cause de la dispersion des foyers de néolithisation dans le monde. Comment peut-on expliquer la simultanéité relative de cette dispersion ?
CG : Effectivement, les premières domestications sont apparues dans plusieurs foyers très dispersés sur la terre (Proche-Orient, Chine, Asie méridionale, Afrique occidentale, etc.) mais dans une fourchette de temps assez réduite. Pourquoi ces foyers indépendants de domestication ? Une première explication : l’absence de communications avérées. Une autre cause : la très forte coïncidence chronologique a empêché le déploiement d’un processus de diffusion. Il faut donc admettre le polygénisme des sociétés agricoles.
DO : Qu’en est-il des conséquences de la synchronie hétérogène au niveau des domestications (« le lama et la vache ») ?
CG : Les deux grands ensembles géographiques de plantes et d’animaux domestiqués (l’Eufrasie et l’Amérique) diffèrent par les potentialités préalables de domestication. Il semble bien s’agir d’une question d’offre. Le déséquilibre est flagrant dans le domaine animal. L’Amérique ne disposait d’aucun gros mammifère domesticable comme le cheval ou le dromadaire. Cela a eu des conséquences pour l’alimentation, le transport, le travail et même l’art militaire.
DO : Un chapitre passionnant traite des dernières diffusions spatiales, notamment en Amérique et en Océanie. La science archéologique progresse au point de donner aujourd’hui une profondeur historique à des espaces tels que les grandes plaines centrales d’Amérique du Nord et l’Amazonie. Prenons l’exemple de cette dernière qui illustre parfaitement ce qu’on appelle les « peuples sans histoire ». Que sait-on de nos jours de l’histoire de l’Amazonie ?
CG : Des régions entières n’ont entretenu que des liens rares et distendus avec l’axe de l’Ancien Monde. Certaines sociétés ont tout de même été partiellement reliées à cet axe comme celles du littoral de l’est africain. D’autres sociétés étaient entièrement coupées de cet axe comme les sociétés amérindiennes qui ont vécu indépendamment de l’histoire de l’Eufrasie et qui de ce fait ont eu une histoire de pandémies tout à fait particulière.
Grâce aux progrès de l’archéologie, deux grandes régions ont acquis une profondeur historique à peine perçue jusqu’à la seconde moitié du XXe siècle : les grandes plaines centrales d’Amérique septentrionale et l’Amazonie.
DO : La carte « L’Axe de l’Eufrasie au début de notre ère » montre un monde connecté de la Chine à Rome en l’an 200. Depuis le Néolithique, une zone de forte densité humaine (au moins les deux tiers de l’humanité) s’est structurée des mers de Chine à la Méditerranée. Au IIe siècle, elle est organisée autour de grands empires. Ceux-ci font face, au nord, aux peuples des steppes, éleveurs et caravaniers. Plus au sud se trouvent des ensembles plus petits. C’est une « première mondialisation » avec les routes de la soie et celles des épices maritimes. Peux-tu développer ce que tu appelles « l’origine axiale du Monde ».
CG : Depuis plusieurs milliers d’années, entre Chine et Méditerranée, l’axe de l’Ancien Monde regroupe approximativement les trois quarts de l’humanité. Là, les sociétés sont nécessairement interconnectées puisque voisines ; quand une société a une innovation, celle-ci va se répandre chez les autres. Il y a d’ailleurs toutes sortes de passages : des mers littorales, des axes fluviaux, des steppes qui vont être peuplées par des peuples faisant le choix de l’élevage. Se sont donc développées des sociétés très différenciées : au sud, des sociétés « à racines » (des cultivateurs) ; au nord, des sociétés « à pattes » (des pasteurs).
DO : Abordons maintenant « la bifurcation du Monde » avec les « Grandes Découvertes » et l’Europe qui devient le centre du Monde. Pourquoi le succès de l’Europe (des hasards et des envies) ?
CG : La connexion avec les sociétés autres que celles de l’axe de l’Ancien Monde ne pouvait a priori être faite que par une société de l’Ancien Monde. Ensuite pourquoi les Européens ? La situation d’extrême occident de l’Europe pouvait inciter ses sociétés à l’aventure maritime. Madère et les Açores furent les premières îles à sucre des Européens qui n’eurent plus qu’à déplacer vers l’ouest au XVIe siècle le complexe socio-économique de la plantation.
DO : Et si le Sud avait créé le Nord ?
CG : Une petite uchronie radicale. Imaginons un rapport Nord-Sud inversé avec des sociétés tropicales qui auraient eu envie de produits tels que le lait ou la viande produits sur des terres avec hivers. Tout ceci pour dire que la péjoration du Sud n’est pas un phénomène naturel.
DO : Pour terminer, quels sont les principaux aspects géohistoriques du XXe siècle et du début du XXIe siècle ? Peut-on distinguer ceux qui se situent dans la continuité du siècle précédent et ceux qui sont en rupture avec lui ? Il me semble que le tableau de notre monde actuel met en jeu trois données fondamentales : une interdépendance accrue, les fractures profondes entre les sociétés, la gestion indispensable de la planète.
CG : Commençons par une mutation fondamentale : la croissance démographique avec un milliard d’habitants sur la Terre en 1800 et plus de 8 milliards aujourd’hui. Les humains sont devenus une espèce invasive qui détruit la mince pellicule de vie végétale et animale. Rien qu’à cause de cela, toutes les sociétés sont interconnectées. La question centrale c’est comment affronter ensemble, avec des sociétés si différentes, ce problème de gestion de notre unique bien commun qui est cette pellicule de vie. Aujourd’hui, on est à la fois dans une urgence d’agir en commun et de prendre en compte la diversité liée souvent à l’héritage colonial… La réflexion géohistorique traduit la nécessité de comprendre le fractionnement des sociétés et de pouvoir contribuer à essayer de le dépasser.
Un deuxième élément de réponse réside dans les rejeux d’héritages. Dans la diversité des sociétés on a des types de configurations sociales qui se sont construites en position les unes par rapport aux autres. Le planisphère politique est un puzzle, celui des Etats-nations. Parmi les plus grandes pièces du puzzle se trouvent en particulier les Etats héritiers des anciens empires de l’Axe (Chine et Russie). Parmi les plus petites pièces du puzzle, il y a de nombreux supports à des activités qui se jouent de l’international (paradis fiscaux, narcotrafic, etc.). Au total, on a un certain nombre d’éléments qui nous posent d’énormes problèmes pour pouvoir organiser ensemble la gestion de notre Planète.
Questions de la salle :
Q1 : Peut-on imaginer l’évolution du monde si Néandertal l’avait emporté ?
CG : Le Musée de l’homme a organisé récemment une exposition sur Néandertal. Celle-ci montre que Néandertal a changé de statut. Il y a 30 ans on le représentait comme une brute épaisse, contrairement à l’Homo Sapiens, qui lui apparaissant comme un civilisé (en devenir). Cela traduisait une vision du monde, celle qui opposait le sauvage à l’homme civilisé (c’est-à-dire l’Européen). Aujourd’hui, une parfaite inversion oppose Néandertal, le « gentil écolo », à Sapiens « qui recherchait le profit et avait tous les défauts ». En fait, on apprendra peut-être que Sapiens avait quelques avantages (sur les possibilités langagières ?) par rapport à Néandertal. Des processus historiques très différents n’auraient sans doute pas existé si Néandertal l’avait emporté.
Q2 : L’Europe affectée à la fin du Moyen Age par le « précapitalisme » a-t-elle bénéficié de ces conditions pour impulser à son profit la mondialisation amorcée par les « Grandes Découvertes » ?
CG : Là, vous posez la question des configurations sociales internes des sociétés. Ma réflexion géohistorique a fait le choix de s’intéresser avant tout aux logiques externes, c’est-à-dire essentiellement aux interrelations entre les sociétés (connexion, pas connexion, hiérarchie ou égalité dans les connexions, etc.). Ce qui se passe à l’intérieur des sociétés n’a pas été un élément important de ma réflexion mais mon livre donne les éléments de contextualisation qui peuvent permettre ensuite de s’intéresser aux structures internes (chinoises, indiennes, ottomanes, etc.) qui sont des éléments importants.
Q3 : Et si Napoléon n’avait pas vendu la Louisiane ?
CG : La Louisiane est très largement un mythe. Au XVIIIe siècle, la Louisiane française (la Nouvelle-France) forme un vaste espace entre le Saint-Laurent et le delta du Mississipi, peuplé (modestement) de colons, l’essentiel étant constitué de territoires où une poignés de Français et de « coureurs des bois » s’adonnent au commerce avec les nations amérindiennes. La configuration géopolitique principale dans le sud des Grandes Plaines était la Comancheria (l’empire comanche, qu’on peut qualifier d’« empire cavalier »), qui avait une réalité plus importante que la Nouvelle-France des chancelleries. Napoléon qui n’avait pas la maîtrise des mers a préféré vendre la Louisiane qu’il n’avait pas la possibilité de contrôler, ni de développer.
Compte rendu rédigé par Daniel Oster, décembre 2024
-
sur Géopolitique de l’Ouzbékistan dans une Asie centrale très convoitée
Publié: 28 December 2024, 11:58am CET par r.a.
C’est au retour d’un voyage en Ouzbékistan que Maryse Verfaillie retrace le rôle qu’a eu ce pays au cœur de l’Asie pendant plus de deux millénaires d’histoire.
-
sur LMFP : LE catalogue magique !
Publié: 24 December 2024, 2:00pm CET
 Une extension QGIS peut-être (trop) méconnue : Layers Menu From Project permet de simplifier la vie des administrateurs ET des utilisateurs, retour d'expérience à deux voix.
Une extension QGIS peut-être (trop) méconnue : Layers Menu From Project permet de simplifier la vie des administrateurs ET des utilisateurs, retour d'expérience à deux voix.
-
sur 2024 chez Geomatys
Publié: 23 December 2024, 11:23am CET par Jordan Serviere
 2024 chez Geomatys
2024 chez Geomatys
- 23/12/2024
- Jordan Serviere
Alors que 2024 s’achève, Geomatys se distingue une fois de plus comme un acteur clé dans le domaine de l’information géospatiale, des systèmes d’information environnementale et de la défense. Cette année a été marquée par des avancées technologiques concrètes, des reconnaissances importantes et des collaborations stratégiques qui ont renforcé notre position dans des secteurs en constante évolution. Retour sur ces douze mois faits de projets ambitieux et de réalisations collectives.
Examind C2 : réinvention de la gestion tactiqueLe lancement d’Examind C2 représente une étape cruciale en 2024, tant pour Geomatys que pour les secteurs de la défense, de la cybersécurité et de la gestion de crise. Cette plateforme de Commande et Contrôle (C2), conçue pour répondre aux besoins complexes des environnements multi-milieux et multi-champs, se distingue par son interopérabilité avancée et son traitement en quasi-temps réel. Les visualisations dynamiques qu’elle propose offrent une supériorité informationnelle essentielle pour optimiser les prises de décision dans des situations critiques. Avec des capacités étendues en traitement de données spatiales, Examind C2 anticipe également les attentes futures des utilisateurs. Pour une analyse approfondie de ses capacités et de ses cas d’utilisation, rendez-vous sur le site officiel.
AQUALIT : vers une gestion durable de l’eau potableEn 2024, Geomatys a franchi une nouvelle étape avec la commercialisation d’AQUALIT, une plateforme novatrice destinée à l’analyse des mesures d’eau. Conçue spécifiquement pour les producteurs d’eau potable, AQUALIT leur fournit des outils puissants pour surveiller, analyser et optimiser la qualité de leurs ressources. Cette solution intègre des fonctionnalités avancées en gestion des données hydrologiques, en analyse prédictive et en visualisation cartographique. Dans un contexte où la gestion durable de l’eau est devenue un enjeu prioritaire, AQUALIT illustre parfaitement l’engagement de Geomatys en faveur de l’environnement et de l’innovation. Pour en savoir plus et découvrir toutes ses fonctionnalités, consultez le site d’AQUALIT.
OPAT devient ShoreInt : une évolution pour mieux répondre aux besoins côtiersEn 2024, notre projet OPAT a connu une évolution majeure en devenant ShoreInt. Cette transition reflète notre désir d’offrir une solution toujours plus adaptée aux enjeux complexes de la gestion des zones côtières. ShoreInt intègre des données issues de technologies comme l’AIS, les images satellites et la modélisation spatiale pour fournir une analyse précise des activités maritimes et des dynamiques environnementales. Avec une interface ergonomique et des outils avancés de visualisation, ShoreInt est conçu pour aider les décisionnaires à gérer les interactions complexes entre les activités humaines et les écosystèmes côtiers. Pour en savoir plus sur cette solution innovante, consultez le site de ShoreInt.
Lauréat du Concours d’innovation avec EpiwiseUn des temps forts de 2024 est sans conteste la distinction obtenue par Geomatys pour son projet Epiwise lors des Concours d’innovation de l’État. Soutenu par France 2030, ce projet épidémiologique figure parmi les 177 initiatives lauréates reconnues pour leur potentiel à transformer durablement leur secteur. Cette récompense reflète notre capacité à innover tout en répondant à des besoins sociétaux majeurs, tels que la prévention des pandémies et la modélisation épidémiologique. En s’appuyant sur des technologies de machine learning et de traitement des big data, Epiwise offre des perspectives nouvelles pour la santé publique.
Collaboration et continuité : une stratégie collectiveAu-delà de ces projets phares, Geomatys a maintenu en 2024 un rythme soutenu de collaboration dans des initiatives d’envergure. Parmi elles, FairEase, le portail Géosud et nos partenariats stratégiques avec Mercator Ocean et l’Office Français de la Biodiversité. Ces travaux, axés sur la valorisation des données spatiales, l’interopérabilité et la gestion des ressources naturelles, témoignent de notre engagement à développer des solutions ouvertes, accessibles et adaptées aux enjeux environnementaux contemporains. Ces projets, loin de s’arrêter en 2024, constituent un socle solide pour notre développement en 2025 et au-delà.
Et en 2025...Alors que nous nous tournons vers 2025, Geomatys se prépare à renforcer son impact et à ouvrir de nouvelles perspectives. En poursuivant nos investissements dans la recherche et le développement, notamment en télédétection, modélisation environnementale et gestion des données massives, nous ambitionnons de créer des solutions toujours plus performantes et adaptées aux besoins d’un monde en mutation rapide. L’année à venir sera marquée par le renforcement de nos relations avec nos partenaires stratégiques, dans une perspective de collaboration continue et durable. Nous adressons nos sincères remerciements à nos collaborateurs, dont l’engagement et les compétences sont le moteur de nos réussites, ainsi qu’à nos clients et partenaires pour leur soutien indéfectible. Ensemble, faisons de 2025 une année riche en projets et accomplissements. Toute l’équipe vous souhaite de très belles fêtes de fin d’année. Rendez-vous en 2025 !
Menu Linkedin
Twitter
Youtube
Linkedin
Twitter
Youtube

The post 2024 chez Geomatys first appeared on Geomatys.
 EN
EN-
sur Appel à participants - GT Dessertes pour les transports de bois
Publié: 20 December 2024, 11:50am CET
Appel à participants - GT Dessertes pour les transports de bois
-
sur « TERRES ». Dossier spécial FIG 2024 de la revue La Géographie (n°1594, automne 2024)
Publié: 19 December 2024, 7:01pm CET par r.a.

Ce dossier s’intéresse aux « Terres », thème du Festival international de géographie de Saint-Dié en octobre 2024.
Parmi les articles, nous retrouvons ceux d’amis des Cafés géographiques comme Amaury Lorin et Gilles Fumey. Le premier nous avait fait le plaisir de traiter au Café de Flore le sujet évoqué ici, La Birmanie : pivot stratégique entre l’Inde et la Chine, en février dernier ( [https:]] ). Le second alerte sur le vol des terres à leurs premiers habitants dans Terres convoitées, terres accaparées. Le phénomène remonte à l’Antiquité mais prend au XXIe siècle la forme d’un accaparement dû à quelques Etats mais surtout aux firmes de pays riches dans un but financier. En France, seuls quelques vignobles de prestige sont aux mains de sociétés étrangères mais la financiarisation du foncier est défavorable à l’installation des jeunes agriculteurs. Grands acheteurs de terres dans les pays en développement, surtout en Afrique subsaharienne, la Chine et les pays du Golfe invoquent leur souci d’assurer la sécurité alimentaire à leurs populations. En fait beaucoup d’investissements fonciers servent à produire des agrocarburants. Seules des ONG cherchent à lutter contre ces spoliations, parfois avec succès.
François-Michel Le Tourneau explique quels enjeux fonciers se cachent derrière la déforestation de l’Amazonie. Il rappelle d’abord que si la baisse de la déforestation en Amazonie a été notable en 2023 (elle a dépassé 30% par rapport à 2022), ce qui a donné une image positive au gouvernement de Lula, la hausse a été très importante dans les savanes du Centre (« cerrado »). Il s’est donc agi d’un choix essentiellement politique. L’objectif d’une déforestation zéro semble impossible à atteindre car la déforestation peut être légale. Une partie du patrimoine public forestier est devenu privé au profit de ceux qui occupaient ces terres depuis plus de 10 ans. En ont profité les petits propriétaires puis les grands. La délivrance des titres de propriété est néanmoins conditionnée à la mise en valeur des terres, ce qui favorise la déforestation, souvent au profit de l’élevage bovin.
C’est à l’échelle mondiale que Paul Arnould pose la question du statut foncier de la forêt. Ce n’est pas une question marginale car la forêt occupe le tiers des terres émergées. Sur le plan juridique, le bilan est simple : 76% de la terre forestière appartiennent à un Etat, 20% à des propriétaires privés (en général, de grands groupes multinationaux, à l’exception de la France où la propriété est très émiettée), 4% n’ont pas de propriétaires identifiés. Mais en dehors du droit, les situations sur le terrain sont plus complexes. Des droits d’usage anciens sont fortement revendiqués par leurs bénéficiaires, sans être reconnus par la loi. Pour beaucoup de randonneurs contemporains, il va de soi que la forêt est un bien public où tout est permis (cueillette des champignons et des baies etc…). Trois impératifs s’opposent : rationalité économique, situation écologique, réalités sociales. Les situations des terres forestières sont donc très diverses selon les lieux.
Forêts et autres lieux ont été nommés par les hommes qui inscrivent ainsi leur pouvoir dans les paysages. Camille Escudé s’est particulièrement intéressée au « renaming » (pour « changement de nom ») des territoires autochtones. Une des formes du pouvoir colonial a consisté à supprimer les noms donnés par les autochtones aux lieux pour les rebaptiser. Ainsi Chuquiago Marka (« vallée de l’or ») en Amérique du sud est devenue Nuestra Senora de la Paz après la conquête espagnole de 1548. Supprimer aujourd’hui ces noms donnés par le colonisateur fait partie des pratiques de décolonisation et de résistance au pouvoir dominant. Le territoire autonome du Nunavut au Canada, administré par les Inuit, en donne de nombreux exemples. Frobisher Bay (nom d’un explorateur britannique) s’appelle aujourd’hui Iqaluit (« les poissons » en inuktitut).
C’est donc la diversité des approches qui fait tout l’intérêt de cette revue consacrée à un sujet fondamentalement géographique : les terres.
Michèle Vignaux, décembre 2024
-
sur [Equipe Oslandia] Sophie Aubier, développeuse SIG
Publié: 19 December 2024, 7:25am CET par Caroline Chanlon

Après le BAC, le rêve de Sophie, c’est de tailler des pierres précieuses. Elle effectue un stage chez un artisan parisien où elle se rend vite compte que c’est un travail précaire qui est soumis à des règles qui ne lui conviennent pas.
Elle décide d’en apprendre plus sur la formation des roches et s’oriente vers une Licence de Géosciences à Paris Sorbonne puis un master de Physique de l’Océan, de l’Atmosphère et du Climat qu’elle complète avec un Master d’Hydrogéologie à Paris Saclay pour « plus de pratique et moins de théorie ».« Je me suis intéressée à la géologie pour finalement plus me passionner pour le calcaire que pour les pierres précieuses ! »
Pendant ses études, Sophie réalise plusieurs stages pendant lesquels elle mobilise les grands modèles utilisés par le GIEC pour les prédictions afin de réaliser des modélisations du climat.
« J’ai beaucoup utilisé Python dans mes stages et c’est ce qui me plaisait. J’avais envie d’apprendre encore sur le code, résoudre des problèmes scientifiques avec du code informatique. »
Sophie postule à une offre d’emploi chez Oslandia à un poste de développeur SIG junior. Elle est embauchée en janvier 2022 pour notamment développer des plugins QGIS en Python.
Projets emblématiques- Développement du plugin Cityforge : intégration de bâtiments 3D dans QGIS. Un plugin réalisé dans le cadre de la R&D Oslandia.
- Développement du plugin ELAN pour INRAE : un plugin d’outils de gestion des eaux urbaines.
« C’est un outil d’aide à la décision pour le traitement des eaux usées, le déversement des eaux de pluie et des eaux usées «
Python
PhilosophieApprendre !
Oslandia en 1 motAutonomie
-
sur Suivre le Vendée Globe 2024 depuis un SIG - Partie 2
Publié: 18 December 2024, 2:00pm CET
 Après avoir récupéré, nettoyé et visualisé les données SIG du Vendée Globe 2024 dans QGIS, voyons comment automatiser tout cela et développer une application application Web de suivi avec MapLibre.
Après avoir récupéré, nettoyé et visualisé les données SIG du Vendée Globe 2024 dans QGIS, voyons comment automatiser tout cela et développer une application application Web de suivi avec MapLibre.
-
sur Regard d'Altitude : recenser les effets du changement climatique sur les milieux alpins
Publié: 18 December 2024, 9:30am CET par Bastien Potiron
Dans un contexte de perte de connaissance territoriale et d’accroissement du dérèglement climatique affectant particulièrement les milieux montagneux, le projet Regard d’Altitude vise à structurer et centraliser de manière collaborative les observations des phénomènes naturels se produisant.
-
sur Petite histoire du logo Oslandia
Publié: 18 December 2024, 7:18am CET par Caroline Chanlon

Fin 2009, Oslandia est sur le point d’être créée… et a besoin d’une identité visuelle. Vincent contacte son ancien collègue Sylvain pour travailler sur un logo.
Le cahier des charges est lancé !Le logo doit être identifiable immédiatement, le plus simple possible (“ça va ensemble” dixit Sylvain), déclinable au trait (N&B), niveau de gris, quadrichromie, 256 couleurs et couleurs pleines. Il faut aussi qu’il soit symbole de dynamisme, avec une symbolique rattachée au métier, et ne ressemblant à rien de connu !
La première série d’idées ne se fait pas attendre, voilà quelques logos proposés :
Les partages d’idées se font via des emails et sont centralisés sur un wiki. Les premiers échanges débutent ! Et une série de modifications qui donne lieu à une nouvelle itération.
On avance !
Pour s’approcher d’une version finale
Qui ne tarde pas à arriver !
Retour d’expérience de Sylvain
« J’ai exclusivement travaillé avec Inkscape, toujours en vectoriel et uniquement à la souris. Sur ce type d’exercice, je n’ai pas besoin de crayon pour élaborer des ébauches, je pars souvent d’une forme géométrique simple ou d’un texte. Je me suis basé sur mon intuition pour les premières séries et les itérations m’ont permis d’avancer pas à pas. «
Au final, le logo Oslandia représente une sorte d’intersection spatiale entre des courbes de niveau ( une île ? ) et un rectangle, qui fait le lien avec le nom de l’entreprise.
Certains y voient cependant plutôt des attracteurs étranges, ce qui in fine pourrait aussi nous caractériser !
Le logo s’est construit à l’image d’Oslandia : de manière collaborative, démocratique, par itération et tout cela dans un soucis d’excellence et de travail bien fait
Depuis, le logo a évolué pour aboutir à la version actuelle. Cette nouvelle version, largement inspirée de la précédente, est simplifiée et modernisée. Elle est toujours facile à intégrer sur des pages web, des affiches ou des documents, et elle corrige le bug de la version précédente : un affichage possible au format carré !

-
sur Qu’est-devenue la Yougoslavie ? Avec Jean-Arnault Dérens et Laurent Geslin
Publié: 17 December 2024, 8:28pm CET par r.a.

De gauche à droite, Jean-Arnault Dérens, Laurent Geslin et Daniel Oster, mardi 26 novembre 2024, au Café de la Mairie (Paris 3ème) (Photo Denis Wolff)
La salle du premier étage du Café de la Mairie (Paris 3ème) était comble mardi soir 26 novembre pour écouter deux éminents spécialistes des Balkans, Jean-Arnault Dérens (JAD) et Laurent Geslin (LG). Les intervenants, tous deux journalistes, notamment au Courrier des Balkans et pour de nombreux organes de presse (Le Monde diplomatique, Mediapart, etc.), auteurs de plusieurs livres sur la région des Balkans, étaient présents pour faire le point sur la situation de l’espace ex-yougoslave, trente ans après la dislocation de la Yougoslavie socialiste de Tito.
J-A.D. : D’où vient l’idée yougoslave, c’est-à-dire l’idée de réunir tous les Slaves du Sud dans un même Etat ?
Cette idée apparaît au XIXème siècle, dans les années 1860, portée par des intellectuels croates, vivant donc dans l’Empire des Habsbourg. Elle est contemporaine du mouvement des nationalités qui se développe alors en Europe, notamment dans les Etats italiens et germaniques. Dès 1850, une base grammaticale commune a été fixée par une convention pour le serbo-croate, langue commune de ces populations slaves du Sud. Malgré leurs différences historiques et confessionnelles, ces populations formaient donc un ensemble ayant toute légitimité à se regrouper au même titre que les populations italiennes ou allemandes par exemple. Les guerres balkaniques de 1912-1913 et la Grande guerre de 1914-1918 favorisent la formation en 1918 d’un Royaume des Serbes, des Croates et des Slovènes qui prend le nom de royaume de Yougoslavie en 1929. Cet Etat est en réalité une construction politique grand-serbe qui nie tous les rêves d’unification de ces peuples slaves du Sud.La Seconde Guerre mondiale provoque la naissance d’une « seconde Yougoslavie », fédérative et socialiste, proclamée le 29 novembre 1943, qui va durer 45 ans avec une représentation assez équilibrée de toutes les nationalités (6 républiques, 2 républiques autonomes, soit le modèle de l’organisation étatique de l’URSS). Cette Yougoslavie « titiste » (Tito la dirige de 1943 à 1980, date de sa mort) s’effondre pour des raisons externes et internes. Sur le plan extérieur, elle perd son importance géopolitique de « pont » entre les deux parties du monde bipolaire de la guerre froide, elle est en quelque sorte la principale victime collatérale de la chute du mur de Berlin. Sur le plan intérieur, elle a évolué vers une sorte de confédéralisme marqué par des tensions accrues entre les républiques, principalement de nature économique. Les républiques les plus riches (la Slovénie grâce à son industrie, la Croatie grâce au tourisme) ne supportent plus de verser beaucoup d’argent en direction des républiques les plus pauvres (phénomène comparable entre le Nord et le Sud en Italie).
L’éclatement tragique de la Yougoslavie dans les années 1990 se fait dans la guerre. Aujourd’hui, le souvenir de la Yougoslavie reste bien présent dans les pays qui en sont issus. Face aux crises à répétition que traverse l’espace post-yougoslave, nombreux sont ceux qui regrettent « ce passé où l’on vivait mieux ». C’est la « yougonostalgie ».
A l’issue des guerres yougoslaves, les nouveaux Etats créés à partir des anciennes républiques étaient tous supposés rejoindre l’Union européenne. Ce qui est le cas pour la Slovénie en 2004 et finalement pour la Croatie en 2023. Mais constatons qu’il n’en est rien pour tous les autres Etats qui sont toujours candidats pour entrer dans l’UE (et même « candidat potentiel » pour le Kosovo). L’absence de frontières cadastrées en Serbie, en Bosnie-Herzégovine et au Monténégro facilite dans les années dans les années 2010 d’ailleurs les contentieux interétatiques même si l’émergence d’une « yougosphère » émerge dans les années 2010 avec les incertitudes de l’intégration européenne et la prise en compte de similitudes, notamment culturelles, dans tout l’espace autrefois yougoslave.
L.G. : Où en est-on aujourd’hui ?
Depuis 20 ans, l’espace post-yougoslave fait l’objet d’un double discours : d’un côté, l’UE et les dirigeants régionaux rappellent l’objectif d’entrée dans l’UE ; d’un autre côté, l’UE comme les dirigeants des Balkans occidentaux se satisfont de la situation politique actuelle. Plusieurs raisons à cela. Pour l’UE les Balkans occidentaux représentent, surtout depuis 2010, un sas sur la route migratoire qui aboutit à l’Europe occidentale. Ce sas permet de freiner et de contrôler les flux migratoires, des camps de rétention sont installés, des subsides sont versés aux pays de transit. Les Balkans forment ainsi une barrière et jouent un rôle d’amortisseur à la migration.Il y a également des raisons d’ordre démographique au maintien du statu quo politique entre l’UE et les Balkans occidentaux. Malgré les difficultés actuelles, ceux-ci ont des populations bien formées grâce à des systèmes éducatifs qui restent de bonne qualité. Les pays d’Europe occidentale, en particulier l’Allemagne, considèrent le Sud-Est de l’Europe comme un réservoir de main d’œuvre, très qualifiée (médecins…) et peu qualifiée (boulangers, plombiers…). Ces départs d’actifs aggravent la situation démographique marquée par un déficit des naissances accentué, déficit qui existe d’ailleurs dans une grande partie du continent européen.
Un autre fait constitue un grand problème pour les populations des Etats ex-yougoslaves, celui des lacunes récurrentes de l’état de droit. Ce phénomène est largement ignoré par les dirigeants de l’UE. Les manipulations électorales, la corruption, sont monnaie courante dans les Balkans occidentaux. On comprend que certains dirigeants des Etats de la région ne souhaitent pas forcément l’adhésion à l’UE qui signifierait le strict respect des règles de l’état de droit.
Tout ceci sans compter deux points de blocage qui empêchent l’intégration européenne d’avancer : en Bosnie-Herzégovine (entre Croates et Bosniaques) et au Kosovo (non reconnu par 5 Etas de l’UE). Ajoutons la guerre en Ukraine depuis 2022 qui a rebattu les cartes géopolitiques avec, par exemple, la décision de la Serbie de ne pas soutenir les sanctions de l’UE prises contre la Russie. Une majorité des Etats de l’UE vient de décider que l’élargissement européen n’était pas encore opportun.
J-A.D. : Quel est le rôle des puissances comme la Chine, la Turquie et le Moyen-Orient dans l’espace autrefois yougoslave ?
Au début du XXème siècle, la situation dans les Balkans montrait les rapports complexes entre les petits Etats balkaniques et les grandes puissances de l’époque, soucieux de jouer des rapports de force afin de renforcer leurs intérêts respectifs. Aujourd’hui, il en va de même avec les petits Etats anciennement yougoslaves qui exploitent la concurrence, notamment entre les Occidentaux et les Chinois ou les Turcs. Dans le même temps, les grandes puissances investissent dans la région pour pousser leurs pions économiques et/ou géopolitiques.Alors que l’UE apparaît comme le principal acteur extérieur depuis la crise de 2008, de nouveaux acteurs jouent un rôle important dans cette partie de l’Europe : avant tout la Turquie, la Russie, la Chine, les pays du Golfe arabo-persique. Au point que des questions se posent aujourd’hui avec plus ou moins de pertinence : la Turquie est-elle de retour dans les Balkans ? La Serbie est-elle le cheval de Troie dans la région ? La Chine est-elle en train d’acheter les Balkans ? Pourquoi les pays du Golfe investissent-ils dans cet espace européen ?
Depuis l’arrivée au pouvoir d’Erdogan et de l’AKP, les investissements turcs se sont généralisés dans les pays post-ottomans mais différents facteurs internes et externes ont modifié les priorités d’Ankara, mobilisée sur d’autres fronts. Et aujourd’hui la Turquie mise davantage sur la Serbie que sur la Bosnie-Herzégovine ou l’Albanie.
Les intérêts économiques de la Russie sont relativement modestes dans les Balkans, mais la région occupe une place symbolique importante dans les préoccupations du Kremlin. Si la Serbie n’a pas adopté les sanctions européennes contre la Russie après l’invasion de l’Ukraine, elle s’oppose en revanche à l’effondrement de l’intégrité territoriale de tout Etat membre de l’ONU (sans doute en pensant au cas du Kosovo).
Ce n’est que depuis la fin des années 2000 que les Balkans sont devenus une cible importante de la projection de la Chine à l’étranger (lancement en 2013 de la « Nouvelle route de la soie » entre Pékin et l’Union européenne). Plusieurs chantiers chinois ont été réalisés en Serbie et au Monténégro, particulièrement dans les infrastructures de transports, les minerais et l’éolien.
Quant aux pays du Golfe (Arabie saoudite et Emirats arabes unis, leurs investissements privilégient le tourisme, l’immobilier et l’armement, notamment en Serbie.
L.G. : Qu’en est-il de l’évolution de certaines régions comme la Dalmatie croate ou d’espaces particuliers comme les îles ?
La Dalmatie a connu un important essor du tourisme dès les années 1970-1980. Elle profite largement de la reprise touristique depuis la fin de la guerre civile à la fin des années 1990 au moment même où la transition économique post-communiste provoque la désindustrialisation de la côte adriatique (disparition des chantiers navals, etc.). Les méfaits du surtourisme sont aggravés par le manque de main d’œuvre régionale (Indonésiens, Philippins et d’autres nationalités sont employés pendant la saison touristique). Avec Airbnb c’est une société à deux vitesses qui se développe en bénéficiant aux propriétaires de maisons et d’appartements pouvant être loués tandis que le reste des populations locales subit surtout les prix élevés à Split, Zadar, etc. Les îles de la mer Adriatique sont particulièrement affectées par les difficultés et la déprise démographique.QUESTIONS DE LA SALLE :
Q1 : Pourquoi les Etats anciennement yougoslaves ne connaissent-ils pas des mobilisations populaires comme celles qui ont existé (Ukraine) ou qui existent (Géorgie) ?
Les mobilisations populaires existent dans les Balkans occidentaux, notamment en Serbie et au Monténégro, mais elles ne brandissent plus les drapeaux européens contrairement à ce qu’elles faisaient il y a 15 ans. Les raisons de ces manifestations peuvent être d’ordre écologique (par exemple, contre l’ouverture de mines de lithium en Serbie), ou dénoncer la corruption (par exemple, à la suite de l’accident mortel lié à un effondrement en gare de Novi Sad en novembre 2024). Sur tous ces problèmes les ambassades européennes se taisent, laissant les gouvernements locaux réagir …ou ne pas agir. De plus, le départ massif des actifs vers l’Europe occidentale entame la capacité de réaction de la société civile.Q2 : Comment décrire la situation actuelle au Kosovo ?
Les relations entre la Serbie et le Kosovo sont à la fois intimes, complexes et mauvaises. Pour les Serbes le Kosovo représente le centre historique et religieux de la Serbie au Moyen Age. Mais les albanophones, musulmans pour la plupart, forment aujourd’hui plus de 90% de la population. Pour comprendre cette évolution, il faut remonter à la « grande migration » de 1689. Une grande part de la population chrétienne, notamment serbe, quitte le Kosovo en suivant les armées autrichiennes par crainte de la répression ottomane. Depuis, la balance démographique n’a cessé de peser en faveur des Albanais et au détriment des Serbes. L’exode des Serbes (mais aussi des Roms, voire des Bosniaques) après la guerre de 1998-1999 a renforcé un processus engagé de longue date.Le dialogue entre le Kosovo et la Serbie a-t-il une chance d’aboutir alors que l’indépendance proclamée par le Kosovo en 2008 est toujours contestée par la Serbie. L’UE a pris en 2011 l’initiative d’initier un dialogue « technique » sur les problèmes concrets des citoyens concernés. Constatons que l’existence des Serbes au Kosovo est plus compliquée de jour en jour, ceux-ci d’ailleurs étant utilisés comme des pions par Belgrade.
Q3 : Quel rôle ont joué et jouent encore les différentes religions dans l’espace autrefois yougoslave ?
Rappelons que les guerres de Yougoslavie n’ont pas été des guerres de religion. D’ailleurs la Yougoslavie socialiste a été touchée par une vague profonde de sécularisation. Pendant la guerre civile, les religions orthodoxe, catholique et musulmane ont été utilisées, manipulées par les pouvoirs politiques, comme marqueur identitaire (durant le conflit en Croatie) et surtout comme facteur de légitimation politique. De leur côté, les hiérarchies religieuses ont commis l’erreur de ne pas se distancier assez clairement de cette récupération politique. Encore aujourd’hui, la clé du problème réside moins dans les Eglises que dans la manière dont les pouvoirs utilisent ces Eglises et les communautés confessionnelles. Ajoutons, pour le cas de l’islam, la lutte d’influence entre la Turquie et les pays du Golfe pour le contrôle des communautés islamiques.Q4 : Les Cafés géographiques organisent en mai 2025 un voyage à Trieste et en Istrie (Slovénie et Croatie). Que retenir de ce petit morceau de l’ancienne Yougoslavie, aujourd’hui faisant partie de l’Union européenne ?
Trieste, l’Istrie et la Dalmatie, c’est-à-dire la plus grande partie du rivage oriental de la mer Adriatique, forment une ligne de fracture majeure de l’espace européen. « Rideau de fer », « frontières de sang », frontières fantômes », sont quelques expressions qui ont été utilisées à propos de Trieste et de ce petit morceau de Yougoslavie appartenant aujourd’hui à l’Union européenne. Et les deux intervenants d’évoquer un voyage maritime qu’ils ont fait des Balkans au Caucase à partir de Trieste, voyage qui a donné lieu à la publication d’un beau récit en 2018.ELEMENTS BIBLIOGRAPHIQUES :
Jean-Arnault Dérens et Laurent Geslin, Les Balkans. Carrefour sous influences, Tallandier, 2023
Sous la direction de Jean-Arnault Dérens et Benoît Goffin, Balkans, collection Odyssées, ENS Editions, 2024
Jean-Arnault Dérens et Laurent Geslin, Là où se mêlent les eaux, La Découverte, 2018
Jean-Arnault Dérens, Adriatique. La mer sérénissime, collection L’âme des peuples, Editions Nevicata, 2024Compte rendu rédigé par Daniel Oster, décembre 2024
-
sur ICHC LYON 2024- Compte rendu d’une conférence réussie
Publié: 17 December 2024, 5:23pm CET par Emmanuelle Vagnon

30e Conférence internationale sur l’histoire de la cartographie [ICHC], 1er au 5 juillet 2024- « Confluences – Interdisciplinarité et nouveaux défis dans l’histoire de la cartographie »
30th International Conference on the History of Cartography, 01-05 juillet 2024 – “Confluences – Interdisciplinarity and new Challenges in the History of Cartography”/
ICHC LYON 2024- Un projet collectifLa Conférence internationale sur l’histoire de la cartographie [ICHC] est le seul congrès consacré exclusivement à l’histoire des cartes et de la cartographie dans le monde. Depuis 1964, elle promeut une collaboration libre et sans entraves entre les cartographes de toutes les disciplines, les conservateurs, les collectionneurs, les marchands et les institutions. L’événement est fait de conférences illustrées, de posters, d’expositions et d’un programme social. Afin de mieux faire connaître les enjeux et les ressources, chaque conférence est parrainée par des institutions éducatives et culturelles de premier plan. Les conférences ont lieu tous les deux ans et sont administrées par des organisateurs locaux en collaboration avec Imago Mundi Ltd ( [https:]] ). La première participation française eut lieu en 1987 à Paris. La candidature de Lyon a été proposée et retenue pour 2024, après Amsterdam en 2019 et Bucarest en 2022.
Le comité d’organisation a été piloté par le professeur Bernard Gauthiez et sa collègue Enali De Biaggi, à l’Université Jean Moulin Lyon 3/UMR 5600 EVS (ichc2024@univ-lyon3.fr) et a compté avec la participation de nombreux collègues d’EVS.
Comité d’organisation
Enali De Biaggi (Université Jean Moulin – UMR 5600 EVS)
Bernard Gauthiez (Université Jean Moulin – UMR 5600 EVS)
Catherine Hofmann (BnF Département des cartes et plans)
Emmanuelle Vagnon – Chureau (Université de Paris I CNRS –
UMR 8589 – LAMOP)
Quentin Morcrette (CY Cergy Paris Université)
Claire Cunty (Université Lumière – UMR 5600 EVS)
Axelle Chassagnette (Université Lumière – LARHRA)
Damien Petermann (Université Jean Moulin – UMR 5600
EVS)
Marc Bourgeois (Université Jean Moulin – UMR 5600 EVS)
Virginie Chasles (Université Jean Monnet – UMR 5600 EVS)
Hélène Mathian (École Normale Supérieure CNRS – UMR
5600 EVS)Comité scientifique : Wouter Bracke, Tony Campbell,
Axelle Chassagnette, Imre Demhardt, Bernard Gauthiez, Nick
Millea, Emmanuelle Vagnon-Chureau
Secrétariat et comptabilité : Carla Wehbé
Communication : Emmanuelle Bruyas, Jean-Loup Miquel
Networking : Marine Préault
IT support : Jérémie Fernandes ; English editorial support : Francis HerbertUn grand merci aux étudiants et volontaires qui ont accompagné les invités !
La réalisation de la conférence à Lyon autour du thème : Confluences- Interdisciplinarité et nouveaux défis dans l’histoire de la cartographie visait également à renforcer les liens établis depuis les dernières années entre la communauté académique et les différences instances culturelles et administratives de la ville autour de l’approche cartographique, le tout avec une ouverture internationale. Ainsi, pendant la période allant d’avril à septembre 2024, 5 expositions ont été organisées (voir liste ci-dessous) et toute une série de conférences, visites guidées, master class et ateliers ont eu lieu pour discuter et rendre accessible à un public très large l’histoire de la cartographie, français et anglophone (traduction des cartels des expositions). Les partenaires pour les expositions ont été la Bibliothèque municipale de Lyon, les Archives du département du Rhône et de la métropole de Lyon, les Archives Municipales de Lyon, la Bibliothèque Diderot de Lyon à l’ENS, la Bibliothèque de la Manufacture de l’Université Jean Moulin Lyon 3
La réalisation d’un site web dédié ( [https:]] ) a été prise en charge par les services de l’université de Lyon 3, engagés également dans les services de logistique, sécurité, audiovisuel et accueil en général de l’événementiel. La Bibliothèque nationale de France a aussi été associée, de même que nombreuses autres institutions françaises : l’Université Lumière Lyon 2, le Laboratoire de Recherche Historique Rhône-Alpes LARHRA, le Laboratoire de Médiévistique occidentale de Paris LAMOP, le Comité Français de Cartographie/CFC, CY Cergy Paris Université. La conférence a pu compter sur le mécénat de l’Afigéo – Association française pour l’information géographique, de Business Geografic, CS Carto – Cyrille Suss Cartographe, de l’IGN et de Latitude Cartagène.
ProgrammeSix jours, du lundi 01/07/2024 au vendredi 05/07/2024 :
- 4 Séances plénières, 24 sessions de communications et une séance de posters
- Des vernissages autour d’un programme d’expositions originales le soir.
- 4 ateliers/workshops organisés en parallèle
- Une Map Fair
- Un espace d’exposition partenaires
Quelques thèmes déjà présents dans les conférences antérieures ont particulièrement été proposés :
- Évolution de la cartographie des villes et de leur planification.
- Nouvelles perspectives de la transition numérique.
- Imagerie du monde : cartes et autres images (livres d’art, manuscrits, guides, imprimés…).
- Cartes et environnement.
- Et tous autres aspects de l’histoire de la cartographie ont été abordés, selon les propositions faites par les participants.

Deux cérémonies ont ouvert et clôturé la conférence, dans des lieux prestigieux : le Grand Amphithéâtre de l’Université de Lyon 2 et au Musée des Confluences. Le reste de la semaine a eu lieu dans les locaux de l’IUT Lyon 3 et à l’UdL.
Une grande diversité de participants : Nous nous sommes attachés à donner la voix à différentes sensibilités et regards, respectant avec autant que possible la parité Homme-Femme, une plus grande représentativité des différents pays et régions (32 pour l’édition lyonnaise à partir de 35 pays d’origine des propositions) avec la conviction que nous ne pouvons qu’apprendre de la diversité.


Plus de 300 personnes se sont inscrites pour les différentes journées, dont 115 pour la présentation de communication orales et 20 pour la session de posters. Le recrutement de 8 étudiants.e.s-vacataires a permis de compléter une équipe de 10 personnes ressources. Le retour à un événement présentiel insistait sur l’occasion de renforcer nos liens d’amitié et d’imaginer de nouvelles formes de coopération pour la suite.
Expositions- Représenter le lointain : un regard Européen / Representing the far away: an European perspective (Bibliothèque Municipale de Lyon) – 2 avril – 13 juillet 2024
Représenter le lointain : un regard européen (1450-1950)
Qu’est-ce que le lointain ? Un autre monde, une contrée, un bout de terre ou de mer, un morceau d’univers qu’il est difficile – parfois impossible – d’atteindre et d’appréhender. Sa perception évolue dans le temps, en fonction des modes de vie, des projets politiques, des moyens techniques de celles et ceux qui le saisissent. Nous adopterons un point de vue : le lointain vu d’Europe et par les Européens entre 1450 et 1950 en s’interrogeant sur la dimension critique de ces représentations.
Evènements associés :
- Cartes marines et oeuvres d’art. Les atlas portulans de la Bibliothèque municipale de Lyon (XIVe-XVIIe siècle) – Emmanuelle Vagnon-Chureau, le 21/05/2024 ( [https:]] )
- Les écrivains américains et la cartographie – Julien Nègre, le 11/06/2024 ( [https:]] )
- L’exploration du monde : une autre histoire des Grandes Découvertes – Guillaume Calafat, le 6/06/2024 ( [https:]] )
- Mondes inférieurs et terres célestes : les géographies verticales de la modernité – Jean-Marc Besse, le 13/06/2024 ( [https:]] )
- Éditathon Wikipédia “Représenter le lointain” – le 13 juin 2024
- Le détail et l’ensemble. Cartes et images du territoire rhodanien et lyonnais / The detail and the whole. Maps and images of the Rhône and Lyon area (Archives départementales et Métropolitaines) – 4 avril – 12 juillet 2024
Les Archives départementales et métropolitaines proposent de suivre au fil du temps, la façon dont la représentation de l’espace de ces territoires a évolué. Les cartes doivent répondre à des fonctions différentes, de plus en plus variées et complexes. Certaines demandes s’observent cependant à toutes les périodes, comme lorsqu’il s’agit de valoriser des terres ou de fortifier des places. Lyon occupe naturellement une place à part : les villes ont très tôt fait l’objet de l’attention du politique et du militaire, et les enjeux de cartographie y sont particulièrement importants.
Evènements associés :
- Cartographier Lyon : quelle histoire en comparaison des autres villes ? Bernard Gauthiez et Agnès de Zolt, le 18/04/2024
- La grande histoire des cartes (Les rendez-vous avec l’INA) Film d’Eric Wastiaux, le 15 mai 2024
- La Guillotière depuis 200 ans : du cadastre napoléonien à nos jours – Pierre Chico-Sarro et Guy Milou, le 30 mai 2024
- Documentaires sur la cartographie (Les rendez-vous avec l’INA) : Projection de 3 documentaires : – La carte de France : son histoire (film de Gérard Dolet – 23′ – 1979) – Jeux de cartes (film de Dominique Planche – 25’ – 1990) – Pierre Novat, panoramiste alpin (Alpes Sud – 8’ – 1992), le 5 juin 2024
- Vulnérabilité … qu’en disent les cartes ? / Vulnerability … what do maps say? (Archives Municipales de Lyon) – 3 mai – 28 septembre 2024
La ville de Lyon est vulnérable à des événements variés, soudains ou au cheminement long et indécelable, jusqu’au moment où ils s’imposent et menacent. La plupart d’entre eux n’ont laissé que des mots, bien insuffisants à nous permettre de comprendre ce qui s’est passé, ni comment les hommes composaient avec. Cette histoire est parfois représentée sur des cartes ou par des images qui nous permettent d’en saisir l’ampleur et les particularités. La carte, de ce point de vue, est venue tardivement, accompagnant une vision de plus en plus nourrie scientifiquement. Cette exposition interroge la ville sous l’angle de ses vulnérabilités, au travers de documents rarement vus et encore moins montrés, alors que la ville d’aujourd’hui regorge de dispositifs instaurant la plus grande sécurité.
Evénements associés :
- Risques et territoire : le pari du paysage – CAUE 69, le 16 mai 2024
- Risques et mémoire : un tandem subtil ! – Antoine Le Blanc en partenariat avec la Géothèque, le 30 mai 2024
- À vos cartes – Mapathon/Atelier de cartographe sensible/Découverte des jeux cartographiques – le 1er juin 2024
- Projection & rencontre : Brise-lames de Jérémy Perrin et Hélène Robert et en avant-première Ingérentes et incurables, de Marie Cornen – Cinéma Comoedia et à partir de 14h, aux archives municipales, le 8 juin 2024
- La fabrique des cartes – atelier gratuit ouvert à tous, le 13 juin 2024
- Les défenses de Lyon – Pierre-Jean Souriac, le 13 juin 2024
- La carte de l’insurrection des canuts en 1834 et ses suites – Bernard Gauthiez, le 20 juin 2024
- Déjouer les risques (matinée jeux en famille) – le 12 juillet 2024
- Fabriquer une carte de A à Z – IGN, le 5 septembre 2024
- Cartes et archéologie à Lyon – Conférence de Mélanie Foucault et Hervé Tronchère, le 12 septembre 2024
- Chemins de papier – Cartes et images du voyage en France et ailleurs, XIXe-XXIe siècle / Paper paths – Maps and images of travel in France and elsewhere, 19th-21st century (Bibliothèque Diderot de Lyon)15 mai – 22 septembre 2024
Les mobilités, phénomènes complexes, mêlent – entre autres – des dimensions technique, politique et culturelle. Pour les périodes récentes, elles s’accompagnent de la diffusion d’une grande variété de documents imprimés aux fonctions diverses, qu’il s’agisse d’aider le voyageur (guide ou carte touristique), de le faire rêver (fiction, iconographie), ou encore de reproduire le voyage (récit et itinéraire d’exploration). Entre le XIXe et le XXIe siècle, les mobilités individuelles se complexifient et s’intensifient en Europe. En lien avec celles-ci, les cartes et les guides, instruments indissociables du voyage et de sa représentation, connaissent de nombreuses transformations. Cette exposition retrace ces évolutions, depuis le guide imprimé jusqu’à l’écran tactile numérique.
Evènements associés :
- Parlez-nous de… Cartes et voyages – Quentin Morcrette et Damien Petermann, 23 mai 2024
- Enjeux et défis de la cartographie contemporaine à l’usage des voyageurs. Christophe Biez, Quentin Morcrette, Damien Petermann, Cyrille Suss, le 25 septembre 2024
- Teaching maps : sur les traces de la cartographie à l’université de Lyon/ Teaching maps: on the trail of cartography at the University of Lyon / (Bibliothèque universitaire de la Manufacture des Tabacs Lyon 3)
L’approche cartographique a accompagné les mutations de l’enseignement de la géographie depuis le XIXème siècle, toujours présente, sa place s’est peu à peu affirmée au sein de l’université de Lyon. C’est par le biais des productions et collections cartographiques des différents géographes et cartographes qui se sont succédés au sein des différentes universités de Lyon que nous vous proposons de suivre 150 ans d’analyses géographiques, parfois locales, parfois lointaines élaborées sur place. 18 juin – 22 septembre 2024
Evènements associés :
- Les cartes postales anciennes de Lyon (fin XIXe-milieu XXe siècle) – master class – Présentation par Enali De Biaggi, Michaël Douvégheant et Damien Petermann du projet d’indexation et de spatialisation des cartes postales anciennes de Lyon : étude géohistorique et valorisation numérique
- Mapathon : un atelier de cartographie collaborative sur OpenStreetMap – le 25 juin 2024
- Visites guidées de l’exposition – le 18 juillet 2024, le 9 septembre 2024, le 19 septembre 2024, le 20 septembre 2024, le 21 septembre 2024 (Journées du Patrimoine)
- Podcast Commun Campus – Le dessous des cartes ( [https:]] )




-
sur Récolt’Ô est le lauréat des Trophées Innovation aux Aqua Business Days 2024
Publié: 17 December 2024, 9:30am CET par Amandine Boivin
L’application Récolt’Ô de valorisation de l’eau de pluie remporte les Trophées Innovation Aqua Business Days 2024. Avec Récolt’Ô préservez votre territoire.
-
sur IASBIM, ou l’IA au service du BIM
Publié: 17 December 2024, 6:25am CET par Raphaël Delhome
Pièce jointe: [télécharger]
 Oslandia s’est récemment illustré au côté de Bimdata et le LIRIS dans le cadre du projet IASBIM, un projet R&D Booster financé par la région Auvergne Rhône-Alpes.
Oslandia s’est récemment illustré au côté de Bimdata et le LIRIS dans le cadre du projet IASBIM, un projet R&D Booster financé par la région Auvergne Rhône-Alpes.L’occasion nous était donnée d’explorer les relations entre les données BIM et le couple Py3dtiles/Giro3D, ainsi que de découvrir le potentiel de la segmentation sémantique appliquée aux nuages de points en 3D.
Contexte du projetLe projet IASBIM se proposait de mettre en avant les méthodes Scan-to-bim pour les acteurs du bâtiment et de la construction, en comblant le fossé entre les nuages de points 3D (captés notamment par Lidar) et les maquettes BIM (au format IFC). Dans cette optique, il s’agissait d’employer des méthodes d’intelligence artificielle et de reconstruction géométrique. Construire une méthodologie de scan-to-bim automatisée ou semi-automatisée peut ainsi permettre de participer à la transformation numérique du secteur de la construction.

Scan-to-BIM: du nuage de points à la maquette BIM
Vers un nouveau procédé de Scan-to-BIMAinsi, à partir de scans 3D opérés sur le terrain fournis par Bimdata, Oslandia a ainsi eu l’opportunité de mettre en oeuvre un algorithme de segmentation sématnique 3D pour produire des nuages de points annotés. Cette information, une fois transmise au LIRIS, a alimenté les algorithmes de reconstruction géométrique développé par le laboratoire. Enfin, les géométries obtenues ont été récupérées par Bimdata, pour finalement être transformées en maquette BIM. Ces maquettes sont proposées en visualisation dans la plateforme Bimdata, qui a la particularité d’exploiter Giro3D.
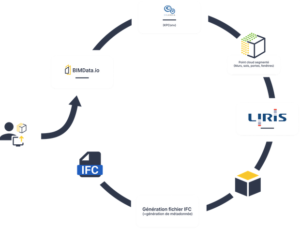
Chaîne de traitement de données construite à l’occasion de IASBIM
Réalisations OslandiaLes principaux chantiers pris en charge par Oslandia sont d’une part la visualisation web 3D, se décomposant en une partie backend représentée par Py3dtiles, pour le traitement amont des données 3D et une partie frontend représentée par Giro3D, et d’autre part, l’annotation sémantique de nuage de points, travail réalisé au moyen d’une implémentation de l’algorithme KPConv.
Visualisation web 3DPour la partie backend, nous avons pu établir l’importance de la hiérarchisation de la donnée BIM, avec le format 3DTiles ( [https:]] ), et détailler les éléments nécessaires à sa conversion vers ce format, notamment en respectant la hiérarchie intrinsèque des éléments constituant un jeu de données BIM ( [https:]] ).

Hiérarchie naturelle d’une donnée BIM
Du côté de la partie frontend, on peut noter qu’IASBIM a permis à la Giro3D de supporter l’affichage de maquettes BIM au format .ifc ( [https:]] ).
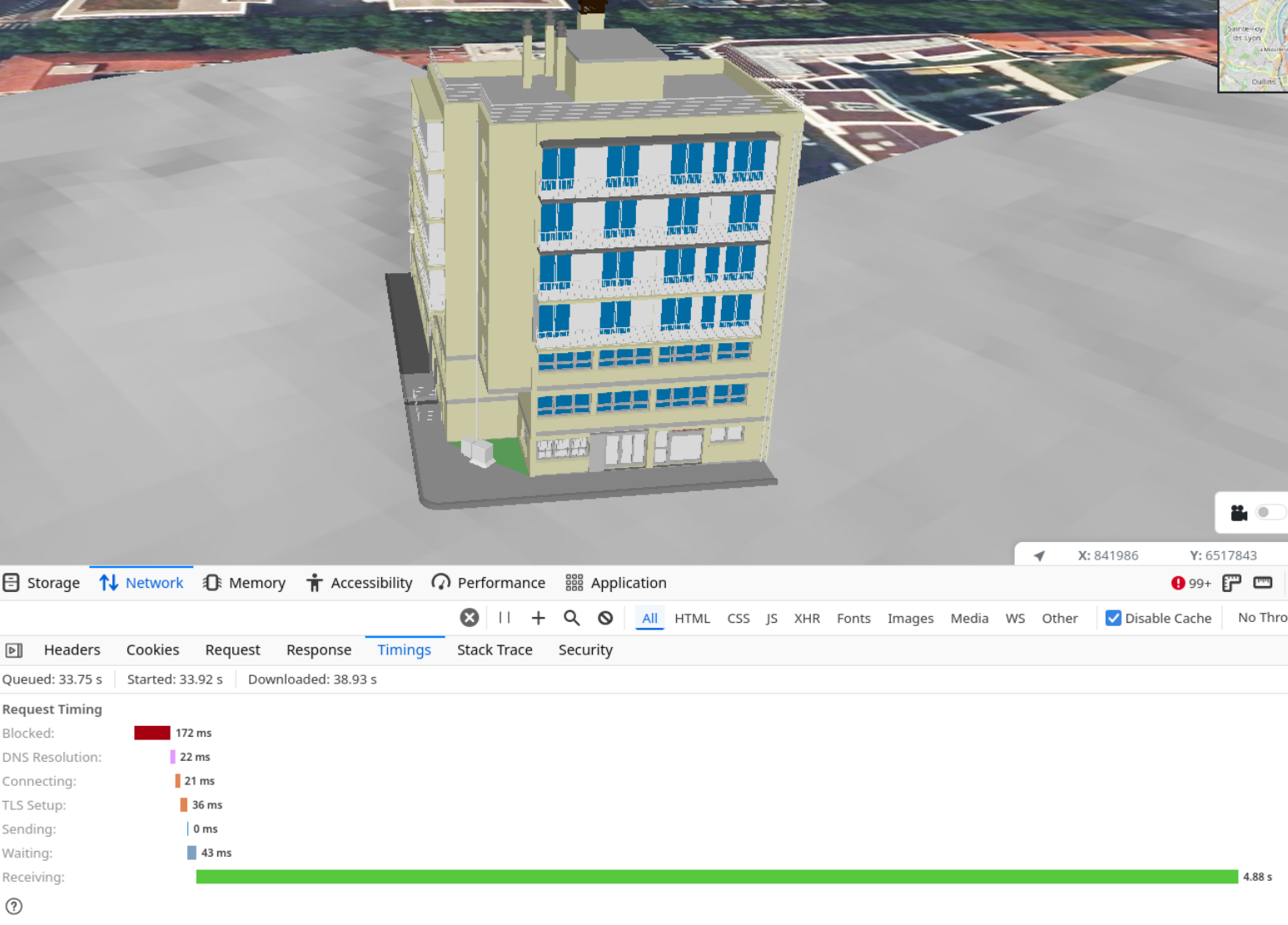
Affichage d’une maquette BIM au format IFC avec Giro3D
En guise de transition avec la partie suivante, dédiée à la segmentation sémantique, on notera également le support de la classification sémantique dans le viewer 3D ( [https:]] ).
Segmentation sémantique 3DEn guise de dernière partie impactante, notons enfin les avancées en matière de segmentation sémantique 3D, qui ont permis à Oslandia de se positionner sur cette technologie via une implémentation de l’algorithme KPConv. Nous avons choisi de travailler à partir de l’implémentation en Pytorch proposée par Hugues Thomas, et lui avons apporté un certain nombre de fonctionnalité pertinentes dans le cadre de IASBIM, via un fork ( [https:]] ). Cela nous a conduit à produire nos premières inférences sur des jeux de données exploités pendant IASBIM ( [https:]] ), ainsi qu’une feuille de route pour les prochaines étapes sur ce sujet !

Exemple de prédiction par KPConv en contexte outdoor, on note les murs en marron, le sol en bleu, les avancées de toiture en jaune, notamment
Pour aller plus loinSi vous désirez en savoir plus sur IASBIM, vous pourrez retrouver quelques informations supplémentaires sur le blog dédié au projet ( [https:]] ).
Vous êtes intéressés par les interactions entre modèles 3D et maquettes BIM, ou par la visualisation web de données 3D de manière plus générale ? N’hésitez pas à nous contacter via infos@oslandia.com pour en savoir plus !
-
sur L'Overture Maps Foundation ambitionne de rivaliser avec Google et Apple
Publié: 17 December 2024, 6:21am CET
L'Overture Maps Foundation, constituée d'Amazon, Meta, Microsoft, Tom-Tom et d'autres "géants" de l'Internet, ambitionne de rivaliser avec Google et Apple dans les années à venir, avec de la donnée ouverte. Sa mission déclarée est « d'alimenter les produits cartographiques actuels et de nouvelle génération en créant des données cartographiques ouvertes, fiables, faciles à utiliser et interopérables »
1) Les objectifs du projet OvertureFondé en 2022, le projet Overture s'adresse aux développeurs qui créent des services cartographiques ou utilisent des données géospatiales. L’approvisionnement et la conservation de données cartographiques de haute qualité, à jour et complètes provenant de sources disparates sont difficiles et coûteux. Overture vise à intégrer des données cartographiques provenant de plusieurs sources, notamment des membres d'Overture, des organisations civiques et des sources de données ouvertes. L'enjeu est la création de cartes collaboratives.
Au delà de l'ouverture des données, l'objectif est également de proposer un système de référence partagé. Plusieurs ensembles de données font référence aux mêmes entités du monde réel en utilisant leurs propres conventions et leur propre vocabulaire, ce qui les rend difficiles à fusionner et à combiner. Overture Maps vise à simplifier l’interopérabilité en fournissant un système reliant les entités de différents ensembles de données aux mêmes entités du monde réel. Overture souhaite définir et favoriser l’adoption d’un schéma de données commun, bien structuré et documenté pour créer un écosystème de données cartographiques facile à utiliser.
Les données cartographiques sont vulnérables aux erreurs et aux incohérences. Les données d'Overture Maps seront soumises à des contrôles de validation pour détecter les erreurs cartographiques, les cassures et le vandalisme afin de garantir que les données cartographiques puissent être utilisées dans les systèmes de production.
2) Les données mises à disposition
Les données sont disponibles au format GeoParquet V1.1.0, une norme en cours d'incubation de l'Open Geospatial Consortium qui ajoute des types géospatiaux interopérables au format Apache Parquet, via Amazon AWS et Microsoft Azure.
La première publication de données comprenait quatre « thèmes » :
- Lieux - Données sur les points d'intérêt (POI) sur environ 60 millions de lieux dans le monde
- Bâtiments - données sur l'empreinte et la hauteur des bâtiments pour 785 millions de bâtiments dans le monde
- Transports - données sur le réseau routier
- Limites administratives - limites administratives pour le niveau 2 (niveau du pays) et le niveau 4 (subdivisions de premier niveau sous le pays) dans le monde.
Ces données sont régulièrement enrichies et mises à jour. La version des données Overture 2024-10-23.0 est désormais disponible. Overture Maps Explorer permet d'avoir un aperçu des données mises à disposition. Les instructions pour accéder aux données sont disponibles sur le référentiel de données Overture Maps.
Le projet Overture se veut complémentaire du projet OpenStreetMap, et la fondation encourage les membres à contribuer directement aux données du projet OSM. On peut cependant s'interroger dans quelle mesure ces données sont vraiment ouvertes. Deux des quatre « thèmes » d'Overture Maps Foundation sont disponibles sous une licence ODbL et deux des thèmes sont disponibles sous une licence CDLA Permissive v 2.0.
This could be big... Even huge?
— Christopher Beddow (@cbed32) July 26, 2023
Overture Maps releases a global POI open dataset, an aggregate of Microsoft @bingmaps and @Meta places data.
Read more: [https:]] #openstreetmap #opendata #gischat pic.twitter.com/bYTFHigtRe? Unlock the power of Overture Maps data with Leafmap and MapLibre! Explore open-access global-scale data on buildings, transportation, places, addresses, basemaps, and more. Integrate open-access data into your workflow with Python ?
— Qiusheng Wu (@giswqs) August 22, 2024
? Notebook: [https:]]
?… pic.twitter.com/qBt8oCGkXUDay 29. Overture #30DayMapChallenge Comparative Analysis of Building Data: OpenStreetMap vs Overture Maps Foundation in Ukraine pic.twitter.com/BZn7LKSAtD
— gontsa ?? (@gontsa) November 29, 2024#30daymapchallenge · JOUR 29 : "Source de données : Overture" ?#cartographie #map #carte #overture #sncf pic.twitter.com/l7Hp0dUISz
— Alexandre Médina (@A_Lex_Map) November 29, 2024Articles connexes
Open Source Places, une base de données de 100 millions de POI en open source (Foursquare)
AllThePlaces : géodonnées et vision du monde commercial à travers Internet
Cartes et données sur la population mondiale (Population & Sociétés, 2024)
Guide de l'Insee pour faciliter l’accès aux données
Jeu de données SEDAC sur l'évolution des villes dans le monde entre 1975 et 2030
Geonames, une base mondiale pour chercher des noms de lieux géographiques
OpenDataSoft : une plateforme avec plus de 1800 jeux de données en accès libre
Data France, une plateforme de visualisation de données en open data
Numbeo, une banque de données et de cartes sur les conditions de vie dans le monde
-
sur Des images satellites déclassifiées révèlent les impacts de la guerre du Vietnam
Publié: 17 December 2024, 4:12am CET
Source : « Declassified satellite photos reveal impacts of Vietnam War » (Science.org)Pendant la guerre du Vietnam, les États-Unis ont largué plus de 8 millions de tonnes de bombes et 74 millions de litres d’Agent orange ainsi que d’autres herbicides sur le Vietnam, le Cambodge et le Laos. Près de 50 ans après la fin de la guerre, les conséquences mortelles de ces campagnes militaires persistent : les munitions non explosées continuent de mutiler et de tuer, tandis que des points chauds de dioxine, une toxine puissante présente dans les herbicides, sont suceptibles de contribuer à des cancers et des malformations congénitales. Aujourd’hui, grâce à des photos satellites militaires déclassifiées, des scientifiques ont identifié les emplacements probables de ces zones à risque, ce qui pourrait aider à orienter les opérations de repérage et de nettoyage.
Il est difficile d’identifier ces zones à risque dans le paysage moderne. La végétation tenace a depuis longtemps masqué les cicatrices de la guerre, et les archives historiques sur les missions de bombardement et les épandages d’herbicides sont à la fois incomplètes et imprécises. C'est pourquoi Philipp Barthelme, étudiant diplômé en géosciences à l'Université d'Édimbourg, et ses collègues se sont tournés vers des photos satellites déclassifiées des missions KH-9 HEXAGON et KH-4a/b CORONA, qui étaient suffisamment nettes pour révéler des détails à des échelles très fines (60 cm).
Bien que les données satellite ne permettent pas à elles seules d'identifier les bombes non explosées, les chercheurs ont supposé qu'elles se trouvaient probablement dans les régions qui ont été lourdement bombardées. Les cratères des bombes explosées ressortent sur les images satellite sous forme de taches blanches brillantes. Les chercheurs ont utilisé l'apprentissage automatique, une sorte d'intelligence artificielle, pour repérer plus de 500 000 de ces cratères dans la province vietnamienne de Quang Tri, qui a été la plus bombardée pendant la guerre, ainsi que dans une région proche des frontières du Vietnam, du Laos et du Cambodge.
Les données satellite peuvent également aider à suivre l’impact des conflits modernes, explique Sergii Skakun, chercheur à l’Université du Maryland qui utilise l’imagerie satellite pour suivre la manière dont la guerre en cours en Ukraine endommage les terres agricoles et la production agricole. Skakun, qui a présenté une affiche lors de la réunion de l’AGU, a identifié plus de 3,8 millions de cratères d’artillerie dans son analyse de quelque 31 000 kilomètres carrés d’Ukraine en 2022. Les drones civils sont interdits dans la région, note Skakun, ce qui signifie que les images satellites commerciales et gouvernementales accessibles au public sont le seul moyen de surveiller les impacts en temps réel.
Sources scientifiques
Philipp Barthelme, Eoghan Darbyshire, Dominick V. Spracklen, Doug Weir, Gary R. Watmough. Combining Historical Records and Declassified U.S. Spy Satellite Imagery to Assess the Long-term Impacts of the Vietnam War (AGU24). [Combinaison de documents historiques et d'images satellites d'espionnage américain déclassifiées pour évaluer les impacts à long terme de la guerre du Vietnam]. [https:]]New data on Agent Orange use during the US’s secret war in Laos. Conflict and Environment Observatory (CEOBS) . [https:]]
Pulvérisation d’herbicides pendant la guerre secrète américaine au Laos (source : CEOBS)
Philipp Barthelme, Eoghan Darbyshire, Dominick V. Spracklen, Gary R. Watmough, Detecting Vietnam War bomb craters in declassified historical KH-9 satellite imagery, [Détection de cratères de bombes de la guerre du Vietnam dans des images satellite historiques déclassifiées du KH-9], Science of Remote Sensing, Volume 10, 2024. [https:]]Cibles de bombardement au-dessus de l'Asie du Sud-Est pendant la guerre du Vietnam (source : Barthelme et al. 2024)

Pour compléter
« Des images satellites d'espionnage déclassifiées révèlent un ancien site de bataille en Irak » (Geo).
« Des sites romains découverts sur des images déclassifiées » (Ça m'intéresse).
« Des images satellites datant de la Guerre froide permettent d'évaluer les changements environnementaux » (Sciences et Avenir).Articles connexes
Des images aériennes déclassifiées prises par des avions-espions U2 dans les années 1950 ouvrent une nouvelle fenêtre pour l'étude du Proche-Orient
Plus de 400 000 photographies aériennes mises en ligne par les archives historiques de l'Angleterre
Les ventes d'armes des Etats-Unis et de la Russie (1950-2017)
Cartes sur le débarquement en Normandie (6 juin 1944)
Cartes et données sur les conflits et violences dans le monde (ACLED)
Ukraine : comment cartographier la guerre à distance ?
Des différents modes de visualisation pour comparer des images aériennes ou satellitaires
Cartes et atlas historiques -
sur Carte du déploiement de la fibre optique en France
Publié: 16 December 2024, 8:00am CET
Il était jusqu'à récemment difficile de se rendre compte des disparités entre la desserte du réseau cuivre et de celle de la fibre alors que le second est appelé à remplacer le premier. Le site cuivre.infos-reseaux propose une vue cartographique du programme de fermeture du réseau cuivre et de la complétude FTTH associée dans chaque commune. Le programme se déroule selon un calendrier progressif sur 10 ans, partant d'expérimentations sur des périmètres réduits jusqu'à des phases industrielles de plusieurs millions de locaux. Il est donc particulièrement utile de disposer d'outils efficaces pour en comprendre le déroulement. Cette application prétend répondre à une partie de ces besoins.
« Le cuivre raccroche. Préparez la transition vers la fibre optique » (source : cuivre.infos-reseaux.com)
Si l'on zoome sur la carte, on voit apparaître les foyers connectés au réseau cuivre (en rose) et ceux connectés au réseau fibre (en vert). La carte permet ainsi d'analyser l'inégale couverture de la fibre optique sur le territoire national à l'échelle de chaque commune et de chaque adresse. Les territoires ultramarins sont également représentés.Etat du déploiement de la fibre optique dans la région lyonnaise (source : cuivre.infos-reseaux.com)
Les données très précises sont celles de l'ARCEP. L'article 28 de la décision ARCEP 2023-2802 encadre la publication des données utilisées par cette application. Cette publication ne prévoit pas la géolocalisation des adresses. Les positions ne sont donc pas données par Orange mais obtenues à partir de la BAse Adresse Nationale (BAN), dont la complétude et l'exactitude sont in fine de la responsabilité des mairies.
Les données descriptives des adresses desservies par les réseaux fibre sont publiées par l'ARCEP dans le cadre de ses études de marché du Très Haut Débit et de sa collecte de données auprès des opérateurs. Elles sont disponibles sur le site gouvernemental data.gouv.fr.
Les données relatives au programme de fermeture et les adresses desservies par le réseau cuivre sont aussi publiées par Orange France
La carte des déploiements fibre (FttH) est aussi visible sur le site de l'ARCEP. On y trouve en plus la carte des débits en réception pour chaque adresse.
Articles connexes
Carte mondiale des antennes-relais mobiles à partir des données ouvertes d'OpenCelliD
Infrastructures numériques : un accès encore inégal selon les pays
La carte mondiale de l'Internet selon Telegeography
Les câbles sous-marins, enjeu majeur de la mondialisation de l'information
Une cartographie mondiale des points de connexion Wi-Fi réalisée dans le cadre du projet WiGLE
Cartographie nationale des lieux d'inclusion numérique (ANCT - MedNum)
L'essor parallèle de la Silicon Valley et d'Internet : du territoire au réseau et inversement
La carte des tiers-lieux en France

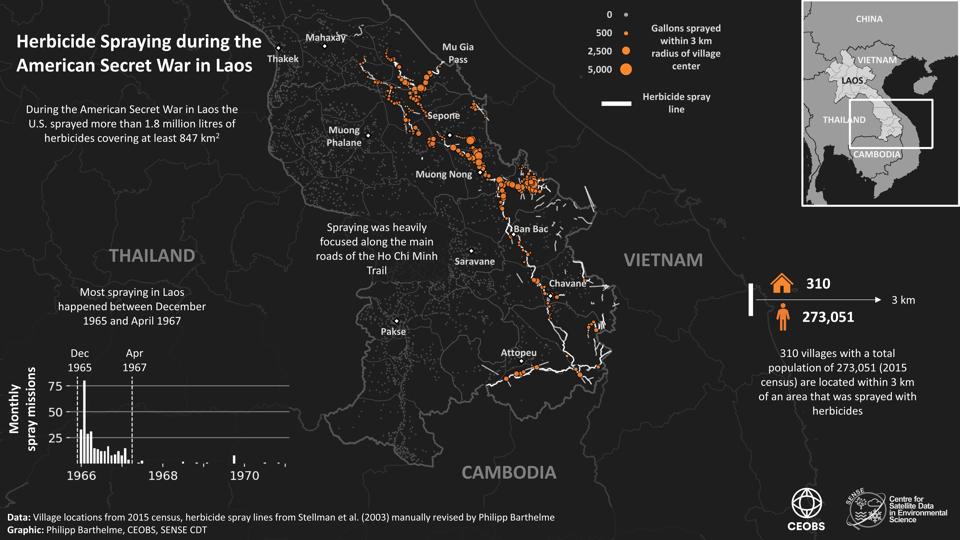
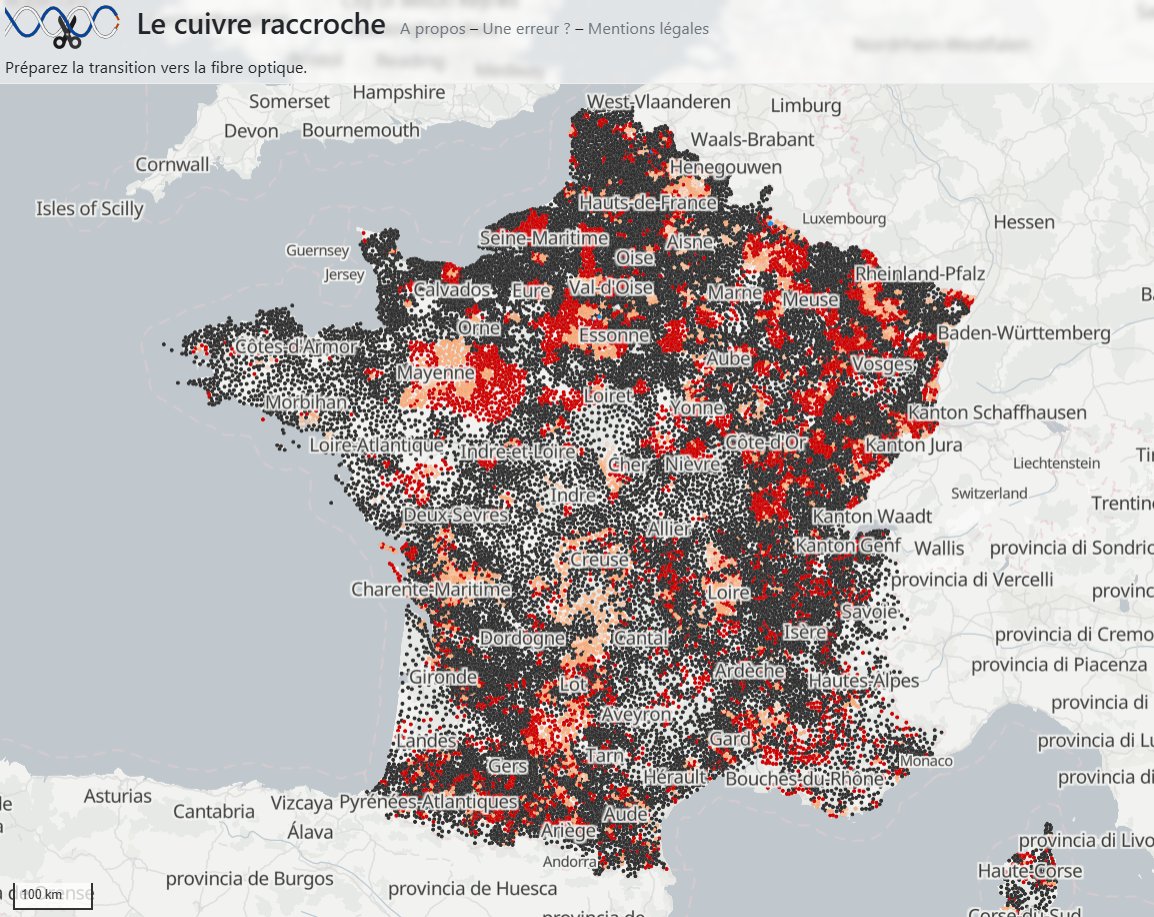
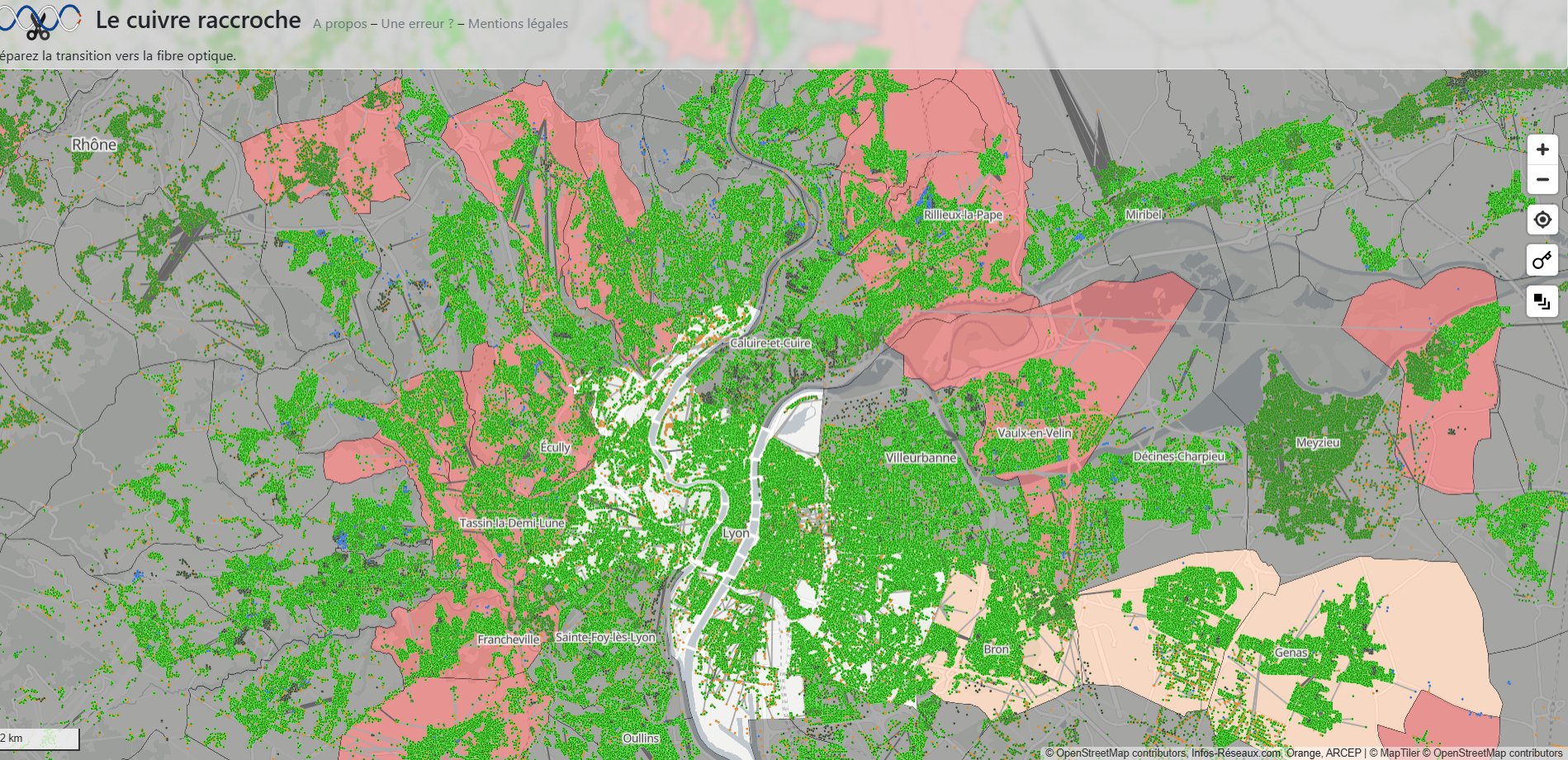
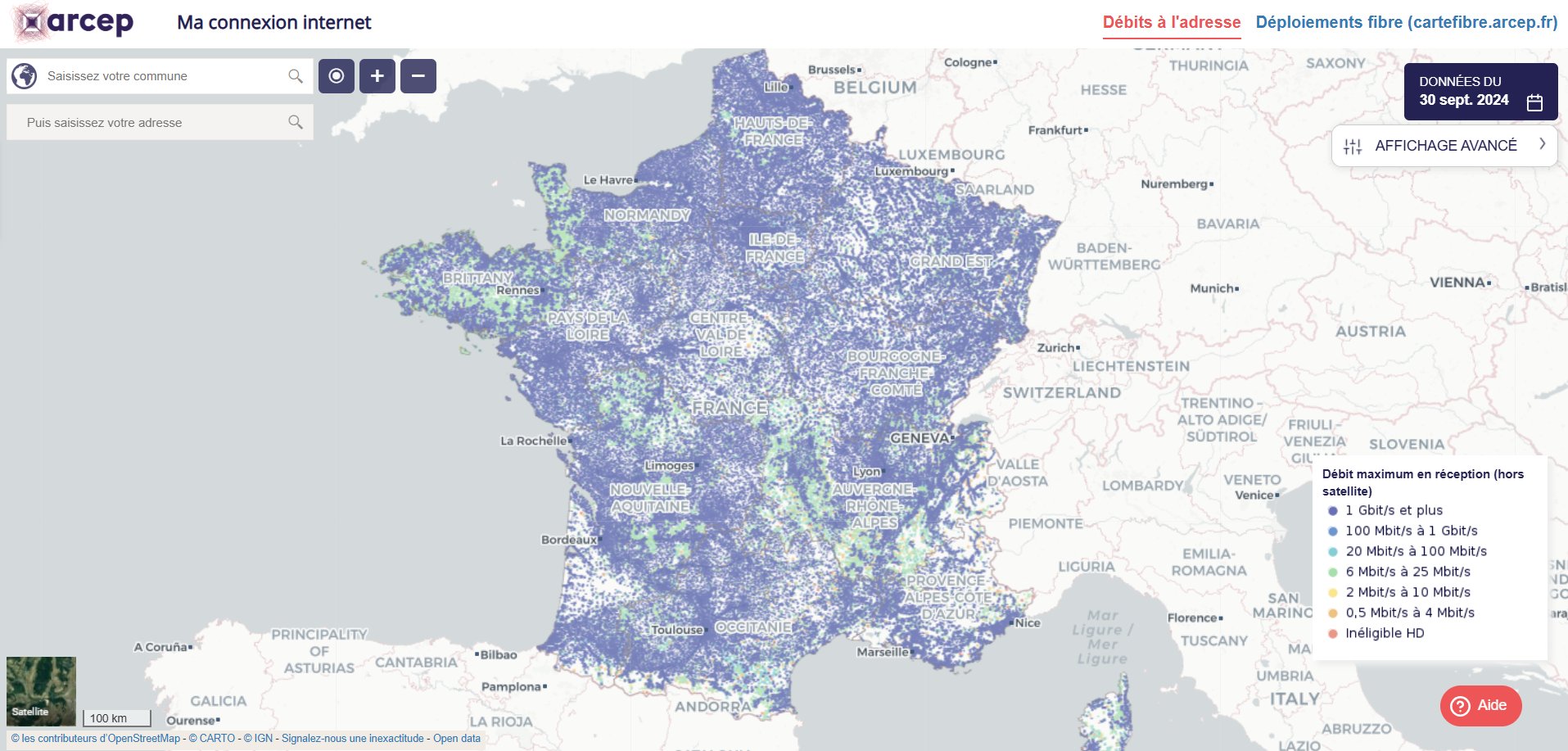
-
sur Mappae mundi (VIIIe-XIIe siècle)- Patrick Gautier Dalché
Publié: 15 December 2024, 2:46pm CET par Emmanuelle Vagnon

MAPPAE MUNDI (VIII e –XII e siècle). Catalogue codicologique par Patrick Gautier Dalché
Turnhout, Brepols, 2024
2 vols, 1237 pages, 230 x 315 mm
Brepols – Mappae mundi (VIIIe-XIIe siècle)
On appelle mappae mundi ou mappemondes, des représentations de l’ensemble de la sphère terrestre, ou de sa partie habitée. Dans les manuscrits du Moyen Âge occidental, ces croquis accompagnent fréquemment des traités historiques et géographiques, mais aussi mathématiques et astronomiques. Jusqu’à présent, leur recensement systématique n’avait jamais été réalisé.
Fruit d’un patient travail de recherche, mené depuis de longues années par Patrick Gautier Dalché, cette somme imposante décrit dans le détail des centaines de diagrammes et de cartes plus détaillées, insérés dans des manuscrits médiévaux, principalement latins, entre le VIIIe et la fin du XIIe siècle.
Chaque exemplaire est présenté dans sa matérialité, son contexte codicologique et intellectuel, et accompagné d’une reproduction commentée. Un instrument de travail indispensable pour tous ceux qui s’intéressent à la géographie et à la pensée de l’espace au Moyen Âge.
-
sur Bande dessinée : Geographia- L’odyssée cartographique de Ptolémée
Publié: 15 December 2024, 1:06pm CET par Emmanuelle Vagnon

Geographia, L’odyssée cartographique de Ptolémée
Coédition Futuropolis et Éditions de la BnF
160 pages en couleur, 150 illustrations 22 x 29,8 cm 23 euros
En librairie le 6 novembre 2024
En suivant les pérégrinations imaginaires de Ptolémée au Paradis, à la rencontre des spécialistes du domaine, la bande dessinée érudite et humoristique Geographia, l’odyssée cartographique de Ptolémée raconte l’épopée de cet art.
Convaincu que l’œuvre de sa vie, la Géographie, a marqué l’histoire des sciences après lui, Ptolémée tombe des nues : non seulement, son nom est peu connu, mais surtout, son rival de toujours, Marin de Tyr, a reçu le titre de meilleur géographe de l’Antiquité latine.
A l’aide d’Ota, une panotéenne, créature légendaire aux longues oreilles pendantes, Ptolémée entreprend donc de retrouver la trace de sa Géographie à travers le temps et l’espace pour faire la preuve de son succès.
Cette aventure, aussi instructive qu’amusante, est racontée par deux spécialistes, Jean Leveugle auteur et géographe et Emmanuelle Vagnon, professeure agrégée et docteure en histoire médiévale, chargée de recherche au CNRS.
Un dossier pédagogique avec de nombreuses cartes anciennes issues des collections de la BnF complète le récit.
En coédition Editions Futuropolis et BnF éditions, disponible en librairies


-
sur La cartographie des médias locaux en France (Ouest Médialab)
Publié: 13 December 2024, 3:04pm CET
Ouest Médialab a recensé 2 644 rédactions locales en France en 2024. Après un premier chantier lancé en 2019, cette étude unique est le fruit d’un travail de collecte de données doublé d’un appel à contribution auprès des médias locaux. Elle prend en compte les rédactions des journaux, télévisions, radios et médias en ligne qui composent le paysage médiatique en régions.
La carte des médias locaux par Ouest Médialab
Les médias locaux en??France, une??diversité à??préserver
Le paysage de l’info de proximité est bien plus divers et pluriel qu’il n’y paraît. On y dénombre aujourd’hui 2644 rédactions locales. Cette diversité s'observe aussi dans certains territoires d'outre-mer.
Cette diversité est précieuse. Elle garantit une forme de pluralisme de l’information. Elle évite aussi que des territoires deviennent demain des déserts médiatiques, avec les conséquences désastreuses que l’on peut observer dans d’autres démocraties, comme aux Etats-Unis. Mais ce paysage reste fragile, il faut le préserver et le cultiver.
Liste des rédactions et méthodologie
Cette base de données d’utilité publique pour mieux comprendre le paysage médiatique, est mise à disposition de tous : professionnels des médias, chercheurs ou étudiants et grand public. La liste des rédactions est disponible avec leur nom, leur type (presse, radio, télé, pure-player), leur groupe d'appartenance, leur commune et leur département. Ces données ont été collectées auprès des organisations professionnelles, des institutions et des médias eux-mêmes, agrégées puis cartographiées par le datajournaliste Denis Vannier, du studio Le Plan, et l’équipe de Ouest Médialab.
Un traitement automatique des données a été effectué par Nino Auriède, étudiant-chercheur de Polytech Nantes avec le soutien de Jeanpierre Guédon, professeur en informatique de l’Université de Nantes et cofondateur de Ouest Médialab.
Il a permis d’automatiser la collecte des données des différentes sources et leur tri en passant en revue 5 000 sites web. En analysant le contenu des pages d’accueil des sites d’information, le recours à l’intelligence artificielle a contribué à déterminer le caractère local d’un média.
Cette deuxième version de la cartographie des médias locaux comprend près de 1 100 médias de plus qu’en 2019 qui avait recensé 1 512 rédactions. 724 radios locales ont été intégrées grâce à la liste d’adhérents du Syndicat National des Radios Libres (SNRL), additionnées du résultat de contributions volontaires de grands groupes de presse et syndicats professionnels.
Il est possible de contribuer en ajoutant un média qui ne figure pas sur la carte ou en complétant des informations déjà présentes dans la base de données.
La base de données mise à disposition par Ouest Medialab permet de faire des analyses. Par exemple ici les villes d'implantation de la presse régionale. Avec possibilité de comparer avec la radio ou la télévision.Articles connexes
CLEMI : la carte des médias scolaires
La liberté de la presse dans le monde selon Reporters sans frontières
Mesurer la liberté de la presse dans le monde en 2022. Reporters Sans Frontières modifie sa méthodologie
Cartographie des journalistes tués ou emprisonnés dans le monde
Carte de l'indice de perception de la corruption (Transparency International)
L'indice de perception de la démocratie selon Dalia Research
L’état de la liberté académique dans le monde
La carte, objet éminemment politique : peut-on évaluer la qualité d'une démocratie ?
La carte comme outil d'accès et d'analyse de l'information à l'échelle internationale
-
sur Chef-Cheffe de projets web junior : climat, agriculture et environnement
Publié: 13 December 2024, 1:34pm CET par Lise Benazeth
Contrat : CDI
Lieu : Toulouse
-
sur ANITI Days 2024 : une plongée au cœur des innovations en intelligence artificielle
Publié: 13 December 2024, 9:00am CET par admin
Les 25 et 26 novembre dernier, j’ai eu la chance de participer aux ANITI Days, organisés à la Cité de Montaudran à Toulouse. Ces journées dédiées à l’intelligence artificielle sont orchestrées par l’ANITI (Artificial and Natural Intelligence Toulouse Institute), un institut de recherche de pointe en Occitanie spécialisé dans l’intelligence artificielle.
Rencontres enrichissantes autour du Retrieval-Augmented Generation (RAG)Parmi les nombreux exposants, j’ai particulièrement apprécié échanger autour des avancées sur le Retrieval-Augmented Generation (RAG), une approche mêlant récupération d’information et génération de contenu.
- Avec les chercheurs de LIEBHERR, j’ai découvert une bibliothèque prometteuse visant à optimiser le RAG en fonction des types de documents à traiter. Une solution qui ouvre des perspectives fascinantes pour améliorer l’adaptabilité et l’efficacité de cette technologie.
- De leur côté, les équipes de Synalinks m’ont présenté leurs travaux sur des agents RAG hybrides combinant IA symbolique et modèles de langage (LLM). Ces agents, capables de s’auto-améliorer, marquent une étape vers des systèmes d’IA toujours plus autonomes et performants.
Plus d’une douzaine de conférences ont rythmé ces deux jours, mettant en lumière les avancées scientifiques majeures dans différents domaines de l’IA. Voici quelques moments forts :
- Ellie Pavlick (en visioconférence) a exploré la compréhension des réseaux de neurones, notamment à travers des heat maps pour visualiser l’influence des neurones sur les réponses. Elle a introduit les notions de fonctions extractives et fonctions abstraites, illustrant les mécanismes par lesquels les modèles génèrent leurs réponses.
- Julie Hunter de Linagora a dévoilé un projet ambitieux : un modèle de langage entièrement libre nommé Lucie. Contrairement à d’autres modèles comme LLaMA, Lucie promet une transparence totale, en fournissant à la fois les poids, les scripts d’entraînement et les données utilisées. Un pas décisif vers une IA éthique et reproductible, essentielle pour garantir la sécurité et la fiabilité des systèmes.
- Chloé Braud a présenté des recherches préliminaires sur l’entraînement de modèles avec peu de données, une approche prometteuse pour réduire les coûts en ressources de calcul tout en maintenant des performances élevées.
- Eliot Chane s’est intéressé au pilotage robotique, utilisant des simulations d’environnements et des vidéos de documentaires animaliers pour former des agents dans un cadre d’apprentissage non supervisé.
- Rufin VanRullen a introduit le concept de Global Latent Workspace, un réseau de neurones multimodal intégrant langage, vision et mouvement. Cette approche innovante montre des résultats impressionnants pour le pilotage de robots.
Le deuxième jour, des thématiques tout aussi captivantes ont été abordées :
- Claire Monteleoni a exploré les applications de l’IA dans le cadre des défis climatiques.
- Vincent Martin a présenté des projets innovants utilisant les données du CNES, avec des applications allant de la météo à la bathymétrie.
- Plusieurs conférences se sont concentrées sur les enjeux de confiance et de garanties dans les réseaux de neurones, avec des interventions remarquées de Matthieu Serrurier, Mélanie Ducoffe et Paul Novello, sur des stratégies pour certifier, valider et encadrer les résultats des modèles.
La journée s’est conclue avec une présentation d’Urtzi Ayesta, démontrant qu’un apprentissage par renforcement pouvait modéliser un système à nombre d’états indéterminés, une avancée significative dans l’étude des systèmes complexes.
Un événement inspirantCes deux jours furent une immersion riche en découvertes, rencontres et échanges, révélant les défis et opportunités qui façonnent l’avenir de l’intelligence artificielle. Que ce soit pour les passionnés, les chercheurs ou les professionnels, les ANITI Days illustrent à quel point l’IA est au cœur des transformations technologiques et sociétales en cours.
J’ai hâte de voir comment ces avancées se concrétiseront dans les années à venir et suis convaincu que l’Occitanie continuera de jouer un rôle clé dans cet écosystème en plein essor.
Auteur : Sébastien Da Rocha (Service Innovation, Neogeo)
-
sur Premières images radar du satellite Sentinel-1C (Copernicus)
Publié: 13 December 2024, 7:50am CET
Source : « Sentinel-1C captures first radar images » (European Spatial Agency, 10 décembre 2024)Moins d’une semaine après son lancement, le satellite Copernicus Sentinel-1C a livré ses premières images radar de la Terre, offrant un aperçu de ses capacités de surveillance dans le domaine de l'environnement. Lancé le 5 décembre 2024 depuis le Centre Spatial Guyanais à bord d'une fusée Vega-C, Sentinel-1C est équipé d'un radar à synthèse d'ouverture (SAR) en bande C. Cette technologie de pointe permet au satellite de fournir des images haute résolution de jour comme de nuit, quelles que soient les conditions météorologiques, pour des applications critiques telles que la gestion de l'environnement, la réponse aux catastrophes et la recherche sur le changement climatique.
Le nouveau satellite a désormais livré sa première série d’images radar au-dessus de l’Europe, traitées par le segment au sol de Copernicus. Ces images présentent un niveau exceptionnel de qualité des données pour les images initiales, soulignant les efforts remarquables de toute l’équipe Sentinel-1 au cours des dernières années. Ces premières images montrent des régions d’intérêt, notamment le Svalbard en Norvège, les Pays-Bas et Bruxelles en Belgique.
Image des Pays Bas captée par Sentinel-1C (Source : © ESA)

Cette image Sentinel-1C des Pays-Bas fait écho à la toute première image SAR acquise par la mission européenne de télédétection (ERS) en 1991, qui a capturé le polder de Flevoland et l'IJsselmeer, marquant ainsi la première image radar européenne jamais prise depuis l'espace.
La Commission européenne supervise Copernicus, qui coordonne divers services visant à protéger l'environnement et à améliorer la vie quotidienne. L'ESA, responsable de la famille de satellites Sentinel, assure un flux constant de données de haute qualité pour soutenir ces services. Simonetta Cheli, directrice des programmes d'observation de la Terre à l'ESA, a déclaré : « Ces images mettent en évidence les capacités remarquables de Sentinel-1C. Bien qu'il soit encore trop tôt pour le dire, les données montrent déjà comment cette mission va améliorer les services Copernicus au profit de l'Europe et au-delà. »
Depuis son lancement, Sentinel-1C a subi une série de procédures de déploiement complexes, notamment l'activation de son antenne radar de 12 mètres de long et de ses panneaux solaires. Bien que le satellite soit encore en phase de mise en service, ces premières images soulignent son potentiel à fournir des informations exploitables dans toute une gamme d’applications environnementales et scientifiques.
Ramon Torres, chef de projet de l'ESA pour la mission Sentinel-1, a déclaré à propos du lancement de Sentinel-1C : « Sentinel-1C est désormais prêt à poursuivre le travail essentiel de ses prédécesseurs, en dévoilant les secrets de notre planète, de la surveillance des mouvements des navires sur les vastes océans à la capture des reflets éblouissants de la glace de mer dans les régions polaires et des subtils changements de la surface de la Terre. Ces premières images incarnent un moment de renouveau pour la mission Sentinel-1. »
Les données de Sentinel-1 contribuent à de nombreux services et applications Copernicus, notamment la surveillance de la banquise arctique, le suivi des icebergs, la cartographie de routine de la banquise et les mesures de la vitesse des glaciers. Elles jouent également un rôle essentiel dans la surveillance marine, comme la détection des déversements d'hydrocarbures, le suivi des navires pour la sécurité maritime et la surveillance des activités de pêche illégale.
En outre, il est largement utilisé pour observer les déformations du sol causées par les affaissements, les tremblements de terre et l'activité volcanique, ainsi que pour cartographier les forêts, les ressources en eau et en sol. Cette mission est essentielle pour soutenir l'aide humanitaire et répondre aux crises dans le monde entier.
Toutes les données Sentinel-1 sont disponibles gratuitement via l'écosystème Copernicus Data Space, offrant un accès instantané à une large gamme de données provenant à la fois des missions Sentinel et des missions contributives Copernicus.
Articles connexes
Le satellite Sentinel-2C livre ses premières images (ESA - Copernicus)
Les images satellites Spot du CNES (1986-2015) mises à disposition du public
Images satellites Spot 6-7 accessibles en open data
Images satellites Maxar à télécharger en open data
Images satellites Landsat 9 mises à disposition par l'USGS
Blanchissement des coraux et suivi satellitaire par la NOAA
La NASA met à disposition plus de 11 000 vues satellitaires prises ces 20 dernières années
Les photos de la Terre prises par Thomas Pesquet lors de ses missions spatiales
Animer des images satellites Landsat avec Google Earth Engine et l'application Geemap
Comment les frontières politiques façonnent les paysages. Une série d’images satellites Planet en haute résolution
Cartographier les bâtiments en Afrique à partir d'images satellites
Carte des précipitations mondiales (2007-2021) enregistrées par les satellites du programme EUMETSAT
Rubrique outils et images satellitaires
-
sur Appel à commentaire sur le rapport phase 1 du Groupe de travail Routes
Publié: 12 December 2024, 4:08pm CET
Appel à commentaire sur le rapport phase 1 du Groupe de travail Routes
-
sur Les effets atmosphériques avec Giro3D
Publié: 12 December 2024, 6:57am CET par Sébastien Guimmara
Pièce jointe: [télécharger]
Cet article concerne des fonctionnalités en cours de développement et sujettes à évolution.
Dans le cadre du développement du mode globe de Giro3D (voir notre article à ce sujet), voyons de plus près les effets atmosphériques proposés en complément de la nouvelle entité Globe: Glow, Atmosphere et SkyDome.
L’entité Glow Ces trois entités sont totalement indépendantes de l’entité Globe (et de toutes les autres entités de Giro3D) et peuvent donc être utilisées dans des scènes ne comportant aucun globe (par exemple en remplaçant les globes par de simples sphères colorées).
Ces trois entités sont totalement indépendantes de l’entité Globe (et de toutes les autres entités de Giro3D) et peuvent donc être utilisées dans des scènes ne comportant aucun globe (par exemple en remplaçant les globes par de simples sphères colorées).Cette entité permet de représenter un simple halo lumineux sphérique. Il permet de représenter un objets émettant de la lumière (comme le Soleil), ou bien une atmosphère très simplifiée (en terme de puissance de calcul graphique requise). Elle n’est pas sensible à l’éclairage de la scène.
Création d'un halo lumineux de la taille du soleilconst SUN_RADIUS = 696_340_000; const glow = new Glow({ color: '#ff7800', ellipsoid: Ellipsoid.sphere(SUN_RADIUS), });
Le globe du soleil seul

Le halo du soleil seul

Globe et halo combinés
L’entité AtmosphereCette entité permet de représenter fidèlement une atmosphère vue de l’espace. Elle requiert une position du soleil pour fonctionner, via la méthode
Atmosphere.setSunPosition().
Création d'une atmosphère autour de la terreconst atmosphere = new Atmosphere({ ellipsoid: Ellipsoid.WGS84 }); const sunLatitude = 5; const sunLongitude = 45; const sunPosition = Ellipsoid.WGS84.toCartesian( sunLatitude, sunLongitude, 50_000_000, ); atmosphere.setSunPosition(sunPosition);
L’entité Atmosphere combinée à une simple sphère bleue
Une fois combiné avec un Globe paramétré avec des couches images appropriées, voici le résultat:

Globe terrestre et atmosphère combinés
L’entité SkyDomeCette dernière entité est le pendant de l’entité Atmosphere, mais vu depuis l’intérieur. Elle permet de représenter la diffusion Rayleigh, c’est à dire la diffusion des rayons du soleil dans le ciel (ce qui donne sa couleur au ciel). Le disque solaire est également représenté avec fidélité selon la position apparente du soleil par rapport à l’horizon.
Ajout d'un _Skydome_ à l'instance Giro3Dconst skyDome = new SkyDome(); instance.add(skyDome); atmosphere.setSunPosition(sunPosition);
Un crépuscule

Une heure plus avancée
ConclusionCombinées aux éclairages dynamiques et aux ombres portées, ces trois nouvelles entités permettront aux utilisateurs de créer de belles scènes réalistes, de l’échelle locale à celle du système solaire.
-
sur Une nouvelle plaquette de présentation du CNIG !
Publié: 11 December 2024, 4:11pm CET
Une nouvelle plaquette de présentation du CNIG !
-
sur Evolution de l’altitude de la ligne de neige au cours des 40 dernières années dans le bassin versant du Vénéon (Oisans)
Publié: 10 December 2024, 3:54pm CET par Simon Gascoin
Pour contribuer à caractériser les conditions hydrométéorologiques lors de la crue torrentielle qui a frappé la Bérarde en juin, j’ai analysé une nouvelle série de cartes d’enneigement qui couvre la période 1984-2024 [1]. Grâce à la profondeur temporelle de cette série, on constate que l’altitude de la ligne de neige dans le bassin versant du […]
-
sur Stages 2025 !
Publié: 10 December 2024, 3:22pm CET par Jordan Serviere
Stages Geomatys pour 2025
- 10/12/2024
- Jordan Serviere
Geomatys propose pour 2025 deux nouvelles offres de stages :
 Montpellier – 3 à 6 mois
Montpellier – 3 à 6 moisTraitement de données géospatiales pour un outil cartographique de prédictions de risques d’émergence de maladies infectieuses
En savoir plusMontpellier – 3 à 6 mois Entre mars et septembre 2025
Entre mars et septembre 2025Développement d’un algorithme de Machine Learning pour la prévision des pics de turbidité
En savoir plus Menu
Linkedin
Twitter
Youtube
The post Stages 2025 ! first appeared on Geomatys.
-
sur Adapt’Action : contribuez au futur de Récolt'Ô, participez au Hackathon Open Booster
Publié: 10 December 2024, 3:00pm CET par Daphné Lercier
Le 30 octobre dernier, Récolt’Ô a été nommé lauréat des Data Challenges Adapt’Action. Pendant les 10 semaines du Hackathon à venir, nous unirons nos efforts pour accélérer le développement de communs numériques dédiés à l’adaptation au changement climatique?! ?
-
sur Les cafés géographiques d’Albi : programme 2023-2024
Publié: 9 December 2024, 5:29pm CET par Les Cafés Géo
Programme 2023-2024- 25 octobre 2023 : La géographie appliquée en bureau d’études : mieux accompagner les territoires dans leurs transitions ?, avec Brice Navereau, Géographe, Directeur de bureau d’études, Chercheur associé au Laboratoire LISST-CIEU (UMR 5193)
- 15 novembre 2023 : Cartographie et observation de la terre : nouveaux métiers, nouveaux usages ? avec Michaël Tonon et Frédéric Martorell (Responsable de l’équipe « Satellite Data Science » chez Airbus Defense et Espace et Responsable de l’Observatoire des territoires du Tarn à la DDT)
- 20 décembre 2023 : Jeux olympiques et aménagement urbain : des stades à la Cité ? avec Raphaël Languillon (Chercheur à l’Institut français de recherche sur le Japon à la Maison franco-japonaise de Tokyo, UMIFRE 19 MEAE-CNRS)
- 24 janvier 2024 : Le surtourisme : une réalité géographique ? avec Philippe Duhamel (Professeur des Universités en Géographie à l’UMR 6590 Espaces et Sociétés, Université d’Angers)
- 14 février 2024 : Technologie et Transhumanisme : une remise en question(s) du corps ? avec David Doat (Maître de conférences en philosophie, Université Catholique de Lille)
- 20 mars 2024 : La ville à l’épreuve du handicap ? avec Noémie Rapegno (Ingénieure de recherche à l’Ecole des hautes études en santé publique (EHESP) et membre du laboratoire Arènes (UMR 6051))
- 24 avril 2024 : La revanche du train ? avec Nacima Baron-Yelles et Pierre Messulam (Professeur des universités au Loboratoire Ville Mobilité Transport, Université Gustave Eiffel et Ancien Directeur de la Stratégie Ferroviaire, de la Recherche et de la Régulation de la SNCF)
Programme du colloque sur l’intelligence artificielle des 5 et 6 octobre 2023.
-
sur Lancement de Récolt’Ô, plateforme innovante pour encourager la récolte de l'eau de pluie en France
Publié: 9 December 2024, 9:14am CET par Amandine Boivin
Makina Corpus Territoires lance Récolt’Ô, une plateforme innovante dédiée à la valorisation de l’eau de pluie pour dimensionner la taille de la cuve nécessaire, en fonction de la superficie de toiture, la pluvi
-
sur Comparer les temps de trajets en Angleterre et au Pays de Galles de 1680 à nos jours
Publié: 6 December 2024, 5:08pm CET
Travelintimes est un planificateur de voyage historique, qui permet de planifier des voyages en Angleterre et au Pays de Galles vers 1680, vers 1830 et en 1911. Le site permet d'explorer la nature des déplacements et la façon dont ils se sont améliorés au cours du temps. Fondé sur des recherches historiques, il s'appuie sur les résultats de plusieurs projets de recherche conduits au sein de l'Université de Cambridge.
1) Un planificateur de voyage pour mesurer l'évolution historique des transportsLe planificateur de voyage est encore en phase de développement. Il permet pour l'instant les choix suivants :
- Planifiez un voyage à cheval à travers l'Angleterre et le Pays de Galles vers 1680 ;
- Planifiez un voyage en diligence à travers l'Angleterre et le Pays de Galles vers 1830 ;
- Planifiez un voyage en train à travers l'Angleterre et le Pays de Galles, en utilisant un vélo pour vous rendre à la gare la plus proche.
Un quatrième choix propose un itinéraire actuel basé sur la voiture, en utilisant OpenStreetMap, à titre de comparaison. Le planificateur permet de fixer son trajet entre deux points au choix sur la carte, de connaître le cas échéant la localisation des arrêts de nuit et de calculer le coût du voyage, exprimé de différentes manières (dans la monnaie et les prix de l'époque, en nombre d'heures de travail adulte non qualifié nécessaires pour payer le voyage, en monnaie actuelle en se référant aux heures de travail non qualifié du salaire minimum actuel).
2) Pourquoi ce choix de dates vers 1680, vers 1830 et en 1911 ?
Ces dates ont été choisies pour illustrer les aspects clés du développement des systèmes de transport. En 1680, l'amélioration du réseau routier apportée par les Turnpike Trusts (qui percevaient des péages) n'existait pas et l'ère moderne de la construction de canaux n'avait pas encore débuté. En 1830, le réseau de routes à péage était à son apogée, couvrant environ 20 000 miles, ainsi que le réseau de canaux. Le premier chemin de fer à vapeur pour passagers au monde, la ligne Liverpool-Manchester, a ouvert en 1830, mais en 1911, le réseau ferroviaire était à son apogée tandis que le vélo se répandait rapidement à partir des années 1890.
En 1680, l'état des routes était très mauvais et de nombreuses routes étaient impraticables aux véhicules à roues pendant une grande partie voire la totalité de l'année, ce qui faisait du déplacement à cheval (en amazone pour les femmes à cette époque) la seule alternative à la marche pour la plupart des voyages de passagers longue distance.
En 1830, il existait un réseau très étendu de routes à péage, qui permettaient de circuler même la nuit. Le réseau de lignes de diligences était très développé, ce qui permettaient à ceux qui en avaient les moyens de parcourir le pays beaucoup plus rapidement qu'en 1680 et dans un confort bien plus grand.
En 1911, grâce à un réseau ferroviaire dense, les déplacements à travers le pays étaient beaucoup plus rapides qu'en 1830, plus confortables, plus sûrs et moins chers. Les billets de troisième classe permettaient à une grande partie de la classe ouvrière de voyager en train. L'invention et la diffusion du vélo a également grandement démocratisé l'accès aux transports, les riches pouvant désormais se déplacer en voiture.
D'autres types de trajets, pour le fret de marchandises (notamment le charbon), seront ajoutés sur le site.
3) Un projet de recherche qui témoigne du « spatial turn » des recherches historiques
Les données à l'origine de ce site web ont été créées à partir d'une série de projets de recherche du département de géographie et de la faculté d'histoire de l'Université de Cambridge. Ces projets ont été financés par le Conseil de recherche économique et sociale, le Leverhulme Trust, la British Academy et l'Isaac Newton Trust (Cambridge).
Plusieurs projets ont été menés par le Dr Leigh Shaw-Taylor et le professeur Sir EA Wrigley entre 2003 et 2012, axés sur la reconstruction de la structure professionnelle de l'Angleterre et du Pays de Galles depuis la fin du Moyen Âge. Ils se sont assez rapidement intéressés au rôle des changements dans les infrastructures de transport, dans la géographie de la population et dans les structures professionnelles locales. À partir de 2006, le Dr Max Satchell a travaillé sur le projet qui a connu ensuite un « tournant spatial ». Avec des collègues en Espagne (dirigés par le professeur Jordi Marti-Henneberg), ils ont créé des cartes numériques du réseau ferroviaire et des gares pour chaque année de 1825 à 2010 à partir de l'atlas de Michael Cobb, The Railways of Great Britain. Max Satchell a ensuite créé des cartes des rivières et canaux navigables d'Angleterre et du Pays de Galles pour chaque année de 1600 à 1947. En 2012, ils ont lancé un nouveau projet financé par le Leverhulme Trust avec le professeur Dan Bogart (Université de Californie à Irvine) qui a obtenu un financement supplémentaire de la National Science Foundation américaine. Le Dr Xuesheng You, Mme Annette MacKenzie, le Dr Eduard Alvarez et le Dr Alan Rosevear ont rejoint l'équipe. Satchell et Rosevear ont cartographié les routes à péage pour chaque année de 1660 jusqu'à la disparition finale du système en 1897. Satchell, Alvarez et d'autres chercheurs ont créé des cartes des ports et des routes de navigation côtière.
Alvarez a connecté tous les réseaux de transport pour produire une version « multimodale » avec trois dates de référence (vers 1680, vers 1830 et en 1911). Cette dernière étape a reposé sur l'utilisation d'un logiciel d'analyse de réseau pour étudier les caractéristiques du réseau et modéliser les trajets. Les chercheurs espèrent que ce site web intéressera le grand public et qu’il sera largement utilisé à des fins d’enseignement en histoire et en géographie dans les écoles et les collèges.
4) Références scientifiques
L. Shaw-Taylor, D. Bogart et AEM Satchell. The Online Historical Atlas of Transport, Urbanization and Economic Development in England and Wales c.1680-1911 [Atlas historique en ligne des transports, de l'urbanisation et du développement économique en Angleterre et au Pays de Galles vers 1680-1911]. TravelinTimes.org
Chapter 1. Navigable waterways and the economy of England and Wales 1600-1835
Max Satchell (2017)Chapter 2. The Turnpike Roads of England and Wales
Dan Bogart (2017)
Chapter 3. The development of the railway network in Britain 1825-1911
Dan Bogart, Leigh Shaw-Taylor and Xuesheng You (2018) : L. Shaw-Taylor, D. Bogart and A.E.M. Satchell
Articles connexes
Cartographie du choléra à Londres et en Angleterre à l’époque victorienne
Plus de 400 000 photographies aériennes mises en ligne par les archives historiques de l'Angleterre
Se déplacer en ville : quatre siècles de cartographie des transports en commun à Boston
MetroDreamin', une application en ligne pour imaginer le système de transports que vous aimeriez pour votre ville
Temps de trajets vers les grands centres urbains à l’échelle du monde
Construire et analyser des cartes isochrones
Explorer la cartographie des réseaux de transports publics avec des données GTFS
-
sur Bilan des activités de l’organisme de formation Makina Sapiens 2018-2023
Publié: 6 December 2024, 3:52pm CET par Cécile Chardonneau
Makina Sapiens, entité de formation de Makina Corpus, a connu une évolution marquante au cours des cinq dernières années.
-
sur Regard d’Altitude : un outil open source pour comprendre et agir face aux risques en montagne
Publié: 5 December 2024, 10:00am CET par Bastien Potiron, Stéfanie Ribeiro, Bastien Alvez, Jean-Etienne Castagnede
Image
-
sur Café géo de Paris, 17 décembre 2024 : Géohistoire des humains sur la Terre, avec Christian Grataloup
Publié: 4 December 2024, 12:16pm CET par r.a.
Mardi 17 décembre 2024, de 19h à 21h
Café de Flore, 172 Boulevard Saint-Germain, 75006 Paris (salle du premier étage)
 On ne présente plus Christian Grataloup, professeur émérite à l’université Paris-Diderot, qui ne cesse d’approfondir la réflexion géohistorique. Il vient d’ailleurs de faire paraître aux éditions des Arènes un nouvel opus de la collection d’atlas historiques qu’il dirige, cette fois-ci avec Pierre Léna (Atlas historique du ciel, Les Arènes, 2024).
On ne présente plus Christian Grataloup, professeur émérite à l’université Paris-Diderot, qui ne cesse d’approfondir la réflexion géohistorique. Il vient d’ailleurs de faire paraître aux éditions des Arènes un nouvel opus de la collection d’atlas historiques qu’il dirige, cette fois-ci avec Pierre Léna (Atlas historique du ciel, Les Arènes, 2024).C’est l’occasion pour nous de revenir sur son maître-livre Géohistoire (Les Arènes, 2023) où il dessine une formidable histoire des sociétés humaines. Merci à Christian Grataloup d’avoir accepté l’invitation des Cafés géographique pour nous éclairer sur cet immense sujet.
-
sur Retour sur le SotM 2024
Publié: 3 December 2024, 2:00pm CET
 Romain Lacroix était au State of the Map France 2024 à Lyon et nous livre ce qui l'a marqué et ce qu'il a retenu.
Romain Lacroix était au State of the Map France 2024 à Lyon et nous livre ce qui l'a marqué et ce qu'il a retenu.
-
sur Les frontières n’en finissent pas de tuer
Publié: 3 December 2024, 9:58am CET par Nicolas Lambert
Depuis le début des années 2000, près de 68 000 personnes — femmes, hommes et enfants — ont péri en tentant de rejoindre l’Europe, un nombre équivalent à la population d’une ville comme Calais, Colmar, Bourges ou Valence. Noyades, asphyxies, accidents, écrasements, empoisonnements, explosions sur des champs de mines, morts de faim, de soif, d’épuisement, absence de soins médicaux, violences policières, etc. : autant de tragédies humaines qui auraient pu être évitées. Ces vies brisées sont le lourd tribut d’une politique migratoire marquée par l’indifférence et la répression, là où la solidarité aurait pu offrir à tout le monde un autre destin. Ces décès constituent une manifestation aussi évidente que tragique de la vulnérabilité des migrants et de violence des politiques migratoires qu’ils subissent.
Une histoire en cartesEn 2002, le géographe Olivier Clochard, chercheur au laboratoire Migrinter et fondateur du réseau Migreurop, réalisait la toute première carte des morts de la migrations (voir). À cette époque, aucune source officielle ne recensait les décès liés aux migrations. Ce travail inédit et pionnier s’appuie alors sur les données de l’organisation néerlandaise UNITED against Racism et celles de l’association des amis et des familles des victimes de l’immigration clandestine (AFVIC). Cette carte marque un tournant : elle déplace le regard du fait divers vers une lecture géographique et systémique. Elle rend visible une réalité jusqu’alors fragmentée, exposant la logique implacable et territoriale de la répression aux frontières. La carte montre que ces décès ne sont pas des incidents isolés, mais le résultat d’un système qui se dévoile à travers des lieux clés : le détroit de Gibraltar, le détroit de Sicile, le canal d’Otrante, la mer Égée, etc. À partir de 2004, Olivier Clochard enrichit cette carte en collaboration avec Le Monde diplomatique. Ce partenariat lui confère alors une résonance inédite, transformant cette carte en une arme politique majeure.
Au fil du temps, de nouvelles sources de données apparaissent. D’abord, l’incroyable travail du journaliste italien Gabriele Del Grande, qui, à travers son blog Fortress Europe, raconte ces drames invisibilisés aux frontières de l’Europe. Puis, en 2014, c’est l’émergence du projet de data journalisme “The Migrant’s file”, qui s’illustre par son remarquable travail de vérification des faits. Aujourd’hui, les données proviennent en grande partie du projet Missing Migrants de l’Organisation Internationale pour les Migrations (OIM), consolidant ainsi une cartographie plus précise et plus complète.
Grâce à ces nouvelles données, la “carte des morts” a été mise à jour à plusieurs reprises par le réseau Migreurop, en 2009, 2012, 2015 et 2017. À chaque révision, la géographie de la frontière migratoire se précise, se dessine, se réorganise, à mesure que les dispositifs de contrôle se renforcent. Mais ces dispositifs, loin de freiner les migrations, n’ont pour effet que de dévier les routes migratoires, les rendant toujours plus périlleuses. Oui, il faut le dire haut et fort : ce sont bien ces politiques migratoires, cruelles et inefficaces, qui portent la responsabilité de cette hécatombe silencieuse. Dans ce billet, dans la lignée des travaux du réseau Migreurop, nous proposons une actualisation de cette carte selon les mêmes codes. L’échelle temporelle choisie est 1993 – 2024, mais libre à vous de la faire varier en cliquant ici.

Source : [https:]]
La liberté de circulation en questionEn 1952, dans Peau Noire, Masques Blancs, Frantz Fanon écrivait les mots suivants : « Il ne faut pas essayer de fixer l’Homme, puisque son destin est d’être lâché ». Cette phrase résonne ici avec force. Oui, depuis la préhistoire, l’humanité s’est toujours déplacée à la surface du globe, mais également sous l’eau et dans l’espace. La mobilité fait partie intégrante de l’histoire humaine. Ce qui l’est moins, c’est cette volonté d’empêcher ces mouvements. Notez, qu’ils ne sont pas empêchés pour tous. Il est très facile de traverser les frontières et voyager à travers le Monde dès lors que l’on est un riche habitant d’un pays riche. Mais cette mobilité est systématiquement entravée pour les ressortissants des pays du Sud. La frontière est donc profondément inégalitaire et dissymétrique. Elle matérialise un rapport de domination entre les pays du Nord et les pays du Sud. Alors que faire ? Bien sur, contester cet ordre mondial. Mais aussi, rappeler que le lieu de naissance est un hasard de la vie. Qu’il n’y a pas de crise migratoire mais une crise de l’accueil et de la solidarité. Et comme dirait Patrick Chamoiseau, rappeler que nos “frères migrants” ne sont pas des menaces mais des camarades de luttes. Une conclusion s’impose. Elle se résume en ces deux points : Prolétaires de tous les pays unissez-vous. Liberté de circulation et d’installation pour toutes et tous.
Article à retrouver également sur l’Humanité.fr : [https:]]
Ingénieur de recherche CNRS en sciences de l'information géographique. Membre de l'UMS RIATE et du réseau MIGREUROP / CNRS research engineer in geographical information sciences. Member of UMS RIATE and the MIGREUROP network.
Follow Me:


-
sur (En) [Story] Oslandia x QWC : épisode 7 / 8
Publié: 3 December 2024, 6:17am CET par Caroline Chanlon

Désolé, cet article est seulement disponible en Anglais Américain.
-
sur Nos projets nominés aux Trophées Innovation et Makina Corpus participe aux Aqua Business Days
Publié: 2 December 2024, 11:00am CET par Amandine Boivin
Makina Corpus participe aux Aqua Business Days 2024, un événement dédié à l’innovation dans le domaine de l’eau, avec deux projets nominés pour les Trophées Innovation.
-
sur Le dessin du géographe n° 102. Michel Sivignon : une géographie sensible
Publié: 2 December 2024, 10:54am CET par r.a.
Michel Sivignon a disparu au printemps dernier.
Parmi les multiples facettes de son œuvre de géographe, la rubrique « Le Dessin du Géographe » du site internet des Cafés Géographiques tient une place à part qui révèle un peu une face cachée de son talent. Par-delà une grande érudition, un souci de recherche des nœuds entre géographie, histoire et cultures, il prenait le dessin comme un moyen de développer une géographie spontanée (comme il l’a décrite dans un texte de Géographie Humaine de 2016).

Michel Sivignon croqué par Roland Courtot au cours de l’excursion de géographie rurale en Thessalie en 2001 (Le Dessin du Géographe n°81, 2020)
« Le Dessin du Géographe »
Michel Sivignon a créé avec Roland Courtot cette rubrique originale portée par les Cafés Géographiques. Au demeurant peu académique, cette série est destinée à mettre en valeur les croquis et dessins dont nombre de géographes anciens ou plus récents se sont servi pour explorer un paysage, nourrir leurs analyses ou pour illustrer leur propos. La série compte désormais une centaine de livraisons.

Un caïque à Volos (Grèce). Aquarelle de Michel Sivignon publiée dans la rubrique « cartes postales » des cafés géographiques en 2006
Si Michel Sivignon dessinait beaucoup à côté de ses recherches de géographie rurale, historique et culturelle, il n’a, par modestie, publié aucun de ses dessins dans la rubrique du dessin du géographe. Le seul qu’héberge le site de l’association des Cafés Géographiques se trouve sur une autre rubrique, celle des cartes postales.
A côté de ses recherches de géographie rurale, historique et culturelle, Michel Sivignon dessine beaucoup. Mais ses dessins ne figurent pas dans la rubrique. Quelques croquis de voyage au japon et en Italie qui nous ont été confiés par Michèle, son épouse, pourront ici illustrer son talent.
Michel Sivignon a développé une géographie sensible. Le dessin est pour lui un outil formidable pour appréhender le monde qu’il parcourt. De la Thessalie autour de son ancrage à Volos, jusqu’aux aux nombreux voyages de recherche ou de loisirs, le carnet et le crayon sont ses outils. Sa perception s’attache à donner sens aux paysages, aux constructions ou aux pratiques sociales. Son regard éclaire aussi les personnages qu’il pouvait croiser. Et il a du talent pour exécuter rapidement des paysages ou des scènes observées. La palette de Michel est variée. Dessinateur infatigable, son œil accroche ce qui éclaire la scène, et son trait est plein de générosité et d’humour.
PaysagesAu cours d’un voyage au Japon, voici la région d’Hiroshima

Une aquarelle réalisée à partir sommet de l’île de Itsukushima, en face d’Hiroshima. Dessin de Michel Sivignon
Quelques arbres au premier plan, quelques îlots dans la mer du Japon, un lointain de collines. Le paysage est simple et apaisé. Il s’accompagne de notes évoquant la bombe atomique de 1945 et l’histoire d’une survivante. Ces quelques phrases font entrer dans la mémoire directe du bombardement. 
Un croquis d’Osaka vue d’une tour. Michel Sivignon
La vue du centre-ville d’Osaka à travers Google Earth
Un petit croquis rapide pour une vue plongeante depuis une grande tour située au-dessus de la « gare gigantesque » d’Osaka, trace un faisceau d’autoroutes urbaines et de ponts ferroviaires sur la rivière. On devine une rame de train, les rives vertes au milieu d’un monde tours qui se concentrent sur les deux rives du fleuve. Cette sorte de gribouillis place les éléments du centre-ville avec son réseau d’autoroutes.
Scènes de vie sociale et culturelle
Un dessin de rizières étagées sous le grand sanctuaire shinto de Ise près de Matsuaka (à l’Est d’Osaka). Dessin de Michel Sivignon
Le cayon retient un temple mineur intégré dans le paysage rural. Une image pour comprendre la culture à travers un paysage. C’est l’économie du trait, qui donne force au schéma dans un paysage reconstruit.
Des scènes de vie quotidienne
Des personnages croisés dans le train pour Ise et des notes sur la culture Shintoïste. Dessin de Michel Sivignon
Le dessin rapide reste moins intrusif vis-à-vis du sujet qu’une photographie prise à la volée. Le crayon présente des personnages dont la silhouette se télescope avec les notes éparses dans une recherche des traces de l’histoire culturelle japonaise
Le Dessin du Géographe : du projet à la série
Une scène matinale dans le train vers Takamatsu (dans l’île de Sikoku) et un tampon des portes du parc de Ritsurin crée à l’époque Edo. Dessin de Michel Sivignon
Cette image montre le souci de saisir un moment de la vie japonaise entre vie quotidienne et sites culturels. « Un certain nombre de géographes dessinent lors d’excursions sur le terrain ou de missions scientifiques. Certains en ont même fait une activité régulière, et en illustrent leur production. Mais cette activité demeure presque confidentielle. Beaucoup de dessins restent dans les tiroirs, n’ayant bénéficié que d’un regard furtif et admiratif des collègues qui jettent un coup d’œil sur le carnet. » ainsi s’ouvre la série du « Dessin du Géographe »
Le projet de la rubrique est donc de mettre en valeur des croquis de terrain ou des esquisses plus élaborées qui ponctuent les travaux de certains géographes. Cette initiative se veut à contre-courant de la tendance actuelle des universitaires à multiplier les prises de vue par photographie ou cinéma, à construire des raisonnements sur des plan zonés, des images satellitaires, des diagrammes statistiques sans lien immédiat avec le réel sensible.
Les livraisons reprennent les dessins d’anciens maitres comme des croquis de Paul Vidal de La Blache ou des blocs-diagramme de Emmanuel De Martonne, ou encore des paysages ruraux de Pierre Deffontaines. Ce sont aussi des croquis d’artilleurs qui replacent les images dans le champ de l’histoire. Ou encore des images métaphoriques illustrant des ouvrages généraux. Ainsi les Dessins du Géographe tracent une trajectoire de croquis à travers plus d’un siècle. La rubrique a offert une place à des générations différentes de géographes, des gens venus d’horizons différents (graveurs, affichistes, archéologues…), et des dessins de nature différente (caricature, illustration de manuel). C’est un lieu de rencontre des images, des perspectives, des questionnements des géographes ou d’autres qui ont appréhendé une portion du monde par des outils graphiques. Il s’agit aussi de faire connaitre des travaux originaux à travers un outils qui n’est pas démodé, le carnet et le crayon. Il s’agit encore de susciter les gribouillis, les croquis de terrain, les schémas qui font naitre les idées par-delà le discours académique. Le carnet de terrain peut ainsi être exposé et prendre sa place dans les perspectives sensibles de l’enquête, les interrogations et même esquisser des interprétations.
La série dans sa diversité met en valeur l’outil graphique comme moyen de perception et d’échange autour des paysages ou de scènes sociales. C’est aussi un support pour des constructions ou des reconstructions, voire de modèles empiriques d’un espace.
Le Dessin du Géographe est conçu par Michel Sivignon avec Roland Courtot pour accueillir les images dans leur diversité pour en expliciter le sens. Il est finalement resté très pudique avec ses propres dessins et s’est attaché à valoriser ceux des autres. Il y avait là une vraie générosité. La rubrique, au fil des livraisons, s’est construite comme une défense et illustration du dessin. Elle a rassemblé avec une grande ouverture d’esprit des images riches de sens qui éclairent la diversité de la démarche géographique.
Michel Sivignon a ouvert une fenêtre, une belle fenêtre, où s’établit un dialogue entre géographie, culture et histoire autour de dessins plus ou moins aboutis, mais qui sont riches de sens. Ces rencontres qui passent autant par l’image que par les mots pourront se donner un bel avenir.
Nous sommes reconnaissants à Michel Sivignon de la réussite de son projet.

Une rue de Bologne (Italie) dessin et lavis de Michel Sivignon
Cette image montre l’économie du trait et le jeu des volumes pour saisir cet espace construit. La perspective inscrit l’histoire dans cette rue. Elle traduit aussi une certaine recherche esthétique.
Charles Le Cœur, Roland Courtot et Simon Estrangin, novembre 2024






-
sur Sixième édition du défi cartographique #30DayMapChallenge (novembre 2024)
Publié: 30 November 2024, 3:37pm CET
La 6e édition du défi cartographique du #30DayMapChallenge s'est terminée fin novembre 2024. Lancé en 2019 par Topi Tjukanov, un cartographe finlandais, le défi est devenu au fil des années un projet de cartographie sociale qui se déroule chaque année au mois de novembre. L'édition 2024 introduit des thèmes nouveaux concernant la cartographie collaborative, les conflits, la mémoire, la planète bleue, le micomapping, les heatmaps. L'Arctique remplace l'Antarctique qui était au défi de l'an dernier, deux couleurs remplace noir & blanc. Une place importante est réservée aux données (Data : HDX - Data : my data - Data : OpenStreetMap - Data : overture). Enfin le dernier challenge (The final map) laisse une grande liberté.
Les réalisations peuvent être retrouvées à partir du hashtag #30DayMapChallenge sur différents réseaux sociaux :30 cartes pour voir le territoire autrement (IGN)
[https:]]#30DayMapChallenge J29 ??#OVERTURE
— IGN France (@IGNFrance) November 29, 2024
Pourquoi partir à l'autre bout du monde quand on peut simplement se rendre dans le massif des Bauges ?
Avec ses 14 sommets de plus de 2000 m, il est surnommé "Le Petit Himalaya", en référence aux 14 sommets de plus de 8000 m de la chaîne de… pic.twitter.com/NXFf9m5pRz#30DayMapChallenge day 30: c'est fini ?
— Jean-Marc Viglino (@jmviglino) November 30, 2024
? J'ai fait 2??4?? cartes, dont 3 avec @IGNFrance
? visible sur mon #github ?? [https:]]
? Thanks everyone for the beautiful maps, as usual#mappymeme #cartography #geomatique pic.twitter.com/RnBuNFbMac#30DayMapChallenge, Day 30, The final map:
— Georgios Karamanis (@geokaramanis) November 30, 2024
A basketball globe with cities with population >5000
Code: [https:]] #dataviz #map #Rstats pic.twitter.com/MNi7GsRKCkSuperficie de l'Algérie : 2 382 000 km²
Superficie du Groënland : 2 166 000 km²
— Kevin Prieur (@KevinGis) November 26, 2024
Si vous êtes curieux, découvrez ce site : [https:]] #ArcGIS #Maps pic.twitter.com/cBghJf5osEAnother masterpiece from Jo Wood. His #30DayMapChallenge 2024 is absolutely incredible. Very inspiring. #Observable #JavaScript #VintageCartography [https:]] pic.twitter.com/kaU1CGA8wp
— Nicolas Lambert (@neocartocnrs) November 27, 2024Cette carte animée depuis #ArcGIS Online se base sur les données du modèle numérique d'évolution de l'océan établi par l'HYCOM.#Cartographie #Ocean pic.twitter.com/reU8AJi9or
— Kevin Prieur (@KevinGis) November 28, 2024#30DayMapChallenge Jour28/ Day28 - Planète bleue / Bonne journée de la Méditerranée pic.twitter.com/8HUEJdLZvr
— Joseph Benita (@JsphBen) November 28, 2024
Articles connexes
Cinquième édition du défi cartographique #30DayMapChallenge (novembre 2023)
Quatrième édition du défi cartographique #30DayMapChallenge (novembre 2022)
Troisième édition du défi cartographique #30DayMapChallenge (novembre 2021)
Deuxième édition du défi cartographique #30DayMapChallenge (novembre 2020)
Un défi cartographique de 30 jours en novembre 2019 (#30DayMapChallenge)
Le #30DayChartChallenge, un défi communautaire pour réaliser la meilleure datavisualisation
Les cartes et data visualisations de Topi Tjukanov : entre art et cartographie
La cartographie du monde musulman et ses nombreux mapfails
Vidéos des présentations au congrès cartographique NACIS 2022
Comment différencier infographie et data visualisation ?
-
sur La carte de Cassini embellie sur le site du Géoportail
Publié: 29 November 2024, 7:31pm CET
Source : « Une nouvelle version interactive de la carte de Cassini, la première carte intégrale du royaume (XVIIIe siècle), a été mise en ligne sur le Géoportail » (BNF-IGN, Communiqué de presse du 28 novembre 2024).
- Lien vers le Géoportail (Cartes >> Culture et patrimoine >> Carte de Cassini)
- Lien vers Ma Carte IGN (avec liens directs à partir du tableau d'assemblage)
La Bibliothèque nationale de France (BnF) et l’Institut national de l’information géographique et forestière (IGN) ont noué un partenariat afin de rendre accessible sur le Géoportail, portail web permettant l’accès à des services de recherche et de visualisation de données géographiques ou géolocalisées, une nouvelle version numérisée de la célèbre carte de Cassini. Il s’agit de la première carte générale et détaillée du royaume de France réalisée entre 1756 et 1815 par la famille de cartographes Cassini.
La "Carte générale de la France" est réalisée par la famille de cartographes Cassini entre 1756 et 1815. L’exemplaire conservé @laBnF est aquarellé à la main (1780). Chaque feuille est découpée en 21 rectangles collés sur une toile de jute pour permettre le pliage et le transport pic.twitter.com/Xh199eCOoc
— Bibliothèque BnF (@laBnF) November 28, 2024Composée de 180 feuilles accolées, cette carte exceptionnelle conservée au département des Cartes et plans de la BnF, est l’un des rares exemplaires aquarellés à la main réalisé dans les années 1780. Elle donne une vision d’ensemble du royaume dans ses frontières de l’époque, ce qui explique l’absence de Nice, de la Savoie et de la Corse, mais aussi la présence de villes aujourd’hui belges, luxembourgeoises ou allemandes. Chaque feuille a été découpée en 21 rectangles collés sur une toile de jute afin d’en permettre le pliage et le transport. Grâce à ce partenariat, les utilisateurs peuvent naviguer de façon interactive à travers une version assemblée de la carte, tout en la superposant à des cartes modernes ou à des prises de vues aériennes actuelles. Cette version est de bien meilleure qualité, avec une résolution et un contraste plus importants que celle diffusée précédemment sur le Géoportail. Numérisée en 2015 par la BnF en haute résolution, la Carte de Cassini est également accessible sur Gallica la bibliothèque numérique de la BnF, ainsi que sur l’application mobile Cartes IGN et le site « Remonter le temps ».
Déjà numérisée en 2015 par @laBnF en haute résolution, la Carte de Cassini est également accessible sur @GallicaBnF et sur l’application mobile Cartes @IGNFrance et le site « Remonter le temps » : [https:]]
— Bibliothèque BnF (@laBnF) November 28, 2024La nouvelle version est vraiment plus précise. La possibilité de zoomer sur des traits permet de placer les moulins, notamment, avec plus de précision. Toutefois les versions ayant été aquarellées à la main ont parfois des petites différences qui méritent d'être comparées ponctuellement. La carte de Cassini intégrée dans le Géoportail est la version en couleur (feuilles gravées et aquarellées) issue de l’exemplaire dit de « Marie-Antoinette » du XVIIIe siècle. La légende qui accompagne la carte de Cassini sur le Géoportail vaut le coup d'oeil par la précision et la beauté de ses symboles (à télécharger en pdf). Jean-Marc Viglino en a tiré une police svg utilisable dans un SIG.
Au même titre que les autres couches du Géoportail, la carte de Cassini peut être intégrée dans un SIG sous la forme de flux WMTS (voir les Geoservices WMS/WMTS sur le site de l'IGN). Exemple ici d'intégration de la carte dans QGIS.
On ne dispose pas de cartes de Cassini pour l'outre-mer. Le Géoportail comporte malgré tout une belle carte du XVIIIe siècle pour la Guyane. En toute logique, le Géoportail devrait mettre d'autres cartes du XVIIIe pour les autres territoires d'outre-mer. Pour la Corse, il y a le plan Terrier du XVIIIe disponible via les Géoservices de l'IGNPour compléter
« Portrait cartographique du Royaume de France : l’aventure des Cassini » (La Fabrique de l'Histoire).
Au XVIIIe siècle, la France a vu naître une œuvre cartographique sans précédent : la carte de Cassini, la première représentation géométrique et topographique de tout le territoire national. Réalisée sur plus de 70 ans par quatre générations d’une même famille d’astronomes et cartographes, cette carte est bien plus qu’un simple outil : elle est un témoignage historique, scientifique et technique unique. Débutée sous Louis XV, la carte de Cassini a marqué une rupture avec les anciennes méthodes. Grâce à des techniques comme la triangulation et des relevés sur le terrain, elle a permis de produire une carte rigoureuse et détaillée. Ses créateurs ont relevé de nombreux défis, alliant innovation scientifique, observation astronomique et expertise topographique. La carte de Cassini ne se contente pas de montrer les frontières et les routes : elle représente les clochers, moulins, forêts, cours d’eau, et autres éléments essentiels à la vie des territoires. Elle reflète une vision civique et scientifique, tout en ayant une utilité militaire stratégique. Aujourd’hui, les avancées numériques permettent de superposer les cartes de Cassini aux représentations modernes, offrant un regard unique sur l’évolution des territoires. Un véritable trésor scientifique et culturel pour comprendre le passé et planifier l’avenir. La carte de Cassini témoigne de valeurs de persévérance et de transmission. Ce projet ambitieux, fruit de décennies de travail, continue d’inspirer par sa précision et son utilité. Une nouvelle version interactive est désormais accessible sur le Géoportail de l’IGN.
« Naviguer dans les cartes de Cassini avec Eve Netchine et Bernard Bèzes « (France Culture)
La carte de Cassini, première représentation cartographique du royaume de France établie en 1744, a été numérisée pour la première fois de façon continue. Comment cette carte a-t-elle été créée ? Comment a-t-elle, au cours de l'histoire, façonné notre représentation du territoire ?Articles connexes
L'histoire par les cartes : histoire du quartier Richelieu à Paris (1750-1950)
Plans et rues de Paris d'hier à aujourd'hui
Parcours guidé dans le plan routier de la ville et des faubourgs de Paris en 1789 (Gallica - BnF)
L'histoire par les cartes : Gens de la Seine, un parcours sonore dans le Paris du XVIIIe siècle
L'histoire par les cartes : une cartographie historique du Paris populaire de 1830 à 1980
Les plans historiques de Paris de 1728 à nos jours (APUR - Cassini Grand Paris)
Cartes et atlas historiques
-
sur Café géo de Montpellier, 5 décembre 2024 : Les deux quartiers gare de Montpellier : regards croisés urbanismes-transport
Publié: 29 November 2024, 4:35pm CET par Les Cafés Géo
avec Laurent Chapelon et Alexandre Brun
jeudi 5 décembre 2024: Gazette Café, 6 rue Levat, Montpellier, 18H
-
sur Revue de presse du 29 novembre 2024
Publié: 29 November 2024, 2:00pm CET
 Une GeoRDP bourrée de hashtags, en plein #30DayMapChallenge, à lire avec son smartphone orienté vers le Sud
Une GeoRDP bourrée de hashtags, en plein #30DayMapChallenge, à lire avec son smartphone orienté vers le Sud
-
sur Eclairez vos terrains avec Giro3D
Publié: 28 November 2024, 6:47am CET par Sébastien Guimmara
Pièce jointe: [télécharger]
Cet article concerne des fonctionnalités en cours de développement et sujettes à évolution.
L’éclairage dans Giro3DL’éclairage est un élément déterminant dans une scène 3D, et permet d’améliorer la lisibilité des volumes et du relief, notamment du terrain.
Giro3D dispose de deux modes d’éclairage pour les terrains: simplifié et réaliste.
L’éclairage simplifié (hillshading) Ce mode d’éclairage n’est compatible qu’avec l’entité Map dans un système de coordonnées projeté.Il s’exprime par un couple de valeurs (azimut, zénith) décrivant la position du soleil telle que perçue depuis le centre de la scène. C’est un mécanisme très similaire à celui proposé par QGIS par exemple.
L’avantage de ce système est qu’il est très simple d’emploi, et familier des utilisateurs d’outils cartographiques.
Son inconvénient majeur, en revanche, est qu’il ne fonctionne pas avec le mode globe, puisque l’axe des rayons du soleil n’est pas le même en tout point du globe (alors qu’il l’est en tout point d’une carte plane).
Son autre inconvénient est l’absence de support de multiples sources lumineuses ainsi que les ombres portées.
Une couche d’élévation sans éclairage actif

La même couche éclairé par l’éclairage simplifié
L’éclairage réaliste Ce mode d’éclairage n’était jusqu’ici pas supporté par l’entité Map.Le mode d’éclairage réaliste utilise les mécanismes du moteur three.js comme l’éclairage physiquement réaliste et les ombres portées pour produire une scène plus réaliste.
Ce système permet d’utiliser un nombre arbitraire de sources lumineuses représentées par des objets 3D:
- Lumière d’ambiance permettant de simuler une lumière douce sans source précise comme le ciel,
- Lumière directionnelle permettant notamment de simuler la lumière du soleil,
- Lumières ponctuelles permettant de simuler des sources lumineuses comme les lampadaires ou autre éclairage artificiel local.

La même couche d’élévation éclairée par une lumière directionnelle, une lumière d’ambiance et des ombres portées
Les ombres portéesLe système d’éclairage réaliste permet également de visualiser des ombres portées ouvrant la voie à de nombreux cas d’usage, comme par exemple:
- visualisation de l’ensoleillement d’une vallée à une heure donnée,
- visualisation des ombres portées par des bâtiments sur une rue
Les ombres portées par le Grand Canyon se combinent à celle de la sphère
ConclusionLe support complet de l’éclairage three.js pour l’entité Map s’inscrit dans la philosophie de Giro3D de s’intégrer de façon aussi transparente que possible à l’écosystème three.js.
Les ombres portées représentent une addition intéressante pour améliorer la qualité visuelle des scènes et aider à la prise de décision lors des analyses d’ensoleillement.
Vous retrouverez toutes les fonctionnalités de Giro3D sur le site web et sur la page d’exemples interactifs.
Si vous souhaitez en savoir plus, intégrer Giro3D dans votre système d’information, utiliser ces fonctionnalités pour de nouveaux usages, n’hésitez pas à contacter notre équipe à infos+3d@oslandia.com ! Nous serons ravis d’échanger avec vous.
-
sur [EXPO] “Migrations, une odyssée humaine” au Musée de l’Homme à Paris
Publié: 27 November 2024, 10:43pm CET par Françoise Bahoken
 Le Musée national d’histoire naturelle (Musée de l’Homme) à Paris propose une exposition temporaire sur les mouvements de populations qui façonnent l’espace de nos sociétés depuis la préhistoire. Justement intitulée Migrations : une odyssée humaine [Accéder au site…], cette exposition multiplie les regards et les points de vue sur ce sujet qui est actuellement très malmené dans l’actualité : dans la voix des autorités et par une grande partie des médias qui les suivent.
Le Musée national d’histoire naturelle (Musée de l’Homme) à Paris propose une exposition temporaire sur les mouvements de populations qui façonnent l’espace de nos sociétés depuis la préhistoire. Justement intitulée Migrations : une odyssée humaine [Accéder au site…], cette exposition multiplie les regards et les points de vue sur ce sujet qui est actuellement très malmené dans l’actualité : dans la voix des autorités et par une grande partie des médias qui les suivent.
Cette exposition déconstruit ainsi des idées reçues, remet en perspective des processus migratoires anciens et contemporains et montre l’indéniable enrichissement liés aux métissages [voir Billet] qui en émanent.Loin d’être un phénomène nouveau, les migrations ont façonné notre humanité. Elles font partie de notre passé, notre présent et notre avenir, sans oublier l’ensemble du vivant.
L’exposition est très ancrée dans notre époque, à la fois dans son style et sa muséographie. Elle propose des dispositifs variés permettant au public de se re présenter lui même des migrations humaines et leurs enjeux, en termes d’accueil par exemple, comme pour ressouder un peu nos liens. Elle présente des mots de notre vocabulaire français, ceux de la migration bien sûr (expatrié/migrant…) et ceux qui tissent et maintiennent nos liens avec l’ailleurs ; des objets de notre quotidien : de noter alimentation (les café/thé, le piment d’Espelette, le manioc entre autres), ceux qui nous accompagnent ou encore ceux qui témoignent de nos mélanges. J’avais hâte de découvrir l’histoire de ces dents datant de 54 000 ans qui rappellent la cohabitation ancienne – en France – de diverses populations. L’exposition remonte en effet aux premières migrations historiques de l’Homo Sapiens parti d’Afrique qu’elle explore, après avoir posé son regard sur des mobilités plus contemporaines, des parcours de vie individuels à écouter ou bien à voir, pour mieux nous projeter, nous rendre compte de cette expérience particulière du voyage qu’est la migration et qui n’est jamais anodin.
Regards sur les Cartes
L’exposition s’ouvre par une section dédiée aux Cartes, à laquelle Nicolas Lambert et moi-même avons contribué. Elle propose un éclairage sur cinq cartographies de migrations, qu’elles soient historiques comme les remarquables “Carte figurative et approximative représentant pour l’année 1858 les émigrés du globe” de Charles-Joseph Minard (1862) et “Courants migratoires” de Georg Ernst Ravenstein (1885), ou plus contemporaines, telle celle qui représente le parcours de Wyem depuis Kaboul à Hambourg en Allemagne, précédemment publiée dans l’Atlas des migrants (Migreurop, 2017), ou celle sur des Ukrainien.nes ayant trouvé refuge dans un pays limitrophe, actuellement exposée au Palais de la porte dorée (Musée nationale de l’Histoire de l’Immigration), mais actualisée (novembre 2024) pour l’occasion.

Cliché : N. Lambert, 2024.
A noter la nouvelle version de la carte de Wyem dissociée de celle de Frontex (située juste au-dessus) et présentée seule, avec un nouveau nom – la version précédente étant disponible en ligne dans l’exposition Expériences migratoires réalisée dans le cadre du colloque international Cartographier les mobilités (2020).
Le parcours de Wyem face aux flux de Frontex
 Cliché : F. Bahoken, 2024
Cliché : F. Bahoken, 2024Un dispositif multimédia de cartographie complète cet espace. Il appelle le public à venir jouer pour faire une carte, sa propre carte, sur des migrations … syriennes. L’exemple proposé s’appuie en effet sur l’exercice de cartographie critique Méfiez-vous des cartes, pas des migrants (voir) qui est mis en scène par un bonhomme-globe qui guide les publics dans leurs intensions cartographiques, ci-dessous pour le choix des couleurs des cercles.
 Cliché : F. Bahoken, 2024
Cliché : F. Bahoken, 2024Les cartes font partie des modes de représentation privilégiés des migrations y compris dans cette exposition qui fait d’ailleurs la part belle à des modalités de présentation sortant de l’ordinaire. Mais je ne vais pas tout spoiler ! Alors, j’arrête là pour vous laisser prendre votre bâton de pèlerin pour prendre la route vers cette odyssée, si vous le pouvez, bien sûr.
 Cliché : F. Bahoken, 2024
Cliché : F. Bahoken, 2024Billet lié :
Méfiez-vous des cartes, pas des migrants : les réfugiés syriens.Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.


-
sur Conférence des Cafés Géo de Paris, 30 novembre 2024 : Trieste et l’Istrie
Publié: 27 November 2024, 2:01pm CET par r.a.
Institut de Géographie, 191 rue Saint-Jacques, Paris 5ème
Samedi 30 novembre 2024, de 10h à 12h30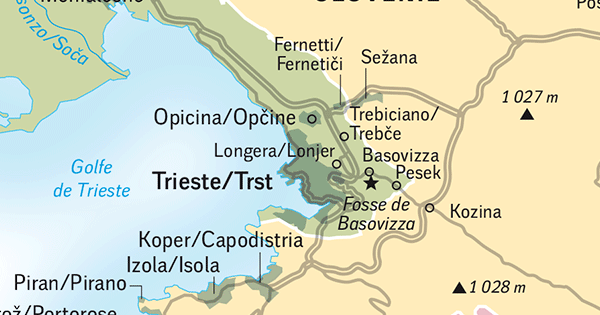
L’association des Cafés géographiques propose à ses adhérents un voyage de 5 jours en mai 2025 dont l’intitulé est « Trieste et l’Istrie ». Dans cette perspective nous avons pensé qu’une matinée à l’Institut de géographie pouvait être utile aux adhérents inscrits à ce voyage ainsi qu’à d’autres personnes curieuses d’en savoir plus sur cette région fascinante marquée par son identité de frontière.
Pour cela nous vous proposons deux petites conférences. Dans un premier temps, Daniel Oster a choisi de mettre en valeur quelques faits, essentiellement historiques, permettant de décrire un espace particulièrement complexe situé sur l’une des principales lignes de fracture de l’Europe. Dans un second temps, Henry Jacolin, ancien ambassadeur de France, se propose de présenter certains aspects de cette région dont il a une connaissance intime depuis longtemps. Il restera un peu de temps en fin de matinée pour des échanges entre les conférenciers et le public.
-
sur OpenSource eXperience – 4 & 5 Décembre 2024
Publié: 27 November 2024, 6:03am CET par Caroline Chanlon

Oslandia sera présent à OSXP les 4 et 5 décembre 2024 à Paris. Le salon OpenSource eXperience est la grande rencontre annuelle des acteurs de l’open source.
Retrouvez Vincent et Bertrand sur le stand de notre partenaire et client Orange E14 pour échanger sur vos projets ! Nous pourrons également vous présenter nos dernières réalisations.
Le Groupe Orange a d’abord été utilisateur de produits open source, puis contributeur et éditeur. L’opensource est désormais une direction stratégique du groupe, avec un réel engagement pour être un acteur moteur de l’écosystème. En tant que premier partenaire OpenSource d’Orange, Oslandia est fière d’accompagner ce mouvement !
L’entrée est gratuite, vous pouvez créer votre badge ici : [https:]]
-
sur [Story] Oslandia x QWC : épisode 6 / 8
Publié: 26 November 2024, 7:18am CET par Benoît Blanc

Nous avons détaillé précédemment notre activité de développement fonctionnel autour de QWC, et les ajouts que nous avons pu réaliser. Aujourd’hui, nous évoquons la maintenance !
En plus de ces fonctionnalités, nous sommes confrontés lors des développements ou via des remontées de clients à des anomalies dans QWC. Oslandia réalise donc un travail continu de maintenance corrective sur la solution, pour améliorer sa qualité et sa robustesse.
Nous avons résolu ces dernières années plusieurs problèmes dont:
- l’amélioration du plugin de Ligne de temps (qui permet d’utiliser les données temporelles) où beaucoup de petits problèmes cumulés faisaient crasher l’application
- certains bugs dans la fonctionnalité de recherche
- Divers soucis sur les services QWC ont été corrigés
- problèmes de génération de la configuration
- problèmes de permissions pour l’édition de données
La maintenance des produits OpenSource est un sujet critique, et souvent plus difficile à financer que les développements fonctionnels. Concernant QWC, la maintenance est possible grâce à :
- la collaboration et la mutualisation de la maintenance entre les différents contributeurs ( e.g. SourcePole )
- l’auto-investissement OpenSource d’Oslandia, dont une partie est dédiée à la maintenance des composants clef de nos infrastructure SIG
- les contrats de maintenance QWC attribués à Oslandia
Si vous souhaitez garantir la pérennité de vos applicatifs QGIS web, le meilleur moyen est d’opter pour un contrat de maintenance. Vous aurez ainsi une assurance contre toute mauvaise surprise. Contactez-nous ( infos+qgis@oslandia.com ) !
-
sur Carte du Vendée Globe 2024 en direct : classement et parcours [Partie 1]
Publié: 25 November 2024, 9:58pm CET par Florian Delahaye
Le Vendée Globe 2024 est lancé depuis le 10 novembre. Si vous suivez le blog depuis des années, vous vous souvenez certainement de l’article sur les requêtes spatiales PostGIS du Vendée Globe 2020. Pour cette nouvelle édition de la course à la voile, Geomatick vous propose une série d’articles. On… Continuer à lire →
L’article Carte du Vendée Globe 2024 en direct : classement et parcours [Partie 1] est apparu en premier sur GEOMATICK.
-
sur Créer un environnement virtuel Python pour le développement de plugin QGIS avec VS Code sous Windows
Publié: 25 November 2024, 2:00pm CET
 Pour le bonheur d'Intellisense
Pour le bonheur d'Intellisense
-
sur Open Source Places, une base de données de 100 millions de POI en open source (Foursquare)
Publié: 24 November 2024, 6:51pm CET
Source : « Foursquare Open Source Places : A new foundational dataset for the geospatial community » (Foursquare)La plate-forme Foursquare, qui se présente comme « leader du secteur pour tout ce qui concerne le géospatial », lance Open Source Places, un ensemble de données ouvertes comprenant 100 millions de lieux d’intérêt (POI) classés selon 22 attributs de base. La carte reflète la diversité des lieux d'intérêt dans le monde. L'inégale densité de l'information traduit l'inégale répartition de la population (les pleins et les vides de l'oekoumène). Cette couverture inégale est aussi celle de millions d'utilisateurs qui ont contribué à saisir l'information (principalement dans les zones développées bénéficiant de bonnes connexions et d'utilisateurs bien équipés). D'une certaine manière, la carte reflète l'inégale géonumérisation du monde.
L'inégale densité des « lieux d'intérêt » ou POI selon Open Source Places (source : Foursquare)1) Diffuser des POI en open source, un enjeu majeur
Les données rassemblent des informations livrées par des sociétés « à partir de sources tierces faisant autorité ainsi que de milliards de photos, de conseils et d'avis générés par les utilisateurs, issus de 10 ans d'expérience en matière de collecte de commentaires des consommateurs ». Ces données POI sont destinées selon Foursquare à « stimuler l'innovation dans l'ensemble de la communauté géospatiale ». Étant donné leur origine, il n'est pas étonnant de voir dominer les données concernant des lieux ayant un usage commercial.
Même si ces données sont gratuites, il s'agit pour Foursquare de valoriser son image d'entreprise spécialisée dans le géospatial. Les POI fournissent souvent la couche fondamentale pour le développement open source. Foursquare a bâti nombre de ses applications à partir de ces données ouvertes. Foursquare Places a été construit sur un système de crowdsourcing, à partir des données d'utilisateurs utilisant ses applications mobiles. Tout l'enjeu est désormais de parvenir à maintenir une base de données synchronisée avec le monde réel. C'est certainement l'une des raisons qui ont conduit à la mise à disposition de ces données POI en open source : poursuivre, voire amplifier le travail de saisie et de mise à jour de ces données sur une base contributive, ce qui est l'objectif de sa Placemaker Community, souvent mise en avant par Foursquare comme une des spécificités de l'entreprise.
2) L'accès aux données au format parquet
L’ensemble des données est fourni au format parquet. Il est prévu qu'il soit mis à jour mensuellement. Ces données peuvent être filtrées par catégories et par type de lieux commerciaux ou non commerciaux (voir le schéma de base ici).
L'extraction des données à partir de gros fichiers au format parquet nécessite des compétences techniques. On peut utiliser l'interface Fused qui permet de faire des extractions simples à partir d'un secteur géographique (téléchargement des données au format geojson). Mark Litwintschik et Simon Willison fournissent des conseils pour procéder à des extractions avec DuckDB ou pour les récupérer sur Github (plus de 10 Go de données à télécharger en plusieurs fichiers).
Certains data analystes comme Tim Wallace soulignent l'intérêt de pouvoir disposer d'une telle masse de données ouvertes. Mais comme pour tout jeu de données, ouvert ou non, il est bon de savoir à quoi on a affaire. Bien que Foursquare garantisse des données gratuites et de haute qualité, certaines données sont quelque peu incohérentes ou mal renseignées. Avec le temps, il devrait être possible d'éliminer ces bizarreries.
3) La consultation à travers une interface cartographique
Les données peuvent être visualisées directement à travers l'interface cartographique Fourquare Studio
À mesure que l'on zoome, on voit apparaître les cellules géométriques qui donnent la somme de lieux et leurs grandes catégories (vente de détail, manger et boire, voyage et transports, services aux entreprises et professionnels, événementiel). Pour aller plus loin, il faut s'abonner à l'application Studio. D'où l'intérêt de télécharger les données dans un SIG pour pouvoir faire des analyses plus fines à l'échelle des sous-catégories. A noter cependant : on ne dispose pas de la nature et de la géolocalisation précises des données, celles-ci ayant été catégorisées et agrégées avant diffusion à l'échelle de chaque cellule. En cela, le jeu de données Open Source Places montre bien l'intérêt et les limites du big data et de l'open data tels qu'ils sont mis en oeuvre aujourd'hui par les grandes entreprises.
Articles connexes
L'Overture Maps Foundation ambitionne de rivaliser avec Google et Apple
AllThePlaces : géodonnées et vision du monde commercial à travers Internet
Le monde de l'Internet en 2021 représenté comme un planisphère par Martin Vargic
Guide de l'Insee pour faciliter l’accès aux données
Cartes et données sur la population mondiale (Population & Sociétés, 2024)
Jeu de données SEDAC sur l'évolution des villes dans le monde entre 1975 et 2030
Cartographier l'empreinte humaine à la surface du globe
Utiliser Wikidata pour chercher des informations géographiques
Une base de données historiques sur les personnages célèbres dans le monde (de 3500 avant JC à 2018)
Geonames, une base mondiale pour chercher des noms de lieux géographiques
OpenDataSoft : une plateforme avec plus de 1800 jeux de données en accès libre
Data France, une plateforme de visualisation de données en open data
Numbeo, une banque de données et de cartes sur les conditions de vie dans le monde
-
sur La cartographie dans la tradition islamique : ??rat al-Ar?
Publié: 23 November 2024, 6:23am CET
Source : Mapping in the Islamic Tradition : ??rat al-Ar? (2024). Library of Congress.Dans une présentation intitulée « ??rat al-Ar? : des manières de voir les représentations islamiques du monde et au-delà », Karen Pinto, chercheuse associée en études religieuses à l'Université du Colorado, présente la vision du monde du point de vue de la tradition cartographique islamique. Dans cette tradition dite ??rat al-Ar? (Configuration du monde d'après le célèbre ouvrage d'Ibn Haqwal), l'art, la géographie, la religion et la philosophie fusionnent pour présenter des images aux origines cosmographiques et à l'identité spatiale orientée vers le Sud. À partir des messages codés dans ces cartes, la chercheuse nous fait découvrir des récits historiques longtemps cachés et nous permet de revisiter les contributions de cette tradition cartographique à l'histoire de la cartographie de notre monde. Cette conférence fait partie de la présentation d'automne 2024 de la Philip Lee Phillips Society, « Cartographie dans la tradition islamique ».
Karen Pinto, originaire de Karachi au Pakistan, formée à Dartmouth et à Columbia, s'est spécialisée dans l'histoire de la cartographie islamique et ses intersections entre les traditions cartographiques ottomanes, européennes et autres au niveau mondial. Elle a passé trois décennies à traquer des cartes dans les collections de manuscrits orientaux du monde entier. Elle possède un référentiel de 3 000 images de cartes islamiques, dont beaucoup n'ont jamais été publiées auparavant. Son livre Medieval Islamic Maps and Exploration a été publié par la University of Chicago Press en novembre 2016, et a remporté le prix Outstanding Academic Title Award 2017 de Choice. Elle a également remporté le prix Ibn Khaldun pour son travail sur la Méditerranée dans l'imaginaire cartographique islamique. En plus de ses études sur le Moyen-Orient et l'Islam, elle s'intéresse aux humanités numériques, aux études spatiales et au développement de modèles 3D pour améliorer notre compréhension des cartes médiévales.
Quelques extraits de la conférence
« Aujourd'hui nous sortons notre téléphone et Google Maps, nous disons que nous voulons aller ici, là et partout... Mais comment faisions-nous au VIIe siècle ? Tous ces musulmans partant à la conquête du monde, comment savaient-ils où ils allaient ? C'est une question fascinante. »
« La première chose que je fais est de dire à mes étudiants, rangez tous vos livres, prenez un morceau de papier et dessinez la première carte qui vous vient à l'esprit. Combien d'entre eux font celle qui montre le nord en haut avec l'Amérique au centre ? Ils font ce type de carte, mais certains d'entre eux en dessinent d’autres différentes. C'est vraiment intéressant de voir, quelle est la carte qui tourne dans leur tête ? Quelle est votre carte mentale ? Où est votre carte mentale ? »
« L'océan qui nous entoure c'est, comme vous le savez, le motif de toutes les cartes pré-modernes. Au début de la période moderne, soudainement on voit apparaître l'Atlantique et le Pacifique. Étaient-ils été divisés ? Non. Vous pensez qu'ils sont divisés. Mais si vous regardez Google Maps sous un angle particulier, vous verrez que les océans sont tous connectés. Nous avons toujours un océan qui nous entoure. »
« J'ai passé des heures et des heures à regarder ces cartes en me demandant, qu'est-ce que c'est ? Des lignes et des cercles étranges et quelques créatures ornementales, et puis vous commencez à lire et vous commencez à dire, oh, ce sont des noms de lieux que je reconnais. Oh, c'est le golfe Persique, vraiment ? Et ça ce n'est pas l'Afrique et l'Espagne ? »
« Ce que tous les amateurs de cartes aiment universellement, c'est d'identifier des lieux et déterminer quel lieu se trouve où. Sur ces cartes, un certain nombre de lieux ont disparu. Je suis allé sur le terrain à la recherche de lieux car ils ne figurent pas dans les manuscrits. Ils ont été oubliés. Et la seule façon de les trouver est d'aller sur place. J'ai donc été sur place en Syrie et en Turquie, à la recherche de lieux sur la carte de la Méditerranée, c'est dire à quel point les gens qui s'intéressent aux cartes sont obsédés. »
« C'est juste comme ça que sont les cartes. C'est quand vous ne les comprenez pas, quand elles n'ont aucun sens, quand vous devez aller creuser pour trouver le sens derrière ces cartes ou ce qu'elles essaient de vous montrer, c'est ce qui est fascinant. »
« Et puis cette idée : si on commençait à regarder le monde avec une autre direction en haut, en particulier avec les musulmans, avec le sud en haut, ils privilégient l'Afrique, n'est-ce pas ? Ils regardent vers l'Afrique. Ils ne privilégient pas l'Europe. Donc le sud est en haut. »
« Si vous prenez une goutte de cartographie chinoise pré-moderne, une goutte de cartographie européenne pré-moderne, une goutte de cartographie africaine pré-moderne, vous les prenez et les additionnez, qu'est-ce que vous obtenez ? Vous obtenez une carte islamique. Parce que le truc à propos du monde musulman, qui est si intéressant et qui est représenté ici, c'est la figure de la péninsule arabique qui est au centre des cartes. Donc ils sont au carrefour. Le centre de la croix. Ils sont au centre de la croix du monde. Et même maintenant, quand vous pensez au monde, si vous pensez simplement à la carte, la péninsule arabique est juste là connectant l'Afrique à l'Asie, à l'Europe. Vous avez donc cette connectivité incroyable ».
Pour compléter
« Quand j'étais étudiant diplômé à Columbia en 1991, ma professeure, la regrettée mais incroyablement grande Olivia Remie Constable (1961-2014), m'a suggéré d'écrire un article de séminaire sur les géographes musulmans médiévaux. Cela m'a envoyé dans les recoins sombres de la collection d'histoire et de géographie islamiques au 11e étage de la bibliothèque Butler. Là, je suis littéralement tombé sur les 6 volumes de Konrad Miller de la fin des années 1920 : Mappae Arabicae : Arabische Welt und Länderkarten des 9–13. Jahrunderts. (6 vol. Stuttgart, 1926–1931) réimpressions en noir et blanc de centaines de cartes islamiques médiévales cachées dans des manuscrits orientaux jusqu'alors peu connus dans le monde de l'histoire de la cartographie occidentale.
« L'harmonie masque le conflit : la Méditerranée dans l'imaginaire islamique médiéval » (exposition de Karen Pinto)
« Tout est dans la carte » (New York Review of Books)
Articles connexes
L’attachement des Etats à leurs frontières et le déclin des dynasties ne s’expliquent pas uniquement pas des facteurs idéologiques ou politiques. Dès le XIVe siècle, l’historien arabe Ibn Khaldoun, souligne le rôle que jouent la géographie et la morphologie géophysique d’un pays dans son destin et celui de sa région. Dans cet article de la New York Review of Books traduit par Books en janvier 2014, Malise Ruthven souligne notamment toutes les significations que peuvent prendre une simple carte pour une nation, et nous réapprend à penser le monde autrement.Le nord en haut de la carte : une convention qu'il faut parfois savoir dépasser
Désaxer la carte pour porter un autre regard, mais lequel ?
Atlas ptolémaïques de la Bibliothèque du Congrès : un guide de ressources
Le monde luso-hispanique à travers les cartes : un guide de la Bibliothèque du Congrès
Atlas stratégique de la Méditerranée et du Moyen-Orient (FMES)
Numérisée en haute résolution, la carte médiévale de Fra Mauro peut être explorée en détail
La carte médiévale d'Ebstorf en version interactive et en téléchargement
Cartes et atlas historiques
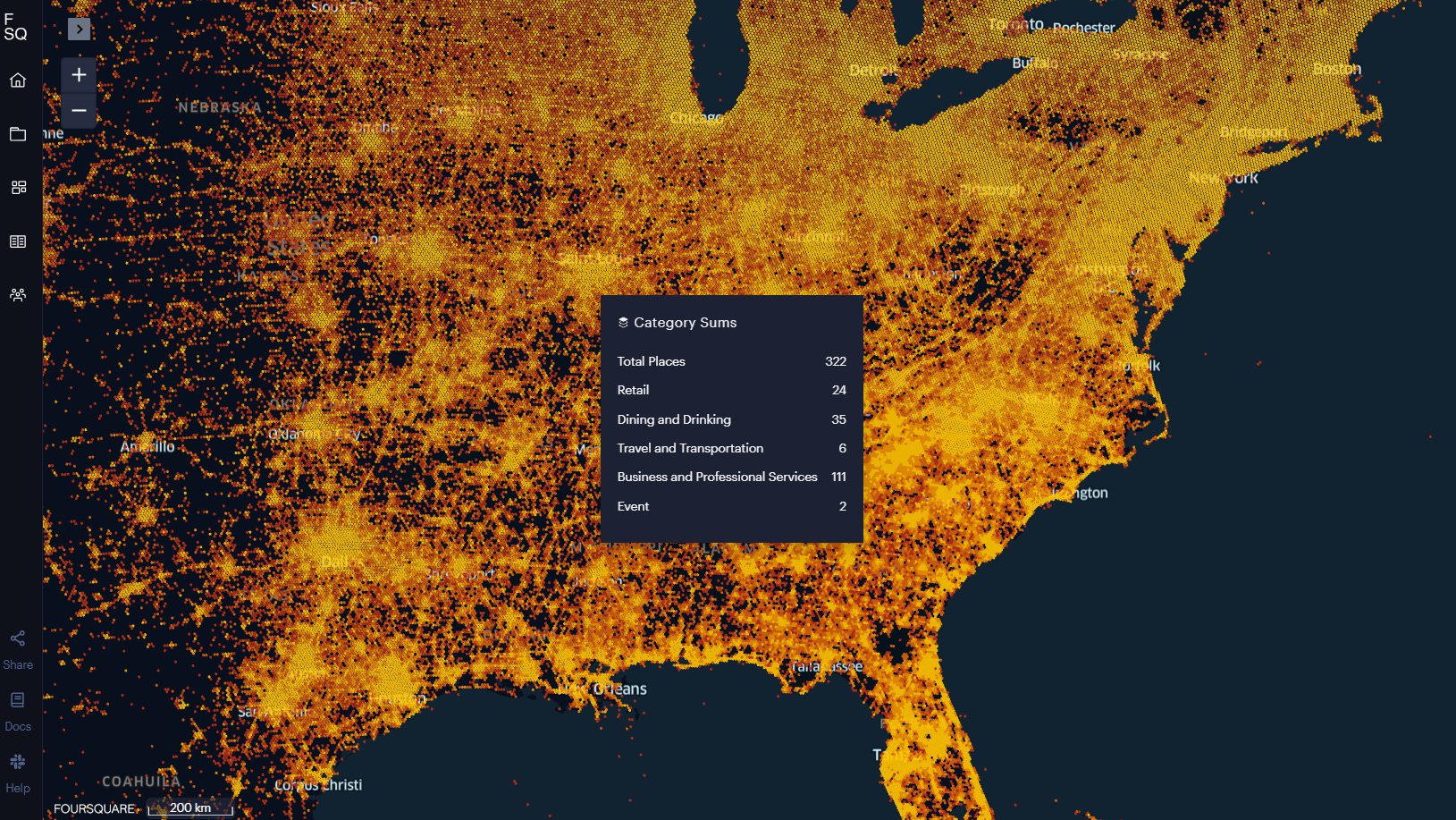

-
sur Du 24 au 26 juin 2025 à Lille : formation "savoir utiliser DV3F"
Publié: 22 November 2024, 3:30pm CET
Publié le 22 novembre 2024Une session de formation "Savoir utiliser DV3F" se tiendra du 24 au 26 juin 2025 dans les locaux du Cerema Hauts-de-France à Lille.Cette session est à destination des bénéficiaires des fichiers DV3F et des bureaux d'études.Vous trouverez le contenu et le coût de la formation dans la rubrique AccompagnementInscription jusqu'au 23 mai (…)
Lire la suite -
sur Du 13 au 15 mai 2025 à Lille : formation "savoir utiliser les Fichiers Fonciers"
Publié: 22 November 2024, 3:30pm CET
Publié le 22 novembre 2024Une session de formation "savoir utiliser les Fichiers Fonciers" se tiendra du 13 au 15 mai 2025 dans les locaux du Cerema à LILLE.Cette session est à destination des bénéficiaires des Données Foncières (Fichiers fonciers et DV3F) et des bureaux d'études.Vous trouverez le contenu et le coût de la formation dans la rubrique AccompagnementInscription jusqu'au 18 avril (…)
Lire la suite
-
sur Cartographie du surpoids et de l’obésité aux États-Unis et dans le monde
Publié: 22 November 2024, 12:58pm CET
Source : Ng, Marie et al., National-level and state-level prevalence of overweight and obesity among children, adolescents, and adults in the USA, 1990–2021, and forecasts up to 2050. [Prévalence du surpoids et de l’obésité aux États-Unis (1990-2021) et prévisions jusqu’en 2050]. The Lancet, article en accès ouvert.
Présentation
D’après la définition de l’OMS, une personne est en surpoids lorsque son indice de masse corporelle (IMC) est supérieur à 25 et elle est obèse lorsque celui-ci est supérieur à 30. Le surpoids et l’obésité ne cessent d'augmenter aux États-Unis. L'obésité a presque triplé au cours des 50 dernières années. Le monde compte plus d'un milliard de personnes obèses dont l'indice de masses corporelle (IMC) dépasse les 30 kg/m2. Il convient de comprendre les tendances actuelles et les trajectoires futures au niveau national et au niveau des États pour évaluer le succès des interventions actuelles et éclairer les futurs changements de politique de santé. Dans cet article, les auteurs ont estimé la prévalence du surpoids et de l’obésité de 1990 à 2021 avec des prévisions jusqu’en 2050 pour les enfants et les adolescents (âgés de 5 à 24 ans) et les adultes (âgés de plus de 25 ans). En outre, ils ont établi des estimations et des projections spécifiques pour chaque État concernant les adolescents âgés de 15 à 24 ans et les adultes pour les 50 états et Washington DC.Prévalence estimée du surpoids et de l'obésité dans 50 États américains en 2021 chez les adolescents et les adultes, par sexe (source : The Lancet)
01548-4/asset/a84a1c9d-b470-4239-aef5-08a53be5a2d7/main.assets/gr1_lrg.jpg)
Principaux résultats
En 2021, on estime qu'environ 15,1 millions d'enfants et jeunes adolescents (âgés de 5 à 14 ans), 21,4 millions d'adolescents (âgés de 15 à 24 ans) et 172 millions d'adultes (âgés de plus de 25 ans) étaient en surpoids ou obèses aux États-Unis.
Le Texas avait la prévalence standardisée selon l'âge la plus élevée concernant le surpoids ou l'obésité chez les adolescents de sexe masculin (âgés de 15 à 24 ans), soit 52,4 % (47,4-57,6), tandis que le Mississippi avait la prévalence la plus élevée chez les adolescentes (âgées de 15 à 24 ans), soit 63,0 % (57,0-68,5).
Chez les adultes, la prévalence du surpoids ou de l'obésité était la plus élevée dans le Dakota du Nord pour les hommes, estimée à 80,6 % , et dans le Mississippi pour les femmes à 79,9 % . La prévalence de l'obésité a dépassé l'augmentation du surpoids au fil du temps, en particulier chez les adolescents.
Entre 1990 et 2021, la variation en pourcentage de la prévalence standardisée de l'obésité selon l'âge a augmenté de 158,4 % chez les adolescents de sexe masculin et de 185,9 % (139,4–237,1) chez les adolescentes. Chez les adultes, la variation en pourcentage de la prévalence de l'obésité était de 123,6 % chez les hommes et de 99,9 % chez les femmes.
Les résultats des prévisions suggèrent que si les tendances et les schémas passés se poursuivent, 3,33 millions d'enfants et de jeunes adolescents supplémentaires, 3,41 millions d'adolescents et 41,4 millions d'adultes supplémentaires seront en surpoids ou obèses d'ici 2050. Le nombre total d'enfants et d'adolescents en surpoids et obèses atteindra 43,1 millions et le nombre total d'adultes en surpoids et obèses atteindra 213 millions en 2050. Dans la plupart des états des États-Unis, on prévoit qu'un adolescent sur trois et deux adultes sur trois souffriront d'obésité. Bien que les États du Sud, tels que l’Oklahoma, le Mississippi, l’Alabama, l’Arkansas, la Virginie-Occidentale et le Kentucky, devraient continuer à connaître une prévalence élevée de l’obésité, les changements de pourcentage les plus élevés à partir de 2021 sont prévus dans des États comme l’Utah pour les adolescents et le Colorado pour les adultes.
Interprétation
Les politiques actuelles n’ont pas réussi à lutter contre le surpoids et l’obésité. Sans réforme majeure, les tendances annoncées seront dévastatrices au niveau individuel et collectif, le poids de la morbidité et les coûts économiques associés continueront d’augmenter. Une gouvernance plus forte est nécessaire pour soutenir et mettre en œuvre une approche systémique multidimensionnelle visant à lutter contre les facteurs structurels du surpoids et de l’obésité aux niveaux national et local. Bien que les innovations cliniques doivent être exploitées pour traiter et gérer de manière équitable l’obésité existante, la prévention au niveau de la population reste au cœur de toute stratégie d’intervention, en particulier pour les enfants et les adolescents.
Les données et les cartes sont disponibles dans les annexes de l'article.
Fiche d'information de l'Organisation mondiale de la santé (OMS) sur l'obésité et le surpoids.
Pour compléter
« Tendances mondiales de l'insuffisance pondérale et de l'obésité de 1990 à 2022 : une analyse groupée de 3 663 études représentatives de la population portant sur 222 millions d'enfants, d'adolescents et d'adultes » (The Lancet). Accès aux données de l'article sur Zenodo ou sur le site de la Ncdrisc (National Adult Body-Mass Index).
« Quel État américain a le taux d’obésité le plus élevé ? » (Visual Capitalist, 30 juillet 2024).
Taux d'obésité chez les adultes en 2022 par État et territoire des États-Unis. L'obésité est définie comme un indice de masse corporelle (IMC) égal ou supérieur à 30. Les chiffres proviennent des Centres américains pour le contrôle et la prévention des maladies et sont mis à jour en janvier 2024. Les chiffres sur l'obésité sont basés sur la taille et le poids autodéclarés. Accès aux données sur le site du CDC (Centers for Disease Control and Prevention)« Une personne sur huit vit désormais avec de l’obésité dans le monde » (Organisation mondiale de la Santé).
« L'obésité touche surtout les personnes d'âge moyen et les pauvres » (Robert Wood Johnson Foundation).
« Cartes. Géographie de l’obésité ». Par Hervé Théry, Patrick Caron (Diploweb, 30 octobre 2019).Il existe, dans nombre de pays du monde, une correspondance entre offre abondante de viande et obésité.
« Comment les villes aggravent l'épidémie d'obésité » (Fast Company).Le mythe selon lequel l'obésité n'est qu'une question personnelle ne tient pas compte du rôle que jouent les villes pour décourager les modes de vie sains.
« Relation entre obésité et vote électoral des États américains » (Data Is Beautiful).
On sait que l’obésité est liée au statut socio-économique, qui est lui-même l'un des déterminants du vote électoral. Si les États qui comptent le plus d'obèses votent républicain, il faut cependant faire la distinction entre corrélation et causalité. D'autres facteurs entrent en considération tels que l’appartenance religieuse ou l'éducation. Il convient de conduire des études au niveau individuel et non uniquement au niveau des Etats ou des comtés. Étant donné que les systèmes politique, économique et de santé aux États-Unis sont très différents de ceux d'autres pays, les recherches menées aux États-Unis sont difficilement généralisables (voir cette étude sur le Royaume-Uni).Articles connexes
L'insécurité alimentaire dans le monde (rapport du FSIN)
L’autosuffisance alimentaire est-elle possible pour La Réunion ?
Les grands enjeux alimentaires à travers une série de story maps du National Geographic
Des différentes manières de cartographier la pauvreté dans le monde
-
sur Découvrez les évolutions majeures de Python de 3.9 à 3.13
Publié: 21 November 2024, 9:27am CET par admin
Python, le langage de programmation dynamique créé par Guido van Rossum, est devenu l’un des outils les plus populaires pour les développeurs en raison de sa simplicité, de sa flexibilité et de sa puissance. À Neogeo, nous l’utilisons pour développer le backend de nos applications, pour faire des scripts d’administration et de la data-science.
Pour marquer la sortie de Python 3.13 le 7 Octobre dernier, nous allons passer en revue les changements importants qui ont été introduits dans les versions 3.9 (dernière version encore maintenue) à 3.13 de Python.
Ces nouvelles versions apportent des améliorations significatives en termes de performances, avec l’optimisation du code JIT et la suppression du GIL, véritable goulot d’étranglement pour les applications multi-thread. Elles offrent également des évolutions syntaxiques comme l’expression « matching ».
Autres nouveautés : la librairie standard de Python a elle aussi été mise à jour. La gestion du typage en Python a également été améliorée, avec l’introduction de types dynamiques. Nous verrons ces changements dans un article dédié.
Dans cet article, nous allons vous guider dans l’exploration des principaux changements apportés par Python 3.9 à 3.13, et nous vous proposerons des exemples pour exploiter ces nouvelles fonctionnalités et améliorer vos applications.
PerformancesDans la version 3.9 de Python, les performances de certaines structures built-in telles que dict, list ou set ont été améliorées. L’accès aux variables Python depuis les modules C a aussi été accéléré (nous n’aborderons pas ce sujet dans cet article).
La version 3.11 a été beaucoup optimisée, la documentation parle de 25% de gain de performances en moyenne, entre 10% et 60% d’amélioration selon le type de tâches.
Les travaux sur le GIL ont porté leurs fruits sur les versions 3.12 et 3.13. Le GIL, Global Interpreter Lock, est un mécanisme de Python qui évite l’accès simultané à une variable par plusieurs threads. Très simple pour le développeur, cela empêche la création de programmes multi-thread efficaces en Python. À une époque où on multiplie les CPU et les cores, c’est un fardeau pour notre petit langage. Les développeurs ont travaillé à retirer ce mécanisme, mais ils doivent procéder par étapes. Dans la version 3.12, Python peut désormais utiliser un GIL par interpréteur, on peut même le désactiver en ligne de commande dans la 3.13.
On peut noter qu’asyncio a été optimisé dans la version 3.12, avec jusqu’à 75% de gains de performances. Cette version de Python bénéficie d’une nouvelle API pour faire du monitoring de façon moins intrusive (impactant moins les performances).
En complément, la version 3.13 bénéficie aussi d’un compilateur JIT expérimental, il est activable en ligne de commande. La documentation indique que les gains de performances sont modestes. On peut imaginer que les versions suivantes de Python intégreront un compilateur JIT plus sophistiqué et plus performant.
Évolutions syntaxiquesLa version 3.9 de Python voit l’introduction d’opérateurs d’union de dictionnaire | et | =. Sans être révolutionnaire, on peut toujours utiliser la fonction update pour faire la même chose, mais c’est plus simple à écrire.

Peut-être moins impactant, on peut désormais utiliser des expressions Python comme décorateur. Cela permet de faire des appels de fonctions ou demander un élément d’une liste quand on utilise le décorateur :

Par ailleurs, les chaînes de caractère ont deux nouvelles méthodes pour supprimer les suffixes et préfixes :

Le pattern matching est enfin arrivé en Python dans la version 3.10. C’est l’équivalent du célèbre switch-case existant en C ou en Java. Je reprends l’exemple de la documentation :

Le Structural Pattern Matching est très puissant en Python car on peut faire du unpacking de paramètres, de l’assignation de variables, rajouter des conditions, je vous recommande de parcourir la PEP636 pour plus de détails.
L’autre évolution syntaxique de Python 3.10 est la possibilité d’utiliser des parenthèses dans une clause with, notamment pour pouvoir utiliser plusieurs lignes :

La version 3.11 de Python a vu la création de groupes d’exceptions. On peut désormais envoyer plusieurs exceptions en même temps. Cela peut-être utile pour passer dans plusieurs sections except pour corriger plusieurs problèmes. Voici l’exemple très explicite de la documentation qui permet de comprendre comment s’en servir (encore merci la documentation pour l’exemple) :
L’autre ajout dans les Exceptions qui me semble très utile est la fonction add_note() qui permet d’ajouter des détails lors de l’interception/renvoi d’exception :
Si vous regardez bien dans les messages d’erreur de Python (dans le traceback notamment), vous verrez désormais que l’interpréteur indique plus précisément où l’erreur se situe dans la ligne et pas seulement dans quelle ligne est l’erreur.
La version 3.12 a vu une petite modification de syntaxe mais qui va simplifier l’utilisation des f-strings : on peut désormais utiliser les mêmes séparateurs de string dans le contexte que celui de la chaîne parente :
Par contre, il n’y a pas de changement syntaxique dans la version 3.13. Il y a tout de même des améliorations dans les messages d’erreurs et l’interpréteur retournera des messages d’erreurs en couleur.
Librairie standardDe moins en moins d’évolutions sont apportées à la bibliothèque standard. Dans la version 3.9 de Python, on note juste l’ajout d’un module zoneinfo pour gérer les fuseaux horaires :

Il y a aussi un nouveau module de tri topologique graphlib.
Dans la version 3.10 de la librairie standard, la fonction zip possède un nouveau paramètre strict qui permet de vérifier que la taille des deux itérateurs en entrée sont identiques.
La version 3.11 de la librairie voit un nouveau module tomllib permettant de lire le format de fichier TOML (mais pas de l’écrire). L’API est similaire à celle du module json :
 Conclusion
Conclusion
On voit que Python est un langage de plus en plus stable, il y a peu de chose à rajouter à sa syntaxe pour améliorer la lisibilité du code. On peut dire la même chose de sa bibliothèque de fonctions standard.
Un gros travail pour améliorer les performances et le nettoyage de la bibliothèque standard a été entrepris et porte petit à petit ses fruits.
Nous avons hâte de profiter des avancées de cette nouvelle version 3.13 dans nos projets.
Ce qui bouge le plus dans Python en ce moment, c’est clairement le typage. Mais ça, ce sera pour un prochain article !
Rédacteurs : Mathilde Pommier et Sébastien Da Rocha
-
sur "La donnée, langage commun de nos territoires", table ronde au Salon des Maires 2024
Publié: 21 November 2024, 8:52am CET
"La donnée, langage commun de nos territoires", table ronde au Salon des Maires 2024
-
sur [Equipe Oslandia] Julien Moura, consultant SIG
Publié: 21 November 2024, 6:48am CET par Caroline Chanlon

Après son BAC, Julien s’oriente vers une prépa littéraire Khâgne et Hypokhâne au Prytanée national militaire à la Flèche. Il fait ce choix pour profiter de la méthodologie de travail et du challenge qu’offrent la prépa et poursuit son cursus en géographie : Licence de Géographie Urbanisme et Environnement puis le Master parcours Carthagéo à la Sorbonne.
« J’ai depuis toujours associé la géographie au mouvement, et c’est une discipline intéressante qui en croise plein d’autres : environnement, géopolitique, statistiques, mathématiques, … c’est ce qui m’a donné envie de rejoindre cette voie »
Dans le cadre de ses études, il part à Madagascar pour un stage de cartographie prospective sur le traitement et la valorisation des déchets en milieu urbain dense, puis direction La Réunion où Julien est embauché à l’Établissement Public Foncier de la Réunion (EPF Réunion) pour identifier le foncier éligible à des projets d’intérêt général. En parallèle de cet emploi, il s’engage !
« J’aime l’associatif et le partage de connaissances, je commence à donner des cours en géomarketing à l’IAE de la Réunion, je m’investis dans le Club Géomatique de la Réunion pour animer des groupes notamment sur GéoSource (pour INSPIRE), QuantumGIS (l’ancien nom de QGIS) et je rejoins Geotribu ».
Après 3 ans passés à La Réunion, Julien décide de partir du Vénézuela avec son sac à dos comme seul compagnon et parcourt l’Amérique du Sud jusqu’à un coup du hasard dans une gare routière en Équateur où il voit sur GeoRezo une proposition de VIA (Volontariat International en Administration) de l’IRD à Lima !
2 ans plus tard, Julien décide de rentrer en France et reprend des études : le Mastère SILAT – Systèmes d’informations localisées pour l’aménagement des territoires orienté en gestion de projet à Montpellier qu’il réalise en partenariat avec Isogeo, une start-up dédiée à la gouvernance des données géographiques.
Pendant 6 ans, il enchaîne les missions et les postes chez Isogeo : de chef de projet à directeur de produit tout en continuant à contribuer à Geotribu et à donner des cours à l’ESIPE (École supérieure d’ingénieurs de Paris-Est) et l’ENSG, l’école de référence en géomatique en France.
Après une période en indépendant, Julien est embauché chez Oslandia en 2020 en tant que Consultant SIG. Julien est embauché chez Oslandia en 2020 en tant que Consultant SIG.
Projets emblématiques
Très orienté qualité logicielle et DevOps, Julien apporte son expertise sur l’industrialisation de process, des projets de déploiement de QGIS sur des gros parcs, des audits de systèmes complexes et hybrides, recommandations sur les flux de la donnée géographique tout en continuant à donner des cours, notamment à l’École Urbaine de Sciences Po Paris, à animer Geotribu et à s’investir à l’OSGeo FR.« La Géoplateforme de l’IGN où j’ai assuré la coordination interne du projet. Pour cette fin d’année et 2025, j’anime une dynamique action visant à entraîner et accompagner les métropoles dans une migration open source avec comme fenêtre d’opportunité le décomissionnement de la suite Elyx d’une part et le renouvellement des licences ELA Esri d’autre part, le Grand Lyon faisant office de tête de pont. »
Technologies de prédilectionPython et CI/CD (YAML)
Ta philosophieFaire du travail sérieux sans se prendre au sérieux, plutôt que l’inverse !
Oslandia en 1 motOVNI !
-
sur Naofix.com : module Helpdesk
Publié: 20 November 2024, 3:01pm CET par Marc Saboureau
Notre partenaire sur le Salon des Maires et des Collectivités Locales Nautilux lance Naofix, le module Helpdesk qui transforme la gestion des services d’assistance avec des fonctionnalités avancées, combinant productivité, personnalisation et automatisation.
-
sur Suivre le Vendée Globe 2024 depuis un SIG
Publié: 20 November 2024, 2:00pm CET
 Créer et visualiser les données SIG de l'avancement de la course du Vendée Globe 2024 à partir des tableurs officiels.
Créer et visualiser les données SIG de l'avancement de la course du Vendée Globe 2024 à partir des tableurs officiels.
-
sur Nouvelle Journée Technique du PRNSN : le numérique dans les pratiques sportives de nature
Publié: 20 November 2024, 9:00am CET par Amandine Boivin
Le 27 novembre 2024, Montpellier accueille la 18e Journée technique du réseau national des sports de nature, organisée par le PRNSN.
-
sur Ajout du support de géométries 3D complexes dans QGIS 3.40
Publié: 19 November 2024, 7:10am CET par Jean Felder
[Un PolyhedralSurface de la forme d’un lapin dans le canvas 2D de QGIS]
Initialement conçu pour la cartographie 2D, QGIS a vu apparaitre des capacités 3D ces dernières années. Suite aux efforts continus de développement portés par Oslandia depuis 3 ans sur cette composante de l’application, QGIS supporte désormais dans sa version 3.40 l’affichage et la manipulation de géométries 3D complètes, comme les surfaces polyhédrales et les réseaux triangulés irréguliers (TIN). Cela permet de visualiser des formes en 3D bien plus réalistes et complexes que de simples polygones.
Pour mieux comprendre, voici une définition simple de ces géométries :
- Une surface polyhédrale est une surface 3D composée de multiples facettes planes (des polygones ou des triangles) qui sont assemblées pour créer une forme en volume, avec un rendu réaliste de courbes et de reliefs.
- Un réseau triangulé irrégulier (TIN) est une surface polyhédrale dont le maillage est constitué exclusivement de triangles de taille et d’angle variables.
Ce nouveau support offre désormais la possibilité d’effectuer des traitements 3D (comme découper, fusionner, déplacer, etc.) via le plugin QSFCGAL. Ces avancées élargissent les perspectives pour les projets nécessitant une analyse 3D.
Ces développements ont été rendus possible grâce au financement du CEA ainsi qu’à nos travaux de R&D financés par l’Union européenne – Next Generation EU dans le cadre du plan France Relance et du projet Cloud Platform for Smart Cities.
Ces évolutions permettent ainsi de répondre aux besoins concrets de nos clients, par exemple en représentant des couches géologiques et en permettant de réaliser des coupes afin de connaitre la nature du sous-sol.

Des PolyhedralSurface visualisés dans QGIS 3D. En rouge, un nuage de points. La géométrie représente une enveloppe concave du nuage de points calculé grâce à SFCGAL.
Si vous êtes intéressés par le rendu ou la manipulation de données 3D dans QGIS, n’hésitez pas à nous contacter ! Extraction d’une section d’une géométrie 3D grâce au plugin QSFCGAL
Extraction d’une section d’une géométrie 3D grâce au plugin QSFCGAL
-
sur Ilots de chaleur et inégalités urbaines en France
Publié: 19 November 2024, 4:48am CET
Céline Grislain-Letrémy, Julie Sixou, Aurélie Sotura. « En milieu urbain, les ménages modestes sont en général plus exposés aux îlots de chaleur » (Insee Analyses, octobre 2024).Les vagues de chaleur se traduisent par des températures significativement plus élevées en milieu urbain que dans la campagne environnante. Au sein même des villes, ce phénomène d’îlot de chaleur affecte différemment les quartiers selon la densité et la qualité des bâtiments, selon la végétation et selon les niveaux d’activité humaine. À Paris, Bordeaux, Lille et Nantes, ce sont à la fois les ménages les plus aisés et les plus modestes qui sont les plus exposés, car ils habitent dans les centres-villes. À Lyon, Marseille, Montpellier, Nice et Strasbourg, les ménages modestes sont les plus exposés au phénomène d’îlot de chaleur urbain et les ménages aisés sont les moins exposés, car ils habitent dans des quartiers périphériques moins denses, plus verts et aux constructions récentes. De façon générale, les ménages pauvres avec au moins une personne particulièrement jeune ou âgée sont exposés à des températures en moyenne légèrement plus élevées que les autres ménages. Ces ménages sont plus vulnérables aux fortes températures, et disposent de moins de possibilités pour y faire face : ils ont notamment plus rarement la climatisation ou une résidence secondaire.
Au sein même des villes, certains quartiers sont davantage exposés aux îlots de chaleur en raison notamment de différences de densité, de caractéristiques des bâtiments, de végétation et de niveaux d’activité humaine [Institut Paris Région, 2010]. Le centre des agglomérations est ainsi nettement plus exposé aux îlots de chaleur, comme l’illustrent les exemples de Paris et Lyon. Selon leur lieu de résidence, souvent très lié au revenu, certaines populations sont ainsi davantage exposées. La relation entre niveau de vie et exposition aux îlots de chaleur découle principalement de l’organisation spatiale des villes. Parmi les neuf villes étudiées ici, deux configurations apparaissent.Indice d’îlot de chaleur nocturne, Paris et Lyon été 2017 (source : (Insee Analyses, octobre 2024)
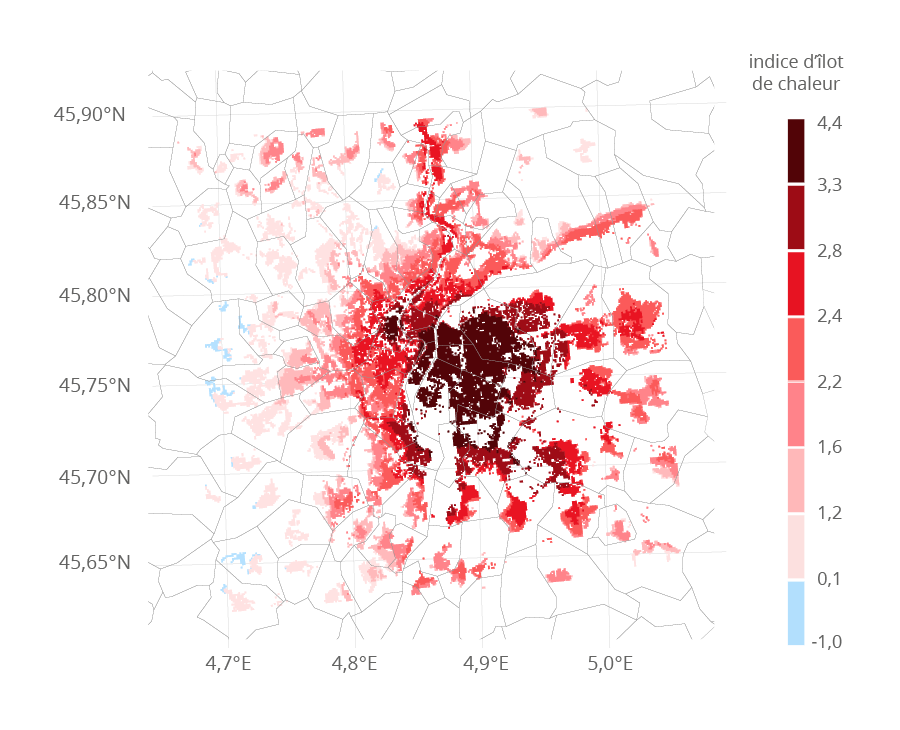
Les autres exemples de villes françaises sont disponibles dans le rapport complet de l'INSEE :
Céline Grislain-Letremy, Julie Sixou, Aurélie Sotura. « Urban Heat Islands and Inequalities : Evidence from French Cities » (Insee, octobre 2024)
Pour compléter
Fontès-Rousseau C., Lardellier R., Soubeyroux J.-M., « Un habitant sur sept vit dans un territoire exposé à plus de 20 journées anormalement chaudes par été dans les décennies à venir » (Insee Première n°1918, août 2022).
Institut Paris Région, « Les îlots de chaleur urbains », Répertoire de fiches connaissance (Institut Paris Région, novembre 2010).
Articles connexes
La France est-elle préparée aux dérèglements climatiques à l'horizon 2050 ?
Renforcer l'atténuation, engager l'adaptation (3e rapport du Haut Conseil pour le climat - 2021)
Rapport du Giec 2021 : le changement climatique actuel est « sans précédent »
Les villes face au changement climatique et à la croissance démographique
Les stations de montagne face au changement climatique (rapport de la Cour des comptes)
Comment la cartographie animée et l'infographie donnent à voir le changement climatique
Surmortalité attribuée à la chaleur et au froid : étude d'impact sur la santé dans 854 villes européennes
-
sur 12 événements cartographiques qui ont bouleversé notre monde (Maphappenings.com)
Publié: 18 November 2024, 3:54am CET
Le site MapHappenings.com, dédié à l'information et à la réflexion sur l'industrie de la cartographie, consacre une série de billets sur 12 événements cartographiques qui ont bouleversé notre monde. Racontées par James Killick, cartographe qui a travaillé sur le projet Mapquest, puis pour ESRI et Apple Maps, ces histoires renvoient à un passé qui semble déjà ancien, celui du début de l'ère informatique et de l'essor du géoweb. Que les initiatives proviennent de la sphère publique ou de la sphère privée (souvent des deux), on y découvre l'importance des grands projets qui ont permis l'essor des technologies et de la cartographie numérique.
Vous pouvez découvrir ces histoires en anglais. Votre navigateur devrait facilement faire la traduction si vous n'êtes pas familier avec la langue de Shakespeare. En voici les principales entrées thématiques :- Part 1 — The First Map
« La première carte » est difficile à déterminer, tout dépend de ce que l'on appelle carte (une représentation rupestre, une tablette d'argile, un papyrus...) - Part 2 — The Birth of Coordinates
« La naissance des coordonnées » remonte au moins à Eratosthène qui a inventé le système des latitudes et des longitudes, mais il faut attendre le XVIIIe siècle pour qu'on soit capable de mesurer avec un peu d'exactitude la longitude. - Part 3 — Road Maps !
« Cartes routières » : les atlas routiers ont une longue histoire. Aujourd'hui, la plupart des jeunes savent à peine lire une carte papier, et encore moins s'en servir (l'index des rues, ça vous dit quelque chose ?). Les cartes routières papier existent pourtant encore ! Au cas où vous ne me croiriez pas… - Part 4 — The Epic Quest for Longitude
« La quête épique de la longitude » a une longue histoire qui remonte au moins au début du XVIIIe siècle. - Part 5 — The Dawn of Tube Maps
« L’aube des plans de métro ». Depuis la carte d'Harry Beck publiée pour la première fois en 1933, les cartes de métro ont beaucoup évolué gagnant en complexité et schématisme. Est-ce à dire qu'elles ont perdu leur simplicité attrayante au profit de la complexité et de l'incohérence ? - Part 6 — The Advent of Computer Based Mapping
« L’avènement de la cartographie assistée par ordinateur ». Premier programme civil à avoir réussi à mettre au point un ordinateur en 1943, UNIVAC I a joué un rôle clé dans l'avènement de l'ère informatique. Il faut attendre les années 1960 pour que le Harvard Laboratory for Computer Graphics invente le système de cartographie synagraphique (SYMAP). - Part 7 — Those Views from Above…
« Ces vues d’en haut…». C'est au cours de la Première Guerre mondiale qu'apparaissent les premières images prises par avion. En 1972, la NASA lance le premier satellite Landsat annonçant une nouvelle ère, celle de la télédétection terrestre depuis l'espace. - Part 8 — Oh Brother, Where Art Thou?
« Oh frère, où es-tu ? ». Ce n'est qu'en 2016 que la pénétration mondiale des smartphones a dépassé les 50 %, on peut donc affirmer que cela ne fait que 8 ans que la majorité des gens sur cette planète sont capables de déterminer rapidement leur emplacement. Retour sur les techniques de positionnement, leur histoire et celles qui se profilent pour demain. - Part 9 — A Curious Phenomenon Called ‘Etak’
« Un phénomène curieux appelé Etak ». En 1985, les systèmes de navigation GPS n'existaient pas encore. Etak Navigator, lors de sa sortie, en étant le premier système de navigation automobile au monde, faisait figure de produit révolutionnaire. - Part 10 — A Relentless Quest for Maps
« Une quête incessante de cartes » revient sur l'histoire de Mapquest, un projet de 1996 qui semble déjà ancien. A son lancement, MapQuest ne fournissait même pas d'itinéraire. Il ne faisait qu'une chose : il affichait une carte statique pour une adresse, et seulement si cette adresse se trouvait aux États-Unis. Mais MapQuest savait où vous vouliez aller. MapQuest a donc été le premier site à proposer des publicités « géocentriques ». Les hôtels, les compagnies aériennes et les chaînes de restauration rapide ont adoré.
Pour compléter
Minds behind maps. « Les cartes sont partout. Internet a fait exploser le besoin de savoir ce qui se passe, où et quand. Ce sont les conversations avec des personnes derrière les cartes qui alimentent le monde moderne. De longues conversations qui prennent le temps de poser le contexte et d'expliquer la complexité de ces projets ». Voir l'interview de James Killick, cartographe qui a travaillé sur le projet Mapquest, puis chez ESRI et Apple et qui administre le site Map Happenings.
Articles connexes
Avant l'invention du globe virtuel, les stéréoscopes permettaient déjà une forme de voyage visuel
Europe : 12 cartes et un projet (exposition virtuelle de la Bibliothèque nationale d'Espagne)
L'histoire par les cartes : 18 globes interactifs ajoutés à la collection David Rumsey
Les plans de métro : retour sur une représentation simplifiée, souvent détournée
L'histoire par les cartes
Cartes et atlas historiques
- Part 1 — The First Map
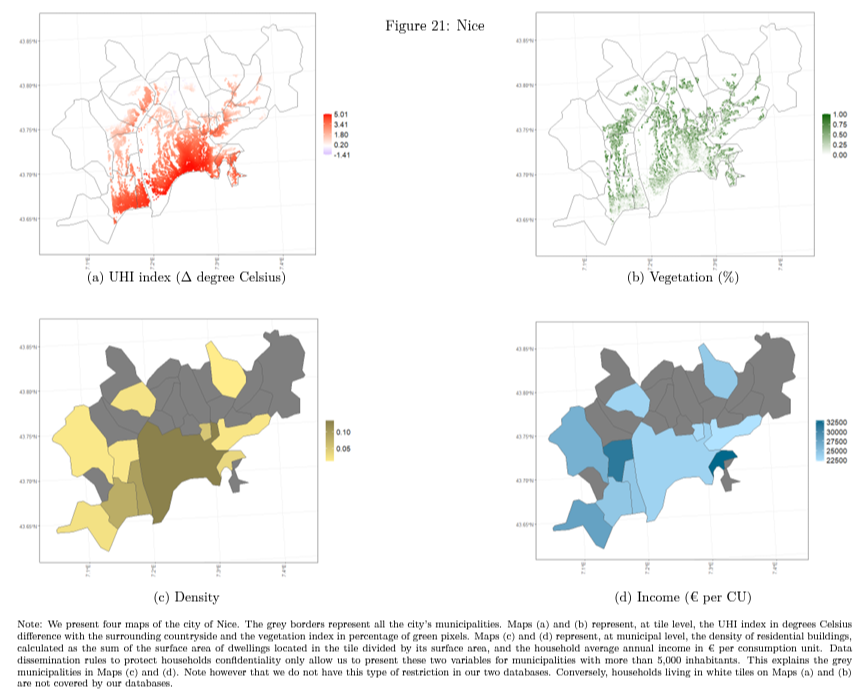

-
sur [Book] Traitements et cartographie de l’information géographique
Publié: 17 November 2024, 6:56pm CET par Françoise Bahoken
Le domaine « Géographie et Démographie » de l’encyclopédie SCIENCES ISTE dirigé par Denise PUMAIN, a récemment publié le troisième des quatre volumes[1] qu’il consacre au champs de la cartographie, coordonné par Colette CAUVIN-REYMOND. Le volume dont il est question porte sur les traitements et la cartographie de l’information géographique.
 Cet ouvrage collectif a été coordonné par Claire CUNTY (Université Lyon 2/UMR EVS) et Hélène MATHIAN (CNRS/UMR EVS) et préfacé par Colette CAUVIN-REYMOND (LIVE, CNRS, Université de Strasbourg).
Cet ouvrage collectif a été coordonné par Claire CUNTY (Université Lyon 2/UMR EVS) et Hélène MATHIAN (CNRS/UMR EVS) et préfacé par Colette CAUVIN-REYMOND (LIVE, CNRS, Université de Strasbourg).
Il suit les deux objectifs suivants : d’une part, de présenter « des méthodes et techniques d’exploitation et de transformation des informations » à des fins de cartographie thématique, en portant une attention tant aux composantes spatiales et temporelles que thématique, en mettant en œuvre des traitement allant de la production d’indicateurs à la modélisation spatio-temporelle des données mobilisées ; d’autre part, de souligner « l’importance et l’interdépendance des différentes étapes de la construction cartographique, ou l’étape des traitements est centrale ».Cet ouvrage est par conséquent focalisé sur la cartographie de données statistiques, réalisée dans le cadre d’une approche quantitative de l’analyse cartographique, plus précisément d’une approche d’analyse spatiale des données [et non seulement d’analyse des données spatiales ou localisées]. Il suit ainsi des principes rigoureux s’intéressant à la sélection des données ; aux traitements numériques et géo-carto-graphiques (du calcul d’indicateurs aux modélisations spatio-temporelles) à effectuer, incluant donc des « transformations cartographiques » (voir Figure 1) et à leur modalités de représentations « qui découlent des traitements choisis » ; tout cela, pour produire une image cartographique sensée, productrice de connaissance sur des structures spatiales.
Cette précision m’apparaît essentielle à l’heure du geoweb et de la popularisation du support-écran qui ont conduit à la prolifération de cartographies et d’images thématiques de toutes sortes, qui mettent d’avantage l’accent sur le design de la carte, sur son apparence visuelle plutôt que sur les traitements et opérations cartographiques réalisés en amont de la stylisation de la carte.Figure 1. Les transformations cartographiques

L’enjeu de cet ouvrage est, d’après les deux coordinatrices, de présenter les opérations de transformations qui relèvent des composantes spatiales (X,Y), thématiques (Z) dans une perspective cartographique (transformations d’état et de positions) qui correspondent aux entrées T2a, T2b et T3 du diagramme proposé par Colette CAUVIN (2008).
Ces différentes opérations cartographiques sont présentées, décomposées et systématiquement détaillées suivant différents contextes thématiques dans huit chapitres qui s’enchaînent selon une suite de progression assez logique, tout en restant nécessairement interreliés.
Chapitre 1. Cartes et graphiques pour explorer des relations statistiques (Jean-Benoit BOURON, Claire CUNTY, Hélène MATHIAN et Myriam BARON)
Chapitre 2. Intégration de données hétérogènes et représentations cartographiques du Géoweb (Marianne GUÉROIS et Malika MADELIN)
Chapitre 3. Données environnementales et objets cartographiques (Étienne COSSART)
Chapitre 4. Cartographier et identifier les formes géographiques : l’exemple de la ségrégation (Sylvestre DUROUDIER)
Chapitre 5. Carte et modèle statistique pour explorer l’hétérogénéité spatiale (Mohammed HILAL et Julie LE GALLO)
Chapitre 6. Cartographier les phénomènes temporels (Claire CUNTY et Hélène MATHIAN)
Chapitre 7. Cartogrammes, anamorphoses : des territoires transformés (Anne-Christine BRONNER)
Chapitre 8. Exploration, agrégation et visualisation spatiotemporelle de données massives (Claude GRASLAND)La description de ces chapitres fait l’objet d’une magnifique carte des chapitres montrant « ce qui les relie, les notions qui les jalonnent » présentée dans l’introduction proposée en accès libre, sur le site de l’éditeur.
Figure 2. La carte des chapitres de l’ouvrage Traitements et cartographie de l’information géographique
 Source : Cunty C. et Mathian H. (2023)
Source : Cunty C. et Mathian H. (2023)Les enjeux liés aux supports contemporains de la cartographie ne sont pas en reste, l’ouvrage abordant également la dimension heuristique de la production cartographique par le prisme des modalités d’exploration et de géovisualisation où la carte est « une interface et devient le résultat temporaire du report d’information thématique sur un fond de carte pour en connaître la répartition spatiale. L’apport de connaissances et parfois le pouvoir révélateur de ces dispositifs ne sont pas à démontrer », lorsqu’ils sont mis en œuvre de manière non génériques, comme le précisent les coordinatrices dans la conclusion, afin de ne pas « appauvrir la production cartographique ».
Pour finir, un très bel ouvrage qui met l’accent sur une approche réflexive de la production cartographique contemporaine… qui mériterait de se trouver au pied de votre sapin !
Commander l’ouvrage sur le site de l’éditeur
___________________________________
[1] Les trois autres volumes portant sur la cartographie sont consacrés à 1) l’histoire de la cartographie, à 2) l’information géographique et à la cartographie et 4) la communication cartographique publiée en français (MERICSKAY, coord. 2021) et en anglais (MERICSKAY, coord. 2024).
—–
Références :
CAUVIN C., ESCOBAR F., SERRADJ (2008), Cartographie thématique. Des voies nouvelles à explorer. Hermès Lavoisier.
MERICSKAY B. (coord.), 2021, Communication cartographique : sémiologie graphique, sémiotique et géovisualisation, ISTE Editions. Accéder
MERICSKAY B. (coord.), 2024, Cartographic communication: graphic semiology, semiotics and Geovizualisation, ISTE Editions. Accéder
—–
Billet lié : [Book] Communication cartographique
Géographe et cartographe, Chargée de recherches à l'IFSTTAR et membre-associée de l'UMR 8504 Géographie-Cités.

-
sur Une cartographie du génocide à Gaza (Forensic Architecture)
Publié: 17 November 2024, 8:42am CET
« Une cartographie du génocide : la conduite d'Israël à Gaza depuis octobre 2023 » (Forensic Architecture).Depuis le début de la campagne militaire israélienne à Gaza en octobre 2023, Forensic Architecture collecte des données relatives aux attaques contre les civils et à la destruction des infrastructures par l'armée israélienne. L'analyse de ces activités révèle la destruction quasi totale de la vie civile à Gaza. Le site a collecté et analysé également les ordres d'évacuation émis par l'armée israélienne dirigeant les civils palestiniens vers des zones de Gaza désignées comme « sûres ». Ces ordres ont entraîné des déplacements répétés et à grande échelle de la population palestinienne à travers Gaza, souvent vers des zones qui ont ensuite été attaquées par Israël.
Les conclusions de Forensic indiquent que la campagne militaire israélienne à Gaza est organisée, systématique et vise à détruire les conditions de vie et les infrastructures civiles nécessaires à la vie.
À cette fin, la plateforme « Une cartographie du génocide » et le rapport qui l’accompagne élaborent une cartographie complète de la conduite militaire à Gaza depuis le 7 octobre 2023. Elle déploie une gamme de méthodes pour observer la manière dont les opérations militaires d’Israël ont engendré des dommages généralisés et suggère comment ces observations pourraient éclairer des évaluations plus larges de la conduite militaire d’Israël pendant cette période.
Le terme « génocide » est utilisé au sens du juriste polonais Raphaël Lemkin, dont la réflexion a été déterminante pour la définition formulée à l'article II de la Convention de 1948. Le génocide, selon Lemkin, signifie un plan coordonné d'actions visant à la destruction des fondements essentiels de la vie des groupes nationaux, dans le but d'annihiler ces groupes eux-mêmes.
Les résultats de plus d'un an de surveillance et de recherche sont disponibles en ligne :
- Une plateforme cartographique interactive : « Une cartographie du génocide »
- Un rapport de 827 pages : « Une analyse spatiale de la conduite de l'armée israélienne à Gaza depuis octobre 2023 »
Les données collectées et analysées permettent de mettre en évidence 6 catégories spécifiques de conduite militaire :
- Contrôle spatial – le façonnage physique de Gaza selon une conception stratégique ;
- Déplacement – les déplacements répétés et forcés de civils et une évaluation des « mesures humanitaires » d’Israël ;
- Destruction de l’agriculture et des ressources en eau – destruction des champs, des vergers, des serres, des infrastructures agricoles et hydrauliques ;
- Destruction des infrastructures médicales – ciblage systématique des hôpitaux et du personnel de santé ;
- Destruction des infrastructures civiles – ciblage des services publics, des routes, des écoles, y compris celles servant d’abris, des édifices religieux et des bâtiments gouvernementaux ;
- Ciblage de l’aide – ciblage systématique des infrastructures et du personnel nécessaires au transport et à la distribution de l’aide humanitaire et à la préparation de la nourriture.
Voir aussi :- Cartographie des massacres – une carte des atrocités commises par le Hamas le 7 octobre.
- Carte des dégâts causés à Gaza - évaluation des dégâts causés aux bâtiments à Gaza
- Comment la guerre entre Israël et le Hamas a transformé Rafah à Gaza - cartographie des bâtiments endommagés à Rafah
- Comment Gaza sera reconstruite – cartographie des niveaux de dégâts à Gaza
- Quels pays ont soutenu la procédure de l'Afrique du Sud contre Israël auprès de la CIJ pour génocide ? (Le Grand Continent)
- Yann Jurovics et Iannis Roder, « Parler de génocide à Gaza est un non-sens juridique » (Le Monde)
- Amos Goldberg, historien israélien : « Ce qui se passe à Gaza est un génocide, car Gaza n’existe plus » (Le Monde)
- « Cartographie du génocide : pourquoi Netanyahou a effacé la Palestine de la carte » (Middle East Monitor)
- Olivier Beauvallet, « Lemkin, une œuvre en un mot : l’invention du génocide » (Les Cahiers de la Justice, 2014)
Liens ajoutés le 18 novembre 2024UNOSAT Bande de Gaza 7e évaluation complète des dommages - mai 2024
— Sylvain Genevois (@mirbole01) June 5, 2024
Environ 55 % du total des structures de la bande de Gaza et 135 142 logements endommagés, selon les estimations
Données SIG à télécharger [https:]] pic.twitter.com/Ib8GCNhya6Des images satellite montrent des Gazaouis contraints de s'entasser dans la ville de campement d'Al-Mawasi (une parcelle de terre côtière de la taille de l'aéroport d'Heathrow sur la côte méditerranéenne de Gaza ) [https:]] pic.twitter.com/N8PrqVEhi2
— Sylvain Genevois (@mirbole01) May 17, 2024
Lien ajouté le 23 novembre 2024Urbicide à Gaza
— Sylvain Genevois (@mirbole01) June 25, 2024
Suivi des dommages matériels sur les logements et équipements publics (écoles, hopitaux, bâtiments officiels...). Plus de 60% des infrastructures détruites [https:]]
5/ pic.twitter.com/ndvNBPjIEP
Articles connexesEthnic cleansing is unfolding in northern Gaza. We are witnessing an intensification and acceleration of military tactics previously used by the Israeli military throughout the Strip, this time aimed at enforcing large-scale displacement from the north. Analysis of Israeli ground… pic.twitter.com/IcRU7deWJj
— Forensic Architecture (@ForensicArchi) November 22, 2024
Israël-Hamas. Cartographie des massacres du 7 octobre 2023
Décrypter le conflit Israël-Hamas à partir de cartes
Palestine Open Maps, un site pour obtenir des cartes et des données spatiales sur la Palestine
Le Moyen-Orient, une construction instable et récente : la preuve en cartes et en schémas
La carte, objet éminemment politique : la cartographie du Moyen-Orient entre représentation et manipulation
La carte, objet éminemment politique. Les manifestations pro-palestiniennes aux États-Unis et dans le monde
La carte, objet éminemment politique : l’Etat islamique, de la proclamation du « califat » à la fin de l’emprise territoriale
La carte, objet éminemment politique : Nétanyahou menace d'annexer un tiers de la Cisjordanie s'il est réélu
La carte, objet éminemment politique : la montée des tensions entre l'Iran et les Etats-Unis
-
sur L'histoire par les cartes : histoire du quartier Richelieu à Paris (1750-1950)
Publié: 16 November 2024, 7:19am CET
Le site dédié au projet de recherche Richelieu. Histoire du quartier (1750-1950) est né de la collaboration de plusieurs institutions publiques situées au cœur du IIe arrondissement de Paris dont la BNF, l'Institut national d'histoire de l'art, l'École nationale des chartes, le Centre Allemand d'histoire de l'art DFK Paris, et le Centre André Chastel Sorbonne Université.Ce projet étudie le patrimoine du quartier compris entre le Louvre, l’Opéra, la place des Victoires et les grands boulevards, communément désigné sous le nom de "Richelieu" , à travers ses dynamiques architecturales, humaines et économiques et en croisant des sources iconographiques et cartographiques.
La navigation s'effectue à partir de thèmes regroupant des documents iconographiques ou à partir de la carte qui permet d'identifier l'implantation des rues, des bâtiments, des jardins à l'échelle des parcelles cadastrales. La carte interactive donne un accès direct à chaque source avec son descriptif.
Site du projet de recherche Richelieu. Histoire du quartier (1750-1950).Le project Richelieu donne accès aux données de la recherche produites et réutilisées, ainsi qu'au code et aux outils numériques produits, sous des licences libres. L'ensemble des données du projet sont disponibles sous licence Creative Commons CC BY-BC-SA 4.0, qui permet le partage, la réutilisation et la modification des données.
Pour accéder aux données brutes, une API est disponible et permet une réutilisation facile. Un datapaper est en cours de constitution pour faciliter la réutilisation des données du projet. Pour citer les données du projet :
Duvette, C., Thiroux, L., Gain, J., Kervegan, P., Akgönül, T., Dasilva, E., & Baranger, L. (2024). Richelieu. Histoire du quartier (données de recherche) (1.0). [https:]]
L'intégralité des outils produits par le projet Richelieu sont accessibles sur le dépôt GitLab de l'INHA. Plus spécifiquement, le code du site est disponible à cette adresse. Le code produit par le projet Richelieu est rendu disponible sous la licence libre GNU GPL v. 3.0. Pour citer le site :
Kervegan, P., Hervieu, M., Duvette, C., Thiroux, L., Gain, J., Akgönül, T., Dasilva, E., & Baranger, L. (2024). Richelieu. Histoire du quartier (site) (1.0). 2024-11. [https:]]
Articles connexes
Plans et rues de Paris d'hier à aujourd'hui
Découvrir le Paris de la Révolution française en arpentant la ville
Parcours guidé dans le plan routier de la ville et des faubourgs de Paris en 1789 (Gallica - BnF)
L'histoire par les cartes : Gens de la Seine, un parcours sonore dans le Paris du XVIIIe siècle
L'histoire par les cartes : une cartographie historique du Paris populaire de 1830 à 1980
Les plans historiques de Paris de 1728 à nos jours (APUR - Cassini Grand Paris)
Découvrir Paris à travers les grands classiques de la littérature
L'histoire par les cartes : cartes et ressources sur la Commune de Paris
L'histoire par les cartes : la carte archéologique de Paris
L'histoire par les cartes : les photographies de la Commission du Vieux Paris
Le projet JADIS pour ajouter des données sur des cartes historiques géolocalisées. L'exemple des plans de Paris
La carte de Cassini embellie sur le site du Géoportail
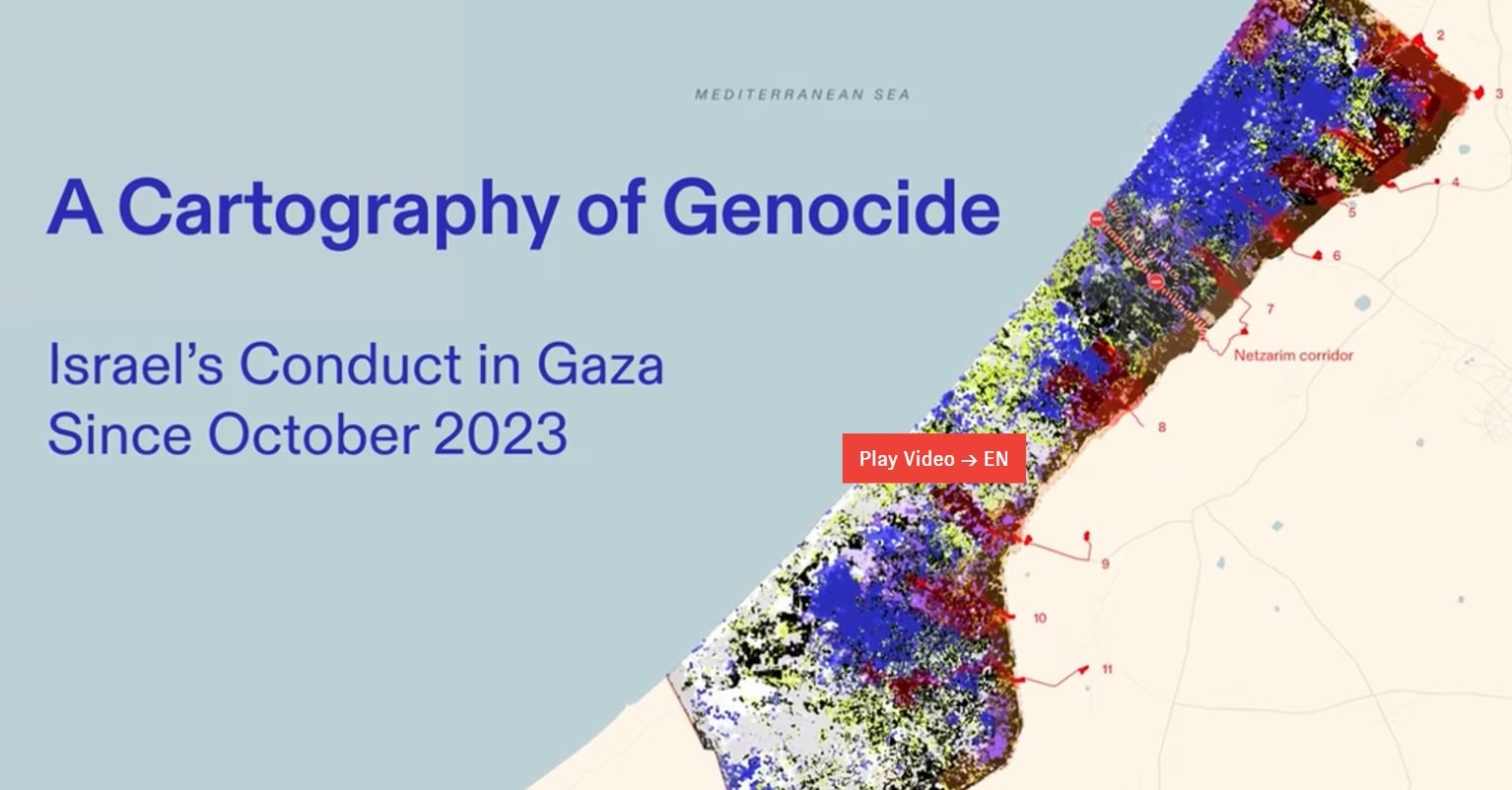
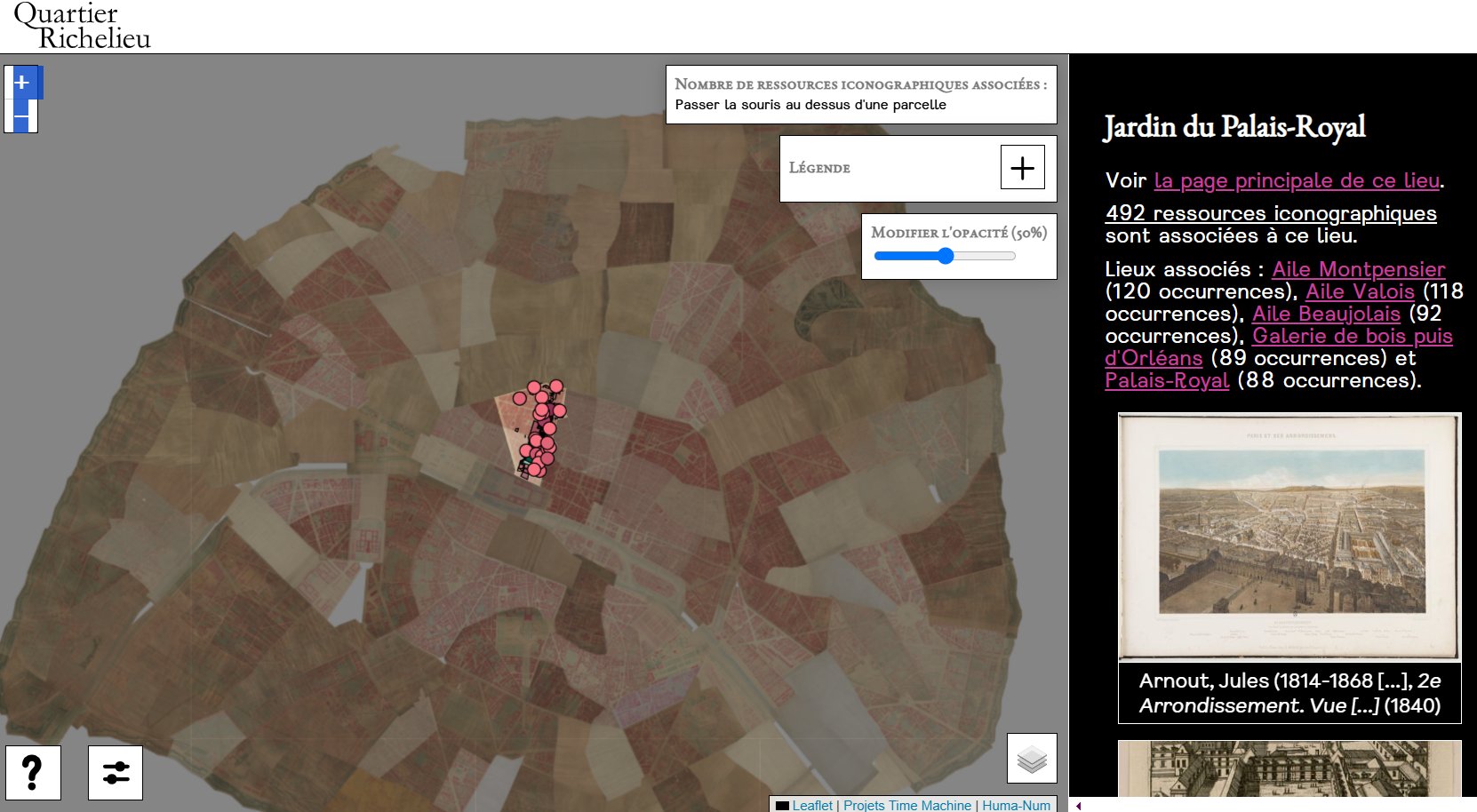
-
sur Mini-guide à l’usage des collectivités : l’Open Data, entre nécessité et opportunité
Publié: 15 November 2024, 5:55pm CET par Olivia Duval
Tout ce que vous avez toujours voulu savoir sur l’Open Data. Petit guide à destination des collectivités pour l’appréhender et se l’approprier.
-
sur L'histoire par les cartes : Atlas historique du Ciel
Publié: 14 November 2024, 4:02am CET
Pierre Léna et Christian Grataloup (2024). Atlas historique du Ciel. Vivre sous le Ciel et comprendre l’Univers : une quête de toutes les sociétés humaines. Éditions Les Arènes.
Toutes les sociétés ont cherché à comprendre l’Univers. Les premiers passionnés du ciel étaient aussi bien mathématiciens que philosophes, horlogers que navigateurs. Ils s’appelaient Thalès, Ptolémée, Al-Khwarizmi, Kepler, Galilée, Newton, Shoujing, Einstein, Herschel, Hubble… Grâce à eux, nous envoyons aujourd’hui des fusées dans l’espace, nous explorons la Lune et les planètes, nous cherchons à savoir s’il existe une vie extraterrestre… Cet atlas raconte l’histoire des découvertes de ces hommes et de ces femmes, connus ou anonymes, qui sur tous les continents ont participé à cette formidable épopée. Avec le concours de Sciences et Avenir/La Recherche, Pierre Léna et Christian Grataloup ont réuni les meilleurs chercheurs (physiciens, anthropologues, historiens, astronomes…) pour rendre accessibles 6000 ans de découvertes. Un atlas qui est autant un livre d’histoire qu’un livre de science.
Pour la sortie en librairie de l'Atlas historique du Ciel de Christian Grataloup et Pierre Lena, les éditions Les Arènes présentent plusieurs double-pages :- Constellations et catalogues du ciel
- Le zodiaque et l'astrologie
- L'ouest archaïque de l'Eurasie
- Les précurseurs hellènes
- Les télescopes
- Les télescopes optiques
- Des observatoires dans l'espace
« Satellite Starlink ou météore : quel était l’objet lumineux vu dans le ciel en France ? » (Numerama). La lumière qui a traversé le ciel français le mardi 27 août 2024 était bien due au retour sur Terre de l'un des 6000 satellites Starlink d'Elon Musk. Il pourrait en envoyer jusque 40 000 dans l'espace.
« Le ciel vu des Missions » (Esquisa Fapesp).Avec des télescopes fabriqués avec le peuple Guarani du sud du Brésil, le jésuite Buenaventura Suárez a observé avec précision les éclipses lunaires et solaires et les lunes de Jupiter auXVIIIème siècle.
L'Atlas Coelestis de John Seller (1700) est l'un des premiers atlas céleste de poche et le premier atlas céleste publié en Angleterre. C'est grâce aux progrès de l'astronomie que les bases de la géographie vont être posées au XVIIIe siècle, notamment à travers la fixation des grands repères (voir par exemple l'Atas Coelestis de Johann Gabriel Doppelmayr, 1742)
« Atlas international des nuages et des types de ciels » (Office international météorologique, 1939).
La première classification des nuages qui ait été publiée ne remonte qu'au début du XIXe siècle et est due à Lamarck (1802). Le célèbre naturaliste ne se proposait pas de classer tous les nuages possibles. La Conférence Météorologique Internationale, tenue à Munich en 1891, recommanda expressément une classification et accrédita un Comité spécial chargé de la mettre au point définitivement et de la publier avec illustrations sous forme d'Atlas.
L'Atlas Farnèse est une sculpture en marbre du IIe siècle après JC. C qui s'inspire d'un original hellénistique. C'est la plus ancienne représentation du globe céleste avec un total de 42 constellations.
Articles connexes
L'histoire par les cartes : Atlas historique de la Terre
L'histoire par les cartes : Atlas historique mondial
L'histoire par les cartes : Atlas historique de la France
Les grands événements de l'Histoire mondiale expliqués en cartes
L'histoire par les cartes : une carte animée de la "densité impériale" à travers les époques
Atlas de l'Anthropocène : un ensemble de données sur la crise écologique de notre temps
-
sur Quand les cartes révèlent les frontières fantômes
Publié: 13 November 2024, 1:17pm CET
Certaines frontières continuent à vivre après leur mort. Dans son dernier ouvrage, Les Provinces du temps. Frontières fantômes et expériences de l’histoire (2023), Béatrice von Hirchhausen piste les traces qu’elles laissent dans nos imaginaires géographiques et qui structurent l’expérience politique - présente et future.« La frontière fantôme désigne les traces laissées par des frontières défuntes dans les sociétés contemporaines et dont on repère l’actualisation fluctuante dans des cartes exprimant des choix sociétaux... L’intuition de ce concept vient d’une question qui m’obsède depuis longtemps, celle des longues durées, des traces du passé et des rémanences que j’observais dans les paysages et sur les cartes de l’Europe centrale et orientale [...] J’en suis effectivement venue à réserver le terme "fantôme" aux traces que l’on observe dans les cartes qui engagent les choix des acteurs locaux. Ce sont par exemple les cartes électorales. Quand on prend les cartes électorales depuis les élections libres de Pologne de 1989, on voit apparaître une géographie structurée entre les trois anciens empires qui se partageaient ce territoire. On voit même apparaître quatre blocs car la partie de l’ancien empire allemand qui n’a été intégrée au territoire polonais qu’après 1945 présente un visage singulier. Ces cartes électorales sont compliquée à expliquer ». Source : « Traverser les frontières fantômes, une conversation avec Béatrice von Hirschhausen » (Le Grand Continent)
« La métaphore de la "frontière fantôme" permet à l’auteure d’enquêter sur l’apparition de discontinuités d’ordre géoculturel, celles-ci pouvant à la fois relever du passé et des circonstances présentes, de la réalité et des imaginaires. En même temps, la métaphore du fantôme se démarque d’autres métaphores utilisées pour traiter des longues durées géographiques, comme les « prisons de longue durée » dont parlait Fernand Braudel.Les frontières fantômes peuvent être définies comme des "traces de territorialités défuntes dans les sociétés contemporaines". Avec un travail de terrain, la géographe montre que ces frontières sont liées à des géorécits, des récits articulés à l’espace ». (CR des Cafés géographiques)

Béatrice von Hirchhausen (2023). Les Provinces du temps. Frontières fantômes et expériences de l’histoire ( 2023), CNRS éditions.
Les cartes électorales de l’Ukraine et de la Pologne de ces dernières décennies ont souvent donné à voir le dessin des empires passés qui s’étaient partagé ces territoires. Les frontières fantômes sont ces traces laissées par des entités politiques défuntes dans les pratiques sociales contemporaines. Comment et pourquoi des limites territoriales, qui n’ont plus de réalité politique, peuvent-elle réapparaître après plusieurs générations?? Pourquoi semblent-elles s’être imprimées dans l’esprit des gens??C’est à partir de terrains menés en Europe centrale et orientale, et notamment en Roumanie, que Béatrice von Hirschhausen, directrice de recherche au CNRS au laboratoire Géographie-cités, tente de comprendre ce phénomène fascinant. Sillonnée d’anciennes frontières d’empires, la région permet d’observer certains de leurs fantômes. Elle offre un véritable laboratoire pour étudier la production des espaces?: entre histoire et culture, entre routines et imaginaires. Cette analyse géographique de l’action individuelle comme des attitudes collectives, montre comment les sociétés se pensent à partir de l’espace. Elle permet d’expliquer des comportements non par un «?nous?» identitaire ou par des mentalités mais par des conventions locales plus ou moins stables?: «?ici, on fait comme ça?». Une réflexion neuve sur les différences culturelles.
Justine Tentoni, « A la recherche des frontières effacées ». A propos de Béatrice Von Hirschhausen, Les Provinces du temps. Frontières fantômes et expériences de l'histoire (Non fiction)
À (re)lire : un très beau numéro de la revue L'Espace géographique sur « Frontières fantômes et ambivalence des espaces d’identification ».
« Religion et frontières fantômes en Europe de l’Est » (Geographie-cités).L’Europe de l’Est reste traversée par les frontières fantômes des empires défunts. Ce legs ne vaut que par son actualisation dans le présent, et par rapport au futur espéré, attendu ou redouté. Certaines de ces frontières fantômes sont d’ordre religieux. Entretien Avec Béatrice von Hirschhausen, directrice de recherche au CNRS, membre de l’UMR Géographie-cités, membre du Centre Marc Bloch (Berlin), dans le cadre de la série « A Point nommé (Chaire « Yves Oltramare – Religion et politique dans le monde contemporain ») de Jean-francois Bayart, Geneva Graduate Institute, 22 mars 2023.
(Re)écouter le podcast « Avez-vous déjà franchi une frontière fantôme ? » (Géographie-cités)Les frontières fantômes : l’exemple des cartes électorales en Pologne : Visio-conférence de Beatrice Von Hirschhausen / Traduction en russe : Ivan Savchuk @EHESS_fr
« Les frontières fantômes, un nouveau concept pour penser le mur dans les têtes ? » (Revue Abibac)
« Avez-vous déjà franchi une frontière fantôme ? » (Radio France)« On a vu des frontières fantômes apparaître, par exemple au moment des élections en Allemagne. Sur la carte, les territoires de l'ancienne RDA affichaient des votes très spécifiques. La frontière fantôme est une frontière politique qu'on voit réapparaître dans certaines circonstances, soit dans le paysage, soit dans des attitudes et des pratiques sociales »
Nous sommes en 2023, 109 ans après le début de la Première Guerre mondiale, et pourtant les frontières impériales d’avant la Première Guerre mondiale sont toujours visibles sur la carte électorale de la Pologne – et sur bien d’autres, d’ailleurs. Par Szymon Pifczyk, @sheemawnIt's 2023, 109 years after WW1 started, yet the pre-WW1 imperial borders are still visible on the election map of Poland - and on many others, for that matter.
— Szymon Pifczyk (@sheemawn) October 17, 2023
A thread ???--> pic.twitter.com/ihNOHRniaPC'est le fantôme du passé de la Pologne. Les Polonais appellent ce type de carte « wida? zabory » (partition visible).
Vous avez peut-être vu récemment un gif animé montrant le retard de l’Allemagne de l’Est. Même si le communisme a un rôle à jouer dans ce retard, ce n’est pas le seul facteur. Il s’avère que l’Allemagne de l’Est était différente du reste de l'Allemagne avant même d'être communiste.This is the ghost of Poland's past
— Tomas Pueyo (@tomaspueyo) February 23, 2024
Poles call this type of map "wida? zabory": "You can see the partitions"
What partitions?
Why is Poland like that today?
What does it tell us about the country?
About Russia? Germany?
Let's explore: pic.twitter.com/tAhO0gTvywYou might have seen a .gif recently showing the backwardness of Eastern Germany.
— Crémieux (@cremieuxrecueil) February 21, 2024
While Communism has its role to play in that backwardness today, it's not all there is.
But as it turns out, Eastern Germany was different from the rest before it was Communist. pic.twitter.com/yQwVozNJKD
Articles connexesLa carte, objet éminemment politique
— Sylvain Genevois (@mirbole01) June 10, 2024
Résultats d'élection et persistance des "frontières fantômes" en Allemagne... même s'il faut se méfier des cartes de résultats électoraux ne donnant que le parti en tête [https:]]
Comment les frontières politiques façonnent les paysages. Une série d’images satellites Planet en haute résolution
Doit-on se méfier des cartes ethno-linguistiques ?
Frontières et groupes ethniques à travers le monde
Les frontières maritimes des pays : vers un pavage politique des océans ?
Cartes et données sur les communes allemandes à partir du recensement de 2022 (Wahlatlas.net)

-
sur Cartographie musicale avec TerraVisu
Publié: 13 November 2024, 9:58am CET par Marine Faucher
Et si, au lieu de simplement regarder une carte, vous pouviez aussi l’écouter?? Imaginez : chaque lieu, chaque paysage s’exprimant en musique ou en sons d’ambiance.
-
sur Cartes et données sur les communes allemandes à partir du recensement de 2022 (Wahlatlas.net)
Publié: 13 November 2024, 5:37am CET
Le site Wahlatlas.net rassemble un grand nombre de cartes et de données sur les élections en Allemagne depuis le début des années 2000. Il vient de s'enrichir de nouvelles cartes concernant le recensement de 2022.Elections fédérales de 2021 en Allemagne (source : Wahlatlas.net)

Outre les données électorales, on y trouve pour chaque commune d'Allemagne (au nombre de 10 786) des données issues du recensement 2022. Ces données détaillées concernent la structure par âge, l'origine et le pays de naissance, la taille des familles, les loyers, le taux de propriétaires, le taux de maisons individuelles, la taille des appartements, leur taux de vacance, la durée d'habitation, les sources d'énergie et le type de chauffage. Le tout sous forme de graphiques animés, de tableaux et de cartes interactives (données en grille de 100 mètres).
Le principal intérêt du site est de fournir une cartographie détaillée à l'échelle des quartiers de chaque ville allemande (voir par exemple Berlin). A compléter par l'Atlas électoral de Berlin (wahlen-berlin.de/)

Accès au site Wahlatlas.net.
Accès direct au Wahlatlas 2022 et au Wahlatlas 2011.
Accès au Zensus2022, site officiel du recensement en Allemagne, et aux données sur une grille de 100m.
Suivre le compte @wahlatlas sur les réseaux sociaux Twitter ou Mastodon.
Articles connexes
Résultats des élections au Bundestag en Allemagne (26 septembre 2021)
L'histoire par les cartes : les 30 ans de la chute du mur de Berlin (1989-2019)
Les transferts de population à l'intérieur de l'Allemagne depuis 1991 à travers une infographie
Quand les cartes révèlent les frontières fantômes
Cartes et plans historiques sur l'Allemagne centrale
-
sur Carte des oeuvres du Louvre exposées hors du musée
Publié: 12 November 2024, 6:41pm CET
Le site du musée du Louvre propose une carte interactive des œuvres itinérantes dont il dispose à travers la France, grâce à la politique active de dépôts que le musée mène depuis sa création en 1793.« C’est accroché près de chez vous ! » (source : Musée du Louvre)
Attention : Cette carte n’est pas exhaustive. Ne sont mentionnées que les œuvres pour lesquelles
il existe une notice sur le site collections.louvre.fr. Voir la carte en grand format.Qu’est-ce qu’un dépôt ? Lorsque le musée du Louvre effectue un dépôt, cela signifie qu’il prête - pour une longue durée - une ou plusieurs œuvres de ses collections à un autre lieu institutionnel, tel qu'un musée, une université, un édifice religieux, une mairie, un ministère, une préfecture ou encore une ambassade. En cela, le Louvre répond à un objectif clairement posé par la Révolution : rendre le musée accessible à tous en exposant ses œuvres hors-les-murs et en diffusant les collections nationales sur l’ensemble du territoire.
La pratique des dépôts du musée du Louvre est ancienne. Elle remonte officiellement à un arrêté fondateur dans l’histoire des musées de France : l’arrêté du 1er septembre 1801 souhaité par Jean-Antoine Chaptal, ministre de l’Intérieur de Napoléon Bonaparte. Ce dernier propose de doter les grandes villes de province d’œuvres issues des collections de l’État afin d’encourager la décentralisation de la politique culturelle et de soutenir l’éducation sur l’ensemble du territoire français.
En 1910, le premier décret portant sur les dépôts d’œuvres d’art appartenant à l’État dans les provinces permet de régulariser les pratiques tout en réaffirmant un contrôle des œuvres par l’administration centrale. Il faut attendre 1981 pour qu’une liste officielle des lieux pouvant accueillir des dépôts des musées nationaux soit publiée, excluant les nouveaux dépôts dans les administrations publiques (ministères, assemblées parlementaires), les lieux de culte ou encore les universités. Enfin, la loi « Musées » de 2002 introduit le transfert des dépôts anciens de l’État au profit des collectivités territoriales selon des critères stricts.
Aujourd’hui, le musée du Louvre continue de déposer des œuvres dans les institutions répondant aux exigences requises par la loi, en lien avec les projets scientifiques et culturels (PSC) de ces musées de France. Ces dépôts sont consentis pour une durée de 5 ans renouvelables. Leur présence chez le dépositaire ainsi que leur état de conservation sont vérifiés par les équipes scientifiques du musée du Louvre à l’occasion du récolement décennal. Les œuvres sont photographiées, mesurées et documentées. Plus de 27 000 œuvres sont ainsi récolées tous les dix ans dans plus de 600 lieux de dépôts en France et à l’étranger.
Au-delà de cette politique de dépôt, le musée du Louvre soutient le développement des musées territoriaux par le biais de partenariats et le développement de collaborations scientifiques (notamment à Lens, Brest, Avignon, Le Mans, Dijon, Bayonne, Castres, Rennes, Montauban, Grenoble, Lyon, Arles, Nîmes ou encore Saint-Romain-en-Gal). La création du Louvre Lens en 2012 et du Louvre Abu Dhabi en 2017 illustre la volonté du musée du Louvre de poursuivre sa politique de décentralisation initiée depuis plus de deux siècles.
Malgré ces efforts pour décentraliser et faciliter l'accès, la répartition reste inégale avec une forte concentration des oeuvres d'art dans les grandes villes, en particulier Paris.
Répartition des oeuvres d'art en France tous musées confondus (source : catalogue Joconde)
Pour compléter
Catalogue des collections du musée du Louvre
[https:]]Portail numérique Corpus d’accès aux sources et aux données de la recherche
[https:]]Base Joconde, catalogue collectif des collections des musées de France
[www2.culture.gouv.fr]
https://data.culture.gouv.fr/explore/dataset/base-joconde-extrait/Articles connexes
ArchéOdyssée, une carte interactive de plus de 800 musées et sites archéologiques en France
Une carte pour recenser les objets africains dans les musées du monde
L'histoire par les cartes : le Rijksmuseum met à disposition plus de 700 000 œuvres sur le web, notamment des cartes
Le peintre hollandais Vermeer et les cartes
L'histoire par les cartes : la British Library met à disposition la collection du roi George III sur Flickr
Carte des travaux et oeuvres d'art réalisés par le New Deal (Living New Deal)
Cartes et atlas historiques
-
sur Cartographie des résultats à la présidentielle de 2024 aux États-Unis
Publié: 10 November 2024, 8:01pm CET
Ce billet se propose d'analyser la manière dont les médias français et étrangers ont cartographié l'élection présidentielle de novembre 2024 aux États-Unis.
Donald Trump a remporté l'élection présidentielle de novembre 2024 avec 312 grands électeurs pour les républicains contre 226 pour la candidate démocrate Kamala Harris. Fait assez inattendu : le candidat républicain a remporté tous les swing states ou États pivots (Géorgie, Caroline du Nord, Pennsylvanie, Wisconsin, Michigan, Nevada et Arizona) où le scrutin est d'habitude assez serré. Si Trump signe un grand chelem dans les Etats-clés (Libération), ce n'est pas pour autant un raz de marée en nombre de voix. Trump obtient un plus de 74 millions de voix contre un peu moins de 71 millions pour Kamala Harris. Au final, il ne réunit guère plus de voix qu’en 2020. C’est son adversaire qui, elle, décroche par rapport au score réalisé par Joe Biden qui avait réuni plus de 81 millions de voix. Les électeurs démocrates se sont peu mobilisés pour cette élection (score inférieur de 10 millions de voix par rapport au scrutin de 2020). Pour gouverner, Donald Trump pourra s’appuyer sur le Sénat, que les républicains ont repris aux démocrates (source : Le Monde).
Résultats à la Présidentielle américaine de 2024 (Le Monde - Les Décodeurs).jpg)
Les principales raisons invoquées par les électeurs pour ne pas soutenir Kamala Harris sont l'inflation trop forte, l’immigration illégale jugée trop élevée, les questions culturelles et sociétales, notamment les personnes transgenres et le wokisme désignés comme des cibles à combattre pour les républicains. Les démocrates semblent de leur côté avoir délaissé leur électorat traditionnel (classe ouvrière et minorités). Le profond gender gap n’a pas permis à Harris de gagner l’élection (Le Grand Continent). Le dégagisme a pu aussi jouer un rôle, Trump n'étant pas le candidat sortant comme en 2020. Le rôle central d'Elon Musk dans la campagne lui a procuré des avantages comparatifs immenses. Le réseau Twitter/X est devenu une chambre d'écho de ses idées. Surtout Musk, en utilisant la dérégulation du financement politique indépendant, a pu littéralement subventionner sans limite la campagne de Trump (voir la carte des dons pour les deux candidats). Pour Asma Mhalla, politologue spécialiste des enjeux politiques et géopolitiques de la Tech et de l'IA, « ce que Musk apporte à Trump, c’est une sorte de rétrofuturisme, à la fois ultra conservateur bloqué dans les années 1970 et une projection vers le futur qui participe de la puissance trumpienne » (France Inter). « Une nouvelle ère s'ouvre. Les technophiles américains se pavanent désormais dans les couloirs du pouvoir » (The Guardian).
En moins de dix ans, le Parti républicain est devenu le Parti de Trump. Le président élu l’a baptisé le « mouvement Maga » d'après son slogan « Make America Great Again ». Les soutiens et courants sont divers, mais on peut les classer selon un triptyque simple : religion, argent et pétrole (Mediapart). Pour le politiste Wendy Brown, les facteurs qui permettent de comprendre la nette victoire de Donald Trump face à Kamala Harris sont le populisme économique, l’épuisement de la démocratie libérale, la destruction de l’éducation, en particulier de l’enseignement supérieur (AOC media). Les gains de Donald Trump chez les Latinos ont été décisifs (sauf à Porto Rico qui reste un bastion démocrate). Le président républicain élu n'a progressé que très modestement chez les électeurs noirs et stagné voire un peu régressé parmi les électeurs blancs. Les états de la Rust Belt, marqué par le déclin industriel et démographique, ont voté en majorité pour Trump. Aux facteurs économiques s'ajoutent des facteurs psychologiques. Pour Paul Schorr, historien des États-Unis, « une minorité blanche vieillissante craint que les minorités deviennent la majorité aux États-Unis. Trump joue de cette peur ancienne de l’altérité raciale dont le suprémacisme blanc est le débouché » (Le Monde). Ce n'est pas un hasard si Donald Trump a tenu ses plus gros meetings dans les sundown towns ("villes du coucher du soleil" en majorité constituées de blancs).Sélection de cartes de résultats de la Présidentielle américaine de 2024 sur le site Inconsolata.
Sélection de cartes et data visualisations sur le site Datawrapper. Voir également celles du Spiegel.
Téléchargement des résultats des élections fédérales depuis 1982 sur le site de la Federal Election Commission (FEC).
La collection de cartes des élections présidentielles américaines depuis 1789 (par états sur GisGeography, par états et comtés sur Brilliant Maps).
« L'Amérique de Trump » (Le Dessous des cartes, novembre 2024).
« L’Amérique de Trump, carte des résulats par comtés » (MapPorn). Cette carte choroplèthe montre l'importance du vote républicain (en rouge) par rapport au vote démocrate (en bleu). Il convient toutefois de rappeler que ce ne sont pas les territoires mais les populations qui votent. Comme lors des élections présidentielles de 2016 et 2020, ce type de carte est largement diffusé par les républicains pour alimenter l'idée d'une "vague rouge", d'un raz de marée républicain.
Il convient de se méfier des cartes donnant seulement le candidat arrivé en tête. Un dégradé de couleurs indiquant les scores précis en pourcentages donne déjà une vision plus nuancée. Le site Purple States of America permet ainsi de faire des comparaisons entre élections présidentielles de 1980 à 2024.
Le Financial Times propose une cartographie plus exacte qui rapporte l'importance du vote au poids de la population d'une part et au nombre de Grands électeurs d'autre part.
The Economist en donne une représentation encore plus détaillée sous la forme d'une carte par densité de points.
Karim Douïeb propose une vision alternative de la carte électorale américaine de 2024. Cette carte met à l'échelle les États en fonction de leur poids électoral, préservant ainsi la forme des États pour q'uon puisse les reconnaître. Les formes basées sur des diagrammes de Voronoi pour chaque État montrent le nombre exact d'électeurs.Pour ce que ça vaut : une vue alternative sur la carte des élections américaines de 2024 ??
– Karim Douïeb (@karim_douieb) 6 novembre 2024
Cette carte met à l'échelle les États en fonction du poids électoral, en préservant la forme des États-Unis pour la reconnaissance. Les formes basées sur Voronoi dans chaque État montrent le nombre exact d'électeurs. #Election2024 #DataViz #Cartogram #ElectoralCollege pic.twitter.com/WmKcAI8wKd
Le New York Times propose une carte montrant le décalage de voix (principalement à droite) par rapport au vote présidentiel de 2020.
Bloomberg propose le même type de carte, mais les déplacements de voix y sont indiqués sous la forme de pics en relief.
Le Parisien ne se contente pas de donner le candidat en tête mais fournit le score par comté, ce qui donne une vision plus nuancée. Pour chacun des deux partis, l'évolution est également précisée par rapport à la Présidentielle de 2020.
Quand on représente chaque comté en une bulle dont la taille est proportionnelle à la population, Trump gagne surtout dans les comtés les moins peuplés et perd dans ceux les plus peuplés.
— Nicolas Berrod (@nicolasberrod) 6 novembre 2024
D'où l'impression d'une carte précédente très rouge malgré un score proche de 50-50.
3/9 pic.twitter.com/bBIbDAh2DR
A l'inverse, Kamala Harris fait moins bien que Joe Biden il y a quatre ans dans une très grande majorité des comtés (plus c'est rouge, plus elle fait moins bien).
— Nicolas Berrod (@nicolasberrod) 6 novembre 2024
5/9 pic.twitter.com/JYyHff0RN4
Lors de sa campagne de 2016, Trump a recueilli 12 % des voix à Chicago. En 2024, il a presque doublé son pourcentage, en obtenant 22 %. Trump a remporté le district de la prison du comté de Cook, les districts de la classe ouvrière blanche avec des électeurs parmi les policiers et les pompiers, ainsi que les districts juifs orthodoxes (@FrankCalabrese)En 2016, Trump avait recueilli 12 % des voix à Chicago. Cette fois, il a presque doublé son pourcentage, en obtenant 22 %. Trump a remporté le district de la prison du comté de Cook, les districts de la classe ouvrière blanche avec des électeurs de la police et des pompiers, et les districts juifs orthodoxes. #twill pic.twitter.com/lOWBPxnOR3
– Frank Calabrese (@FrankCalabrese) 8 novembre 2024
Même des états comme New York ou le New Jersey, traditionnellement démocrates, ont connu une progression du vote républicain lors des élections de novembre 2024.Voici l'élection présidentielle de 2024 à New York, cartographiée par circonscription. Trump a obtenu la meilleure performance pour un républicain ici depuis 1988, faisant près de 20 % de mieux qu'en 2020. Il a enregistré les plus fortes hausses dans le Bronx et le sud de Brooklyn. pic.twitter.com/3cQXTIQFIF
– Kraz Greinetz (@krazgreinetz) 7 novembre 2024L'élection du Congrès de 2024 dans le 9e district du Congrès du New Jersey, une compétition entre la sénatrice de l'État de Paterson, Nellie Pou, et le triple candidat éternel Billhy Prempeh, a été la course la plus serrée dans le 9e district du Congrès du New Jersey depuis 1982, pic.twitter.com/lIUrGLUHv2
– sageoftime.bsky.social?? (@SageOfTime1) 9 novembre 2024
Il est difficile de se fier aux experts et aux sondeurs qui n'avaient guère anticipé les résultats. Une étude parue en octobre 2024 avant l'élection présidentielle avait en partie prédit les scores des deux partis. Fondée sur un modèle économétrique appelé « State Presidential Approval/State Economy Model », elle utilisait des données économiques et des taux d'approbation présidentielle pour prédire la part des votes des deux partis dans chaque État. Les prévisions suggèraient que les résultats étaient largement en faveur de Trump 100 jours avant l'élection. Cela pourrait expliquer en partie la décision soudaine du président Biden de se retirer de la course, car le modèle indiquait qu'il avait moins de 10 % de chances de gagner s'il restait candidat. Pour que les démocrates l'emportent, il fallait que Kamala Harris surmonte des problème extrêmement difficiles et/ou que Trump et le Parti républicain gaspillent leur avantage considérable au sein du Collège électoral.Un groupe de politologues a publié cet article en octobre, avant les élections. Ils ont prédit correctement *tous* les États, une victoire du vote populaire pour Trump et une chance sur quatre de victoire de Trump au Collège électoral.
– Mafalda Pratas (@MafaldaPratas) 7 novembre 2024
Les fondamentaux vous en disent plus que les experts et les sondeurs. pic.twitter.com/27EBBlk4Pp
Deux Amérique irréconciliables ? « Comment les Américains démocrates ou républicains achètent, mangent et vivent » (The New York Times). Les auteurs ont passé au crible des millions de magasins, restaurants, salles de spectacles et autres lieux. Si l'on ne sait pas exactement qui fréquente quel lieu, on sait comment votent les lieux qui sont fréquentés. Si il y a des corrélations évidentes (les terrains de golf et les magasins d'armes sont davantage implantés dans des lieux votant républicains, les salles de yoga, les bars à cocktail et les brasseries davantage démocrates), on trouve aussi des corrélations plus surprenantes.« Des millions de déménagements révèlent la polarisation américaine en action » (The New York Times). A partir des registres d'inscription des électeurs, le NYT a analysé plus de 3,5 millions d'Américains qui ont déménagé depuis la dernière élection présidentielle, offrant un aperçu très détaillé de la façon dont les Américains se séparent les uns des autres.
Les chiffres sur l'immigration légale et illégale aux États-Unis ont largement alimenté les débats pendant la présidentielle américaine (VisualCapitalist). « Fermer hermétiquement la frontière et mettre fin à l'invasion des migrants » figure en tête du programme en 20 points écrit en lettres majuscules par le candidat Trump. Il convient au passage de rappeler qu'Elon Musk, ennemi des « frontières ouvertes », a lancé sa carrière en travaillant illégalement (The Washington Post). « Dans les États-Unis de Trump comme en France, l’immigration est devenue un puissant vecteur d’expression des malaises sociaux et de contestation des élites » (Le Monde). La manière d'interpréter ces chiffres peut être source de nombreux biais.Graphique : Immigration nette aux États-Unis, par président (2001-2024) ? https://t.co/RPaFtwQPkO pic.twitter.com/iRWpWLE4qO
— Visual Capitalist (@VisualCap) 17 octobre 2024
La carte objet éminemment politique. Le propriétaire de la société X, Elon Musk a publié le 10 novembre 2024 une capture d'écran d'une diffusion de Newsmax. On y voit apparaître une carte électorale rouge et bleue, état par état, publiée dans l'émission « Carl Higbie Frontline ». L'objectif est de montrer que presque tous les États qui ont élu la vice-présidente Kamala Harris étaient des États qui n'avaient pas de lois sur l'identification des électeurs (sous entendu des migrants auraient pu voter de manière illégale). Il s'agit d'une fausse corrélation, la carte montrant l'identification des électeurs selon les Etats apparaît quelque peu différente sur Wikipedia.Must be a coincidence ? pic.twitter.com/npsMqqatx0
— Elon Musk (@elonmusk) November 10, 2024
Elections américaines et lutte contre la désinformation.
« La plupart des analyses rétrospectives des élections négligent un facteur clé dans la manière dont les gens votent : où ils s’informent » (Politico).
« Lors des élections américaines de 2024, quelles sources ont le plus influencé les décisions de vote ? » (The Journalist' resource).Entre le 30 août et le 8 octobre 2024, une équipe de chercheurs de quatre universités a interrogé des milliers d’adultes américains et leur a posé la question suivante : « Lorsque vous prenez une décision concernant un vote, quelle est votre source d’information la plus importante ? »- Dans l’ensemble de l’échantillon, les discussions avec les amis/la famille et les articles d’actualité ont été les deux principales sources d’information sur les élections en 2024, respectivement 29 % et 26 %. Les recommandations du clergé (2 %) et les médias sociaux (9 %) figuraient parmi les autres sources principales.
- Les démocrates et les indépendants sont plus susceptibles que les républicains de s'appuyer sur les articles d'actualité comme principale source d'information électorale. Un pourcentage plus élevé de républicains ont cité leurs amis et leur famille comme principale source d'information électorale que les démocrates ou les indépendants.
- Les Américains qui n’avaient pas fréquenté l’université étaient plus susceptibles de s’appuyer sur leurs amis et leur famille pour obtenir des informations sur les élections que les Américains ayant fait des études plus formelles, qui étaient plus susceptibles de s’appuyer sur les médias d’information.
- Interrogés spécifiquement sur les sources d’information les plus importantes pour eux au moment de prendre une décision de vote, 41 % des répondants ont choisi les informations télévisées nationales comme principale source d’information.
Le journal Le Point [@claradealberto) propose une infographie originale montrant la relative stabilité du vote républicain et du vote démocrate depuis 1960 à l'échelle de chaque état.
Kenneth Field (@kennethfield) propose une représentation originale des résultats sous forme de cartogramme de Dorling. "Oubliez les cartes en rouge et bleu, celle-ci couvre pratiquement toutes les mesures auxquelles vous pouvez penser, apportant des nuances au résultat". A télécharger en pdf.?? Retour sur l'élection de Donald Trump en cartes@claradealberto #Trump #Harris #DonaldTrump [https:]] pic.twitter.com/qTFtFp3thb
— Le Point (@LePoint) November 10, 2024
Lee Masson propose une analyse des résultats par auto-corrélation spatiale. L'indice de Moran local sert à mesurer l'autocorrélation spatiale, il est utilisé principalement pour détecter des clusters. L'indice de Moran fournit des informations importantes, il peut cependant être difficile à interpréter. C'est la raison pour laquelle l'indice de Moran local est utilisé pour simplifier l'analyse.The 2024 US Presidential Election Eclipse: a multivariate moonpie symbolised Dorling cartogram. Forget red/blue #maps , this one covers virtually every metric you can think of, providing nuance to the result.
— Kenneth Field (@kennethfield) November 20, 2024
Get a hi-res copy: [https:]]
Happy #GISDay #GISChat pic.twitter.com/yozYozEZPh
Ben Schmidt propose une datavisualisation qui montre les changements de polarisation politique aux États-Unis depuis 1840. Le « bastion du Sud » démocrate de 1880 à 1964 est clairement visible ainsi que les régions républicaines qui correspondent traditionnellement à l'Ouest montagneux et aux Grandes Plaines. Mais on observe aussi des évolutions.Interactive plots for Local Moran's I analysis, by Lee Mason [https:]] pic.twitter.com/OrEcHWbGrx
— Nicolas Lambert (@neocartocnrs) November 21, 2024
Articles connexesNew blog post! Updated for 2024, my favorite example of why alphabetical ordering is bad for geographic features -- US presidential results since 1828. The left image shows regional patterns in a geographic ordering that the right (alphabetical) simply loses. benschmidt.org/post/2024-11...
— Ben Schmidt (@bschmidt.bsky.social) 1 décembre 2024 à 17:46
[image or embed]
Simulateur de vote et résultats aux élections présidentielles aux États-Unis
La carte, objet éminemment politique : le monde vu à travers les tweets de Donald Trump
S'initier à la cartographie électorale à travers l'exemple des élections présidentielles de novembre 2020 aux Etats-Unis
L'attaque du Capitole reconstituée en cartes et en vidéos
Cartographie électorale, gerrymandering et fake-news aux Etats-Unis
La suppression de la Racial Dot Map et la question sensible de la cartographie des données ethniques aux Etats-Unis
Le « redlining » : retour sur une pratique cartographique discriminatoire qui a laissé des traces aux Etats-Unis
Analyser les cartes et les données des élections présidentielles d'avril 2022 en France
Dis-moi où tu vis, je te dirai ce que tu votes ? (Géographie à la carte, France Culture)
-
sur Atlas de la distribution des revenus des ménages en Espagne (INE)
Publié: 10 November 2024, 6:50pm CET
Source : Instituto Nacional de Estadística (2024). Atlas de Distribución de Renta de los Hogares (ADRH).L'Atlas de distribution des revenus des ménages est produit par l'Institut national de la statistique (INE) Il combine les registres fiscaux administratifs avec les statistiques démographiques pour fournir des indicateurs socio-économiques granulaires à plusieurs niveaux géographiques. Les données détaillées sont accessibles par communautés autonomes, provinces, communes et secteurs de recensement.
Atlas de répartition des revenus des ménages en Espagne - données 2022 (source : INE)
La carte met en évidence un net contraste entre le nord et le sud de l'Espagne. San Sebastián, Madrid et Barcelone sont les capitales provinciales avec le pourcentage le plus élevé de secteurs de recensement à revenu très élevé. Ces trois villes étaient déjà en tête de ce classement l’année précédente. Parmi les revenus les plus élevés, on trouve le Pays Basque (où 88,4% de ses communes font partie des 25% ayant les revenus les plus élevés d'Espagne et la Communauté Autonome de Navarre (avec 75%). À l'autre extrême, se distinguent la région de Murcie où 84,4% des communes se situent parmi les 25% ayant les revenus les plus bas ainsi que l'Estrémadure (avec 82,5%). L'Atlas permet de conduire des analyses au niveau local. La carte de l'indice de Gini fait apparaître les inégalités entre territoires urbains et ruraux.
Atlas de répartition des revenus des ménages en Espagne - indice de Gini 2022 (source : INE)
L'Institut national de la statistique est l'organisme officiel, chargé de l'élaboration et de la communication des statistiques démographiques, économiques et sociales en Espagne. Comme son homologue l'INSEE en France, cet institut fournit des bases de données statistiques très détaillées sur l'ensemble du territoire et à des échelles très fines.
- Liste des bases statistiques de l'INE classées par thème
- Statistiques expérimentales à partir de données de téléphonie mobile
- Fichiers cartographiques avec contours géoréférencés des sections censitaires
L'Espagne possède certaines des meilleures données sur les revenus au niveau des quartiers en Europe, mais ces données sont enfouies dans le site de l'INE. Les téléchargements en masse ne sont pas disponibles, le site fournit seulement des fichiers individuels dispersés dans les sous-menus. Pablo García Guzmán (@pablogguz_) propose ineAtlas, un package R pour récupérer l'ensemble des données.
- Package R ineAtlas incluant les géométries des secteurs de recensement pour l'analyse géospatiale
- Relier les données sur le revenu au niveau des secteurs de recensement aux résultats électoraux avec ineAtlas
Articles connexes
Étudier la fréquentation touristique dans les villes espagnoles à partir des données de téléphonie mobileUne cartographie détaillée des biens appartenant à l'Église en Espagne
L'histoire par les cartes : la recension des symboles franquistes en Espagne
Qui habite où ? Compter, localiser et observer les habitants réels en France
La baisse de l'espérance de vie au Royaume-Uni et aux Etats-Unis: un révélateur des écarts entre les revenus ?
- Liste des bases statistiques de l'INE classées par thème


.jpg)


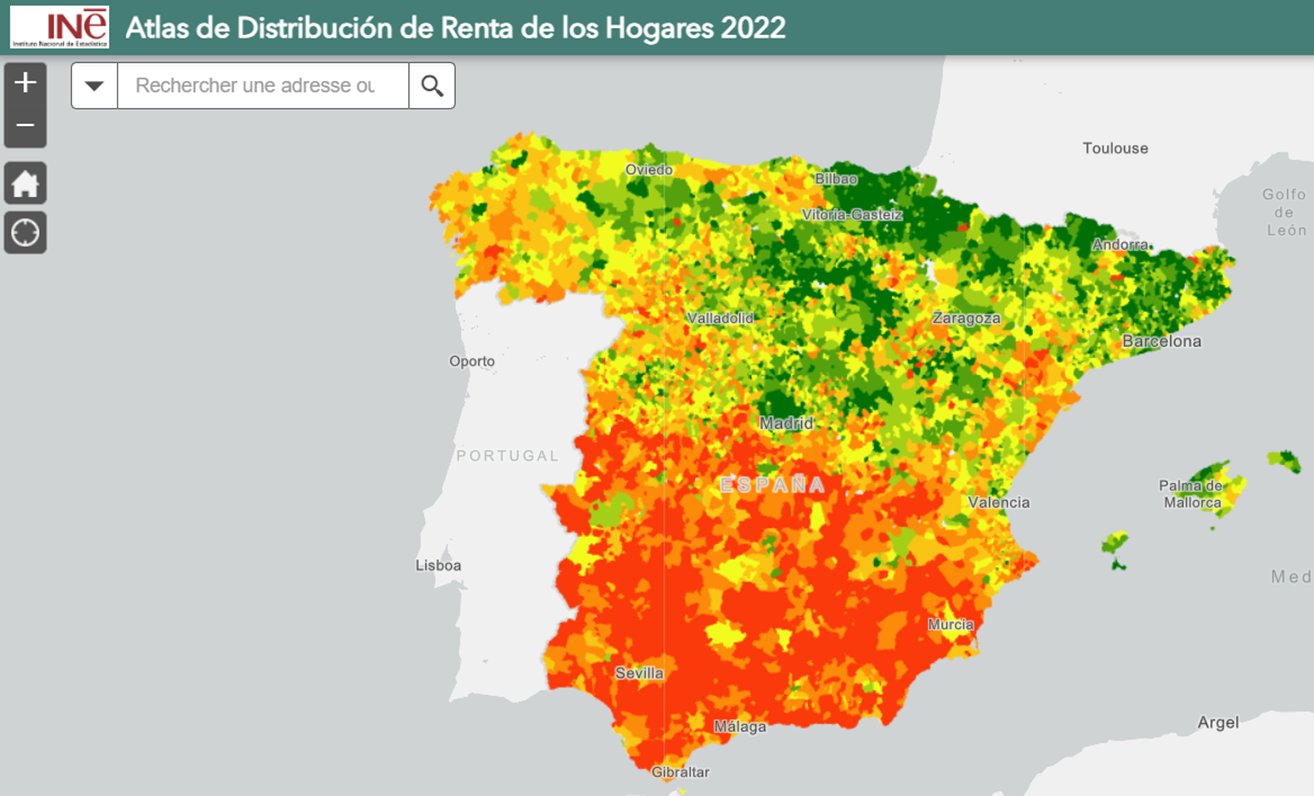
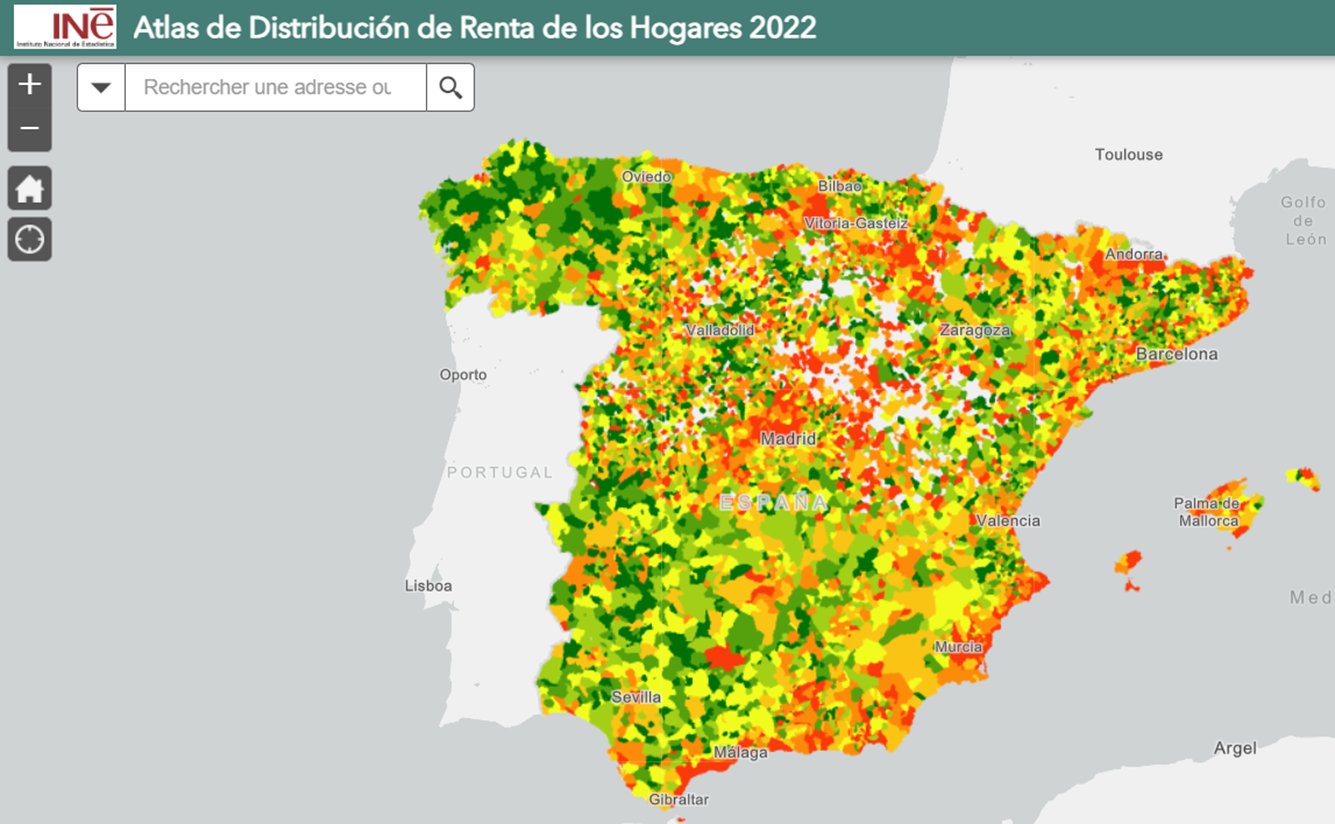
-
sur Examind C2 : pour la préparation et la conduite de missions !
Publié: 8 November 2024, 4:31pm CET par Jordan Novais Serviere
Une nouvelle solution Examind pour la préparation et la conduite de missions !
- 08/11/2024
- Jordan Serviere
Dans un contexte où la maîtrise de l’information est essentielle à la prise de décision, Geomatys dévoile Examind C2, le dernier né de la suite Examind, spécifiquement conçu pour la conduite de missions. Cette plateforme multi-milieux et multi-champs se positionne comme un outil de choix, aussi bien pour les applications civiles (gestion de crise, etc…) que militaires (supervision tactique), permettant une visualisation avancée et une analyse approfondie des données géospatiales.
Une plateforme au cœur de l’interopérabilitéExamind C2 se distingue par sa capacité à intégrer en quasi-temps réel des flux de données géographiques, hydrographiques, océanographiques et météorologiques, en appliquant des algorithmes avancés de détection d’anomalies et d’analyse comportementale. Grâce à l’utilisation des standards internationaux d’interopérabilité (OGC, ISO, STANAG), la solution assure une diffusion fluide et interopérable de données complexes, indispensables dans un environnement opérationnel.
Des fonctionnalités pour une gestion stratégique et efficaceL’une des forces d’Examind C2 réside dans son module de préparation et de conduite de missions, permettant de planifier, superviser et rejouer les missions. Les utilisateurs bénéficient ainsi d’un terrain de simulation enrichi par des données haute résolution et conforme aux normes de symbologie de l’OTAN. Cette approche facilite la prise en main pour les opérateurs et les aide à visualiser les interactions entre les différents éléments du théâtre d’opération, dans des modes de visualisation allant du 2D au 4D.

La solution s’appuie sur un LakeHouse géospatial pour gérer efficacement de grands volumes de données, garantissant ainsi performance et disponibilité continue. Ce choix, orienté vers des technologies open-source, assure l’indépendance des infrastructures déployées et prévient tout verrouillage technologique. Geomatys a enrichi cette architecture avec des composants comme Apache Iceberg, Apache Kafka et Apache Spark, optimisant la scalabilité et la souveraineté de la solution.
Une vision stratégique grâce à l’analyse prédictiveEn intégrant des algorithmes de détection d’anomalies et d’analyse comportementale, Examind C2 anticipe les mouvements potentiels en fonction des conditions environnementales et des interactions locales. La plateforme peut ainsi détecter des signaux faibles et classer les comportements suspects, offrant un avantage stratégique décisif pour les missions de surveillance.
Geomatys se tient à votre disposition pour toute information complémentaire sur Examind C2 et ses possibilités d’intégration dans vos processus de mission. Contactez-nous au +33 (0)4 84 49 02 26 ou via notre site web www.geomatys.com.
Menu
Linkedin
Twitter
Youtube
The post Examind C2 : pour la préparation et la conduite de missions ! first appeared on Geomatys.
-
sur [Stage 6 mois] - Passage à l’échelle d’un algorithme de fusion de traces GPS issues d’activités sportives et construction d’un réseau de pratiques sportives
Publié: 8 November 2024, 10:05am CET par Lise Benazeth
Contrat : Stage
Lieu : Vallon Pont d’Arc (Ardèche)
-
sur L'histoire par les cartes : la mappa mundi d'Albi
Publié: 8 November 2024, 8:39am CET
La Mappa mundi d'Albi est une carte médiévale du monde (mappa mundi), incluse dans un manuscrit de la seconde moitié du VIIIe siècle conservé dans le fonds ancien de la médiathèque Pierre-Amalric d'Albi. Ce manuscrit provient de la bibliothèque du chapitre de la cathédrale Sainte-Cécile d'Albi. La mappa mundi d'Albi est le plus ancien document conservé d'une représentation globale et non abstraite du monde habité.
Le manuscrit qui porte la carte comprend 77 feuillets. Il est nommé au XVIIIe siècle « Miscellanea » (mot latin signifiant « recueil »). Ce recueil contient 22 documents différents, qui avaient des fonctions pédagogiques. Le manuscrit, un parchemin fabriqué probablement à partir d'une peau de chèvre ou de mouton, est dans un très bon état de conservation.
La carte elle-même mesure 27 cm en hauteur sur 22,5 en largeur. Elle est orientée vers l'est, symbole du siège du paradis terrestre. Elle représente 23 pays sur 3 continents et mentionne plusieurs villes, des îles, des fleuves et des mers. Le monde connu est représenté en forme de fer à cheval, s'ouvrant au niveau du détroit de Gibraltar, et entourant la Méditerranée, avec le Proche Orient en haut, l'Europe à gauche et le nord de l'Afrique à droite.
Mappa mundi d'Albi (source : cartogallica.hypotheses.org)

La carte mentionne 23 pays sur 3 continents :- Europe : Ispania (Espagne), Britania (Bretagne), Gallia (Gaule), Italia (Italie), Gotia (pays des Goths, désignant la Germanie), Tracia (Thrace), Macedonia (Macédoine), Agaia (Achaïe, désignant la Grèce), Barbari (domaine des Barbares).
- Afrique (Afriga) : Mauritania (Maurétanie), Nomedia (Numidie), Libia (Libye), Etiopia (Éthiopie), Egyptus (Égypte).
- Orient : Armenia (Arménie), India (Inde), Scitia (pays des Scythes), Media (pays des Mèdes), Persida (Perse), Judea (Judée), Arabia (Arabie).
La Mappa mundi d'Albi se différencie de manière significative des autres exemples de cartes du monde les plus anciennes ; ces différences accentuent son importance. Très connue des spécialistes, elle l'est cependant peu du grand public. Avec quelques explications, elle peut aujourd'hui reprendre la fonction pédagogique qu'elle a eue au Moyen Age. Elle constitue par ailleurs une unité organique et une cohérence profonde avec la Cité épiscopale d'Albi. C'est ce qui a justifié son inscription en 2015 au registre « Mémoire du monde » de l'Unesco.
Références
Emmanuelle Vagnon et Sandrine Victor (2022), La Mappa Mundi d’Albi. Culture géographique et représentation du monde au haut Moyen Âge, éditions de la Sorbonne, [https:]]
« La Mappa Mundi d’Albi, exemple et exception d’une carte médiévale »
[https:]]
« Mappa mundi. Inscription au registre Mémoire du Monde de l'UNESCO »
[https:]]
« La mappemonde d'Albi, le monde d'hier », un film de 52 mn réalisé par Patrice Desenne (2017) [https:]]
45:00 mn : « Les petits cercles, colorés ou non, représentent les zones de grande densité [...]. C’est là qu’on trouve les hommes. Cet espace-là est civilisé. Inversement chez les Barbares, il n'y a rien, du blanc, du vide. Des espaces qui sont à la fois déserts, incultes et non chrétiens. Cette disctinction immuable entre monde civilisé et monde barbare va tomber avec Orose qui revient d’Orient avec une autre vision du monde sur le plan philosophique et géographique. Après la chute de Rome, tous ces noms de peuples qui figuraient isolément et peu situés sur la carte ont vocation à être intégrés. En montrant les Sarrasins et les Goths à la limite de l’espace chrétien, ils deviennent civilisés ». #BlancsDesCartes
Pour compléter
Virtual Mappa 2.0 est un site d'édition numérique de cartes médiévales en partenariat avec la British Library. Il propose une vingtaine de chefs-d'œuvre cartographiques avec leurs textes transcrits, notamment la carte d'Hereford ainsi que diverses autres mappa mundi.
Macro-typography. L'historien néo-zélandais Jean-Baptiste Piggin étudie l'histoire des diagrammes et des cartes latines. Il revient sur la mappa mundi d'Albi en comparaison des mappa mundi conservées par la Bibliothèque du Vatican.2/2
— Les Savoirs Ambulants (@SavoirsEnBulles) October 29, 2024
Et si 52 minutes, ce n'était pas assez, un très bon livre a été publié sur la Mappa Mundi d'Albi aux éditions de @SorbonneParis1.
Belle découverte ? ! pic.twitter.com/mXyE8YdJx9
Articles connexes
L'histoire par les cartes : 30 cartes qui racontent l'histoire de la cartographie (sélection de l'IGN)
L'histoire par les cartes : la dalle ornée de Saint-Bélec, la plus ancienne carte d'Europe ?
La carte médiévale d'Ebstorf en version interactive et en téléchargement
Numérisée en haute résolution, la carte médiévale de Fra Mauro peut être explorée en détail
L'histoire par les cartes : les routes commerciales au Moyen Age (déjà une route de la soie)
Cartographie ecclésiastique et base de données sur les établissements religieux au Moyen-Age (projet Col&Mon)
L'histoire par les cartes : les collections numérisées de la Bibliothèque Vaticane
L'histoire par les cartes : une série de 14 films documentaires sur les cartes portulans (BNF)
Le nord en haut de la carte : une convention qu'il faut parfois savoir dépasser
Cartes et atlas historiques
-
sur Makina Corpus, sponsor et conférencier au Capitole du Libre 2024
Publié: 7 November 2024, 9:30am CET par Amandine Boivin
Les 16 et 17 novembre à Toulouse, Makina Corpus s’engage aux côtés de la communauté du logiciel libre en sponsorisant le Capitole du Libre. Ne manquez pas la conférence de notre expert Drupal, Simon George.
-
sur Standard GraceTHD : Appel à commentaires jusqu'au 15 novembre 2024
Publié: 6 November 2024, 5:32pm CET
Standard GraceTHD : Appel à commentaires jusqu'au 15 novembre 2024
-
sur Café géo de Paris, 26 novembre 2024 : Qu’est devenue la Yougoslavie ?
Publié: 6 November 2024, 4:42pm CET par r.a.
Mardi 26 novembre 2024, de 19h à 21h.
Café de la Mairie, 51 rue de Bretagne, Paris 3ème
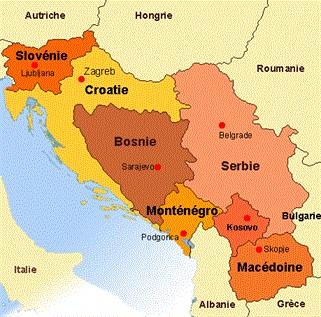
Deux éminents spécialistes des Balkans, Jean-Arnault Dérens, rédacteur en chef du Courrier des Balkans, et Laurent Geslin, journaliste au Monde Diplomatique et à Médiapart, auteurs notamment de l’ouvrage Les Balkans. Carrefour sous influences qui vient de paraître en collection de poche, décriront la situation actuelle des différents Etats nés de l’effondrement de la Yougoslavie. Certains sont devenus membres de l’Union européenne, d’autres rêvent d’en faire partie. Cette partie de l’Europe est aujourd’hui l’objet d’enjeux complexes, en particulier de la part de l’Union européenne, des Etats-Unis, de la Russie, de la Turquie et de la Chine.*
« Les Balkans, carrefour sous influences » : cent questions pour ne plus rien ignorer de cette région. Le Monde, 30 mai 2023.
« Balkans, carrefour sous influences, en 100 questions » de Jean-Arnault Dérens et Laurent Geslin : podcast. France Info, 27 juin 2023
Balkans: un héritage lourd, une paix fragile : entretien avec les auteurs . RFI, 22 juillet 2023
-
sur PostGIS Day – 21 novembre 2024
Publié: 6 November 2024, 8:29am CET par Caroline Chanlon

Le PostGIS Day est un événement clé de la « Geography Awareness Week ». Organisé par Crunchy Data, il permet de mettre en évidence les caractéristiques et les utilisations de la base de données spatiale PostGIS en tant qu’élément de l’écosystème SIG.
Cette journée en ligne est l’occasion d’apprendre comment d’autres utilisent PostGIS, de recueillir des conseils et de partager des bonnes pratiques.
Loïc Bartoletti animera une présentation sur SFCGAL et PostGIS : Intégration, cas d’utilisation et avenir.
Plus d’infos : [https:]]
-
sur Une rentrée riche autour de la donnée et des rencontres pour Makina Corpus Territoires
Publié: 5 November 2024, 3:07pm CET par Olivia Duval
Chaque rentrée apporte son lot d’opportunités pour faire avancer les projets autour de la données au service des territoires. Le calendrier de Makina Corpus en la matière a été particulièrement dense en événements.
-
sur UCLouvain : gestion des inscriptions à l'université
Publié: 5 November 2024, 9:16am CET par Sylvain Boureliou, Julien Cougnaud, Yann Fouillat
L’Université catholique de Louvain est un acteur clé de l’enseignement et de la recherche belge.
-
sur La carte, objet éminemment politique. La France reconnaît la souveraineté du Maroc sur le Sahara occidental
Publié: 1 November 2024, 5:42am CET
Le site officiel du Quai d’Orsay a publié le 28 septembre 2024 une nouvelle carte du Maroc intégrant le Sahara occidental. Par là même, la France institutionnalise l’usage d'une nouvelle carte officielle du Maroc : une manière de prendre position dans le débat autour du rattachement controversé du Sahara occidental à ce pays.
Nouvelle carte officielle du Maroc sur le site du Ministère français des Affaires étrangères (source : diplomatie.gouv.fr/)La publication par le Ministère français des Affaires étrangères de la carte officielle du Maroc intégrant le Sahara occidental s'inscrit dans le cadre de la réaffirmation par le Président français de la souveraineté du Maroc sur ce territoire. En observant le document, on s'aperçoit que la carte a été refaite dans l'urgence. "SAHARA OCCIDENTAL" reste écrit en gras et en caractères majuscules (comme le nom d'un pays). Un astérisque a été simplement ajouté à côté du nom avec une note au bas de la carte : « Pour la France, le présent et l’avenir du Sahara occidental s’inscrivent dans le cadre de la souveraineté marocaine. Le processus d’autonomie proposé par le Maroc en 2007 constitue la base pour aboutir à une solution juridique juste, durable et négociée conformément aux résolutions du Conseil de sécurité de l’ONU ».
Comparaison par rapport à la carte précédente qui faisait apparaître le Sahara occidental en hachure et séparé par une ligne continue du Maroc
D'après le code source de la page, la nouvelle carte a été conçue le 28 octobre 2024 de manière à être déposée à la suite du discours officiel prononcé par le Président français le 29 octobre devant les membres des deux Chambres du parlement marocain. La ligne qui séparait le Sahara occidental du Maroc a d'abord été remplacée par des pointillés, avant d'être complètement retirée pour former un seul pays. Dans la présentation qui accompagne la carte, la superficie totale du Maroc est toujours la même 446 550 km2 (ce serait en réalité 712 000 km2 si l'on incluait le Sahara occidental). L'indication de la superficie a été par la suite enlevée de la page, laissant le flou autour de cette information.
Présentation du Maroc sur le site Ministère des affaires étrangères français au 30 octobre 2024
(source : diplomatie.gouv.fr/)Il convient de rappeler que le Sahara occidental est le théâtre d’un conflit qui dure depuis des décennies. Le Front Polisario, soutenu par l’Algérie, revendique ce grand territoire riche en ressources (hydrocarbures, richesses halieutiques). Ce conflit est la source de nombreuses tensions entre l’Algérie et le Maroc. La France a d’abord tenté de se rapprocher de l’Algérie en reconnaissant les crimes français, et en ouvrant les registres, mais sans retour d’Alger. C’est en partie l’échec du rapprochement avec Alger qui conduit à cette réconciliation franco-marocaine. La visite officielle du Président Macron au Maroc en octobre 2024 est l'occasion d'une réconciliation, notamment après l’affaire Pegasus qui a créé un climat de tensions. Cette visite d’État a pour objectif de renforcer les liens économiques et sociaux entre la France et le Maroc. En plus des partenariats économiques, le sujet de l’immigration est aussi au cœur des discussions. Dans ce contexte, la carte est présentée comme une manière de « prendre en compte les évolutions diplomatiques entre les deux pays ». Progressivement, il s'agit pour la France d'aller « vers la reconnaissance internationale pleine et entière de la souveraineté du Maroc sur le Sahara ». « Cette position n'est hostile à personne », a assuré le président français dans une réponse aux critiques de l'Algérie, qui soutient les indépendantistes sahraouis du Front Polisario dans ce territoire disputé.
Dans une lettre adressée au roi Mohammed VI en juillet 2024 à l'occasion de l'anniversaire des 25 ans de son règne, Emmanuel Macron avait déjà fait un pas vers la reconnaissance de la "marocanité" de ce territoire, cheval de bataille diplomatique du Maroc depuis de nombreuses années. Sans reconnaître expressément la "marocanité" du Sahara, le président français, y affirmait que « pour la France, l'autonomie sous souveraineté marocaine est le cadre dans lequel cette question doit être résolue. Notre soutien au plan d'autonomie proposé par le Maroc en 2007 est clair et constant. Il constitue désormais la seule base pour aboutir à une solution politique juste, durable et négociée conformément aux résolutions du Conseil de sécurité des Nations unies ».
La diplomatie marocaine a tout mis en œuvre pour mettre à l’agenda une solution politique qui entérine l’état de fait actuel. En 1963, le Maroc a fait pression sur l'ONU pour qu'il soit déclaré territoire non-autonome. Depuis 1991 (départ des Espagnols), le territoire est déclaré sans autorité administrante. En 2006, il est rappelé qu'aucun État membre de l'ONU ne reconnaît la souveraineté du Maroc sur le Sahara occidental. L'application Google Maps indique toujours la frontière avec des pointillés. Si on compare les cartes officielles de différents pays, on peut percevoir différents degrés de soutien à la "marocanité" du Sahara Occidental. Depuis 2020, les Etats-Unis reconnaissent par exemple la souveraineté du Maroc sur ce territoire (voir la carte officielle du Maroc sur le site de la CIA). Récemment, Benyamin Nétanyahou a présenté sur LCI une carte du Maroc sans le Sahara occidental, provoquant un tollé dans le pays. La République sahraouie apparaît aujourd'hui de plus en plus isolée au niveau international : seule une trentaine de pays la reconnaissent en 2020, contre 79 en 1990. D'une certaine manière, le Maroc est en train de gagner la bataille des cartes. Sur le site officiel de l'Agence Nationale de la Conservation Foncière, du Cadastre et de la Cartographie (ANCFCC), les cartes du Maroc incluent le Sahara occidental. A noter que la précision des cartes topographiques y reste moins grande au sud et à l'intérieur des terres que sur la côte (1:100 000 au lieu de 1:25 000).
Cartes topographiques du Maroc (source : ANCFCC)
Sources utilisées
- « Emmanuel Macron au Maroc pour une visite de réconciliation » (Le Monde, 28 octobre 2024)
- « La France institutionnalise l’usage de la carte officielle du Maroc intégrant le Sahara occidental » (L'Observateur, 2024)
- « La France a-t-elle reconnu la "marocanité" du Sahara occidental ? » (France24, 30 juillet 2024)
- « Quels États soutiennent la souveraineté du Maroc sur le Sahara occidental ? » (Statista, 31 juillet 2024)
- « Pourquoi y a-t-il une ligne en pointillé au milieu du Maroc ? Comprendre en trois minutes » (Le Monde, 12 juin 2023)
- « Tollé au Maroc après que Benyamin Nétanyahou a présenté sur LCI une carte du royaume sans le Sahara occidental » (Le Monde, 31 mai 2024)
- « Sahara occidental : la Cour européenne de justice, le droit international et la politique » (Rtbf, 26 octobre 2024)
- « Le Maroc intègre les eaux du Sahara occidental à son espace maritime » (Le Monde, 23 janvier 2020)
- « Sahara occidental : 45 ans de conflits et de négociations "au point mort" » (France24, 13 novembre 2020)
- « Sahara : Conflit ensablé ? » (Le Dessous des cartes, juin 2018)
- « Sahara : le Maroc est-il en train de gagner la bataille des cartes ? » (HuffPost Maroc, 13 novembre 2020)
La carte, objet éminemment politique : la "bataille des cartes" entre la Turquie et la Grèce
La carte, objet éminemment politique : la Chine au coeur de la "guerre des cartes"
La carte, objet éminemment politique : Nétanyahou menace d'annexer un tiers de la Cisjordanie s'il est réélu
La carte, objet éminemment politique : la carte officielle de l'Arabie saoudite
La carte, objet éminemment politique. L'Argentine et sa carte officielle bi-continentale
La carte, objet éminemment politique. Maduro modifie la carte officielle du Venezuela pour y inclure l’Essequibo
La carte, objet éminemment politique. Le Népal va imprimer sa nouvelle carte officielle sur un billet de banque

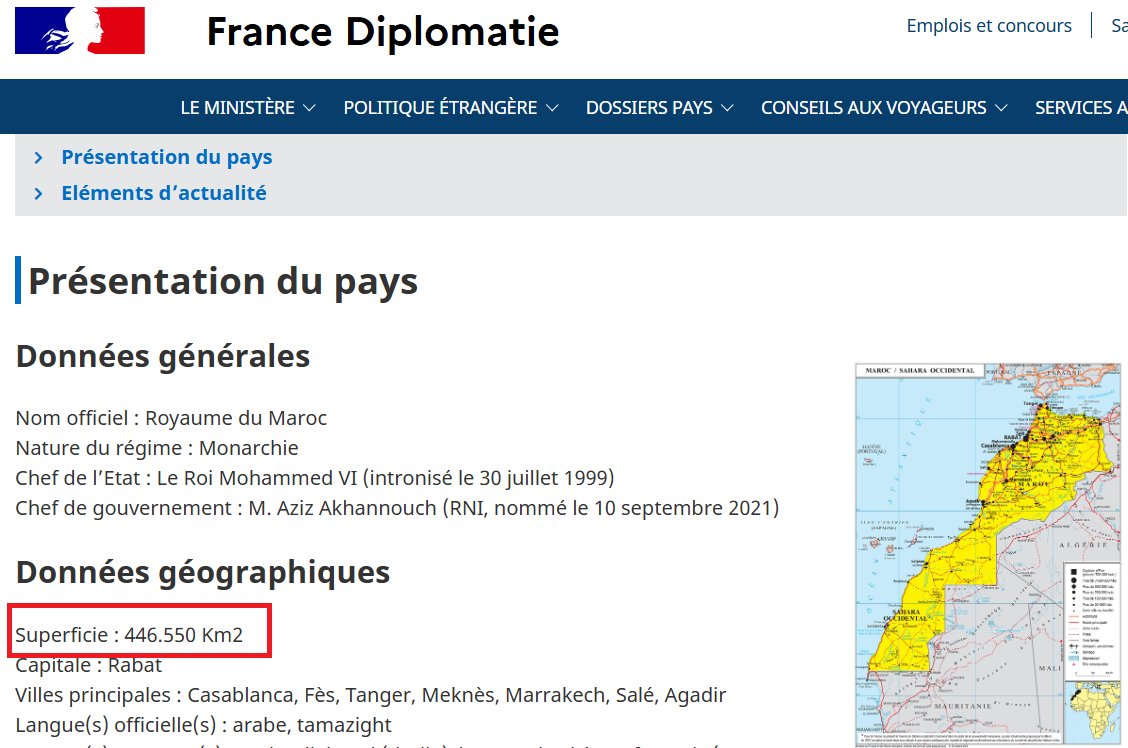
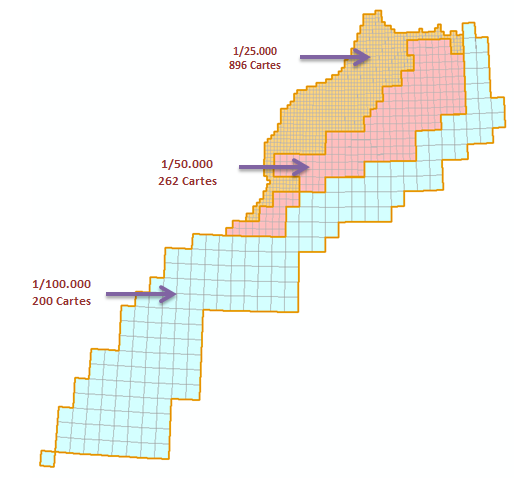
-
sur [Story] Oslandia x QWC : épisode 5 / 8
Publié: 31 October 2024, 5:42am CET par Caroline Chanlon

Nous avons récemment détaillé les ajouts fonctionnels génériques qui ont été intégrés directement dans le cœur de QWC.
Mais parfois, certains développements ne sont pas publiés !
En effet, en plus de ces ajouts aux dépôts de QWC, nous avons également développé certaines fonctionnalités spécifiques pour nos clients, qui n’ont pas forcément leur place dans ces dépôts, étant donné qu’elles ne peuvent être applicables à n’importe quel utilisateur de QWC.
De façon générale, lorsque nous analysons une demande client, nous distinguons parmi les fonctionnalités à développer, celles qui sont génériques et celles qui sont spécifiques. Oslandia veille à contribuer “upstream” toutes les fonctionnalités génériques, afin qu’elles participent à l’enrichissement du bien commun, et qu’elles favorisent la dynamique opensource de mutualisation des projets.
À l’inverse, les fonctionnalités spécifiques sont gardées sur des dépôts privés pour le client, même si elles sont opensource : il n’y a pas d’intérêt à les publier, et elles ont souvent une adhérence à un SI particulier, ou une structure de données particulière.
C’est ainsi que nous avons développé un service de parcours de réseau d’eau potable pour détecter des fuites d’eau ou des incidents, un service de recherche utilisant PostgreSQL Full Text Search, ou une recherche sur des données cadastrales. Ces fonctionnalités sont intégrées dans les applications pour nos clients, et bénéficient des apports précédemment réalisés dans le cœur de QWC.
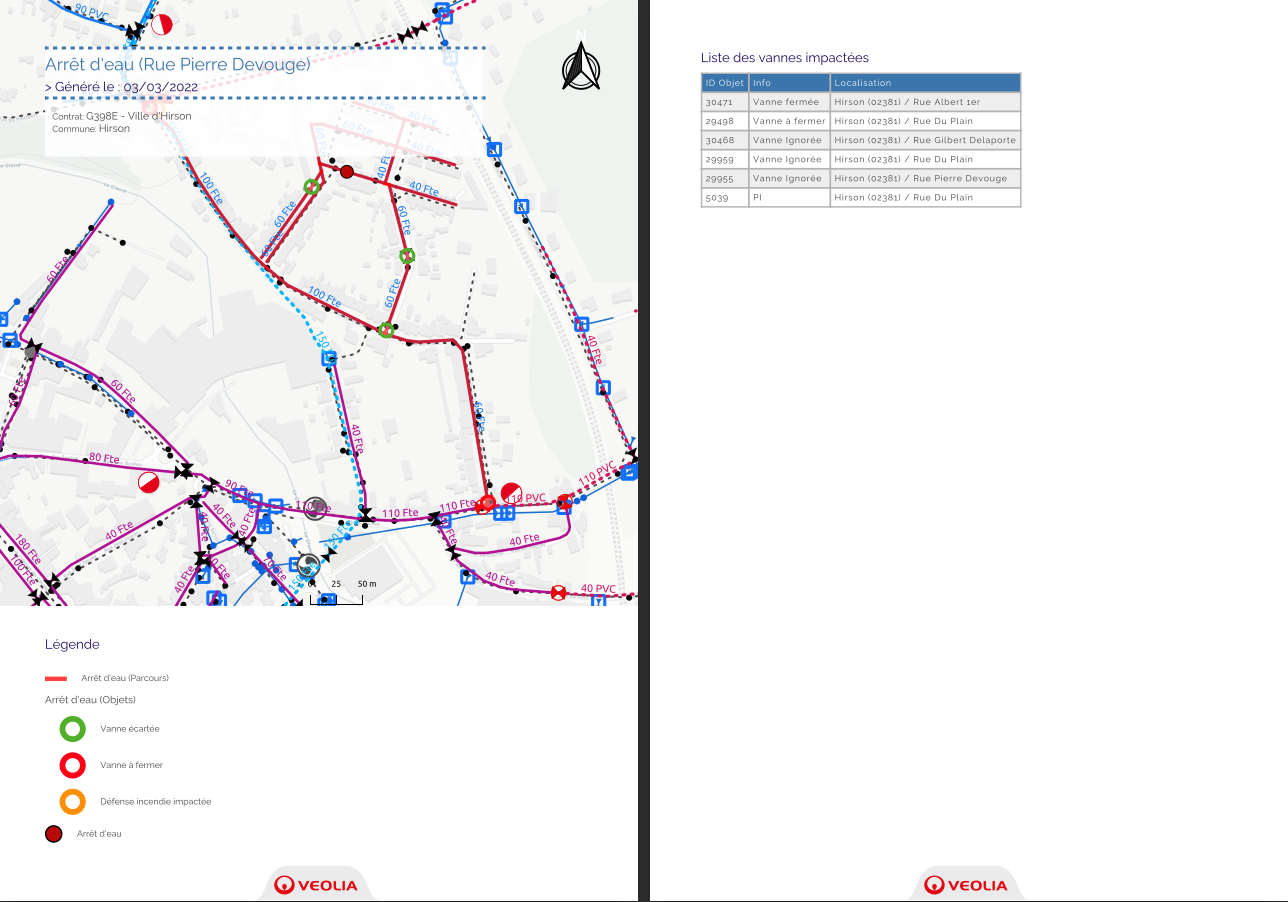
Vous pouvez nous contacter pour toute demande spécifique de développement dans QWC, autant que pour du développement cœur !
-
sur Récolt'Ô : lauréat des Data Challenges Adapt'Action et participant à l'Open Booster
Publié: 30 October 2024, 9:21am CET par Amandine Boivin
Développée par Makina Corpus Territoires, la solution pour la valorisation et l’optimisation de l’eau de pluie Récolt’Ô a récemment été désignée lauréate des Data Challenges Adapt’Action.
-
sur Capitole du Libre – Toulouse
Publié: 30 October 2024, 6:45am CET par Caroline Chanlon

L’édition 2024 du Capitole du Libre se tiendra les 16 et 17 novembre à l’INP-N7, en centre ville de Toulouse. Ce week-end, dédié au logiciel libre à travers environ 100 conférences et 25 ateliers pour les expert?e?s et le grand public, a accueilli 1500 participant?e?s en 2023 !
Julien Cabièces animera la présentation « Découvrez QGIS, un logiciel libre pour la manipulation des données géospatiales. » RDV le 17 novembre à 15:30
Plus d’infos et inscription [gratuite] : [https:]]
-
sur Atlas cartographique du grand âge
Publié: 29 October 2024, 6:01pm CET
Atlas cartographique du grand âge. Les dynamiques territoriales du vieillissement (Intercommunalités de France, octobre 2024).Le vieillissement de la population est un phénomène mondial. En France, le nombre de personnes âgées de 65 ans et plus a considérablement augmenté, avec une accélération significative depuis 2011 et l’entrée des baby-boomers dans cette tranche d’âge : en 2050, il est estimé que la part des 65 ans et plus sera de 28% en France (contre 36% dans les pays du Sud de l’Europe, et 38% au Japon et en Corée du Sud). Pour faire face au vieillissement, les pays de l’OCDE, dont la France, ont mis en oeuvre diverses politiques ciblées, l’une d’elles étant l’augmentation de l’offre d’emploi pour les 50-65 ans.
Ces tendances démographiques impactent considérablement les dépenses publiques et privées en matière de retraites, de santé et d’éducation, ainsi que la croissance économique et le bien-être en général. Le taux de dépendance des personnes âgées (plus de 65 ans) est passé de 27% en 2000 à 39% en 2024 (contre 42% en Allemagne, 42% en Italie ou 32% aux Etats-Unis) et devrait atteindre 50% en 2050 selon l’OCDE. Véritable lame de fond, le vieillissement se déploie avec une intensité variable et soulève des problématiques complexes, multidimensionnelles et spécifiques d’un territoire à l’autre, appelant la mise en oeuvre de politiques d’accompagnement – de transition démographique – territorialisées, à l’échelle locale. Toutefois, s’il est souvent perçu comme un coût, il peut également être un moteur de développement économique et territorial, notamment à travers la « silver economy ».

Cet atlas est le fruit d’un partenariat entre le Groupe La Poste, Intercommunalités de France et l’Association des directeurs généraux des communautés de France (ADGCF). Constituant le premier volet d’une analyse approfondie sur le grand âge, ce document propose des éléments de cadrage essentiels pour comprendre pleinement les enjeux de la transition démographique à l’échelle nationale, tout en permettant de cibler les spécificités propres à chaque intercommunalité.
Deux approches ont systématiquement été déclinées pour produire les analyses :
- Une approche synthétique produite à l’échelle des intercommunalités regroupées par strates démographiques qui permet à la fois de disposer de grandes tendances de fond et de comparer la dynamique et situation des seniors et/ou des retraités au regard de l’ensemble de la population française ;
- Une approche cartographique réalisée à l’échelle des intercommunalités françaises pour disposer d’une géographie fine du vieillissement et de ses effets, notamment en termes de disparités socioéconomiques dans les territoires.
Télécharger l'Atlas en version pdf.
Un second volet (dont la parution est prévue début 2025) abordera le grand âge à travers des thématiques tels que la santé, l’accessibilité, la vie sociale et les aidants. Cette analyse dressera un état des lieux des pratiques locales et des modalités de mise en œuvre des politiques du « grand âge » à l’échelle des bassins de vie, en s’appuyant sur des retours d’expérience.
Articles connexes
Le vieillissement de la population européenne et ses conséquences
Cartes sur la jeunesse, la formation et l'emploi au sein de l'Union européenne
Baisse de la part des jeunes dans la population de l’Union européenne d’ici 2050
Datavisualisation : une population mondiale à 8 milliards d’habitants (Visual Capitalist)
Cartes et données sur la population mondiale (Population & Sociétés, 2024)
Datavisualisation : une population mondiale à 8 milliards d’habitants (Visual Capitalist)
Données carroyées de population à l'échelle mondiale sur le site WorldPop
Les villes face au changement climatique et à la croissance démographique - Une approche synthétique produite à l’échelle des intercommunalités regroupées par strates démographiques qui permet à la fois de disposer de grandes tendances de fond et de comparer la dynamique et situation des seniors et/ou des retraités au regard de l’ensemble de la population française ;

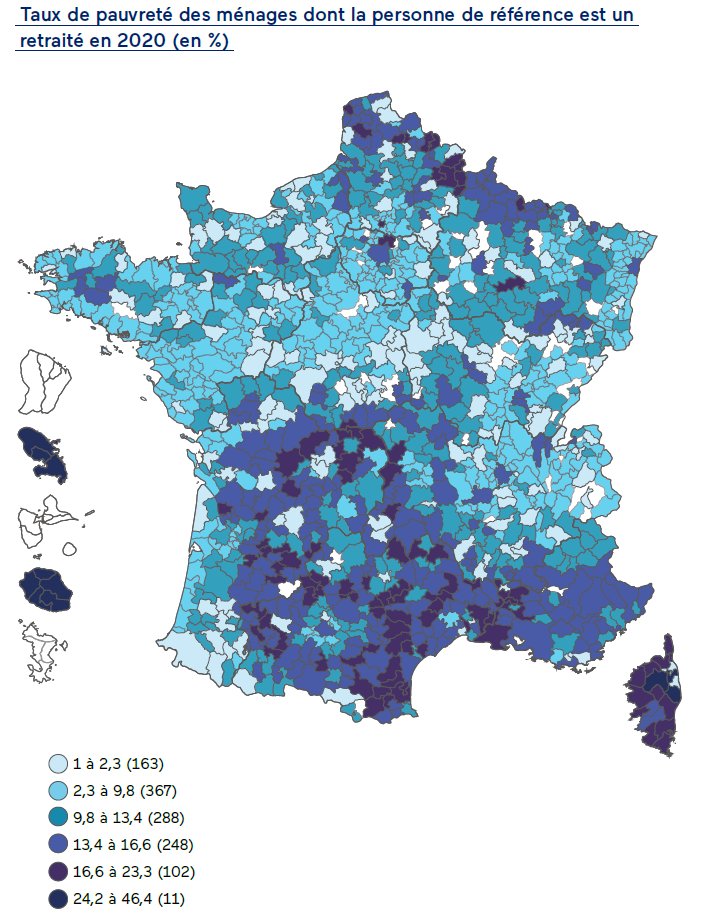
{kind=link}
{kind=link}
{kind=link}
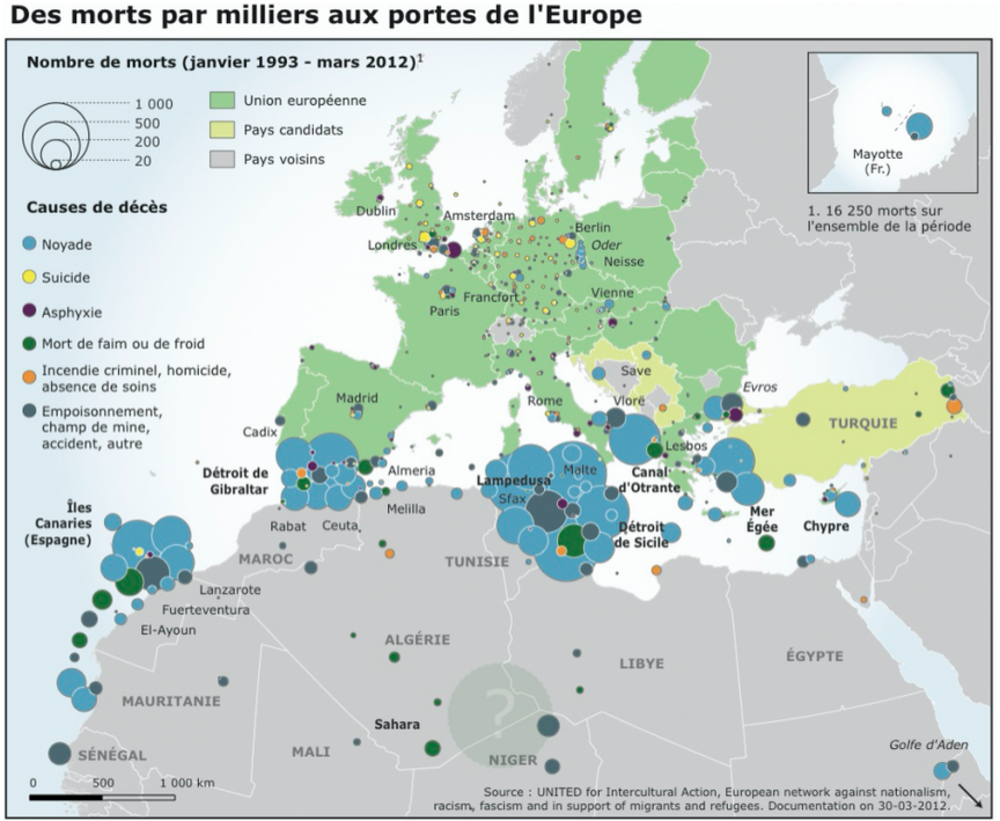{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
sur Le Festival International de Géographie de Saint-Dié-des-Vosges, 4-5-6 octobre 2024
Publié: 29 October 2024, 11:29am CET par r.a.

Affiche officielle du FIG 2024 (adfig@ville-saintdie.fr)
Pour sa 35ème édition, le FIG, fondé par Christian Pierret, convie toujours les géographes et leurs amis à Saint-Dié pour le premier week-end du mois d’octobre. La thématique retenue cette année s’intitule sobrement « Terre » et le territoire à l’honneur est une chaîne de montagne, les Alpes.
Le cartel de présentation (ci-dessus) retient bien tous les enjeux : entre agriculteurs et éleveurs, promoteurs urbains ou gestionnaires d’entreprises multinationales. De façon un brin ironique le Monsieur Gestionnaire est en costume-cravate-chapeau et il surplombe tous les autres acteurs. Quelle est cette terre que l’on foule, que l’on creuse, que l’on pétrit ? Nourricière, protectrice, accueillante (ou pas), elle offre au vivant (Homme et Animal), la vie tout simplement.
Les intervenants sont géographes, enseignants, écrivains, dessinateurs. Ceux qui se rendent dans les Vosges, année après année, le font pour approfondir leurs connaissances, leur réflexion mais aussi se retrouver dans un même hôtel ou partager un repas entre deux conférences. Ils viennent de toute la France, mais aussi de la Belgique ou d’autres pays voisins. Les enseignants sont autorisés à quitter leur établissement pour suivre une programmation élaborée par l’Inspection générale. Les autres participants sont souvent membres d’associations comme Les Cafés géographiques, ou la Société de Géographie. Enfin, les habitants de la Région Grand Est souhaitent participer à la mise en valeur de leur région et dans ce cas on croise des enseignants accompagnés de leurs élèves.
Le Festival propose des conférences, des tables rondes, des débats. Mais il y a aussi un Salon de la gastronomie, un Salon du livre et un Espace Géo-Numérique qui offre une vue d’ensemble sur les méthodes et outils utilisés par les géographes pour analyser un territoire.
Toutes les manifestations sont en accès libre et gratuites, mais il faut se précipiter pour avoir une place, accepter de faire la queue et le soleil n’est pas garanti ! Mais cela ne réduit pas les ardeurs : alors prêts, partez ! Et, par avance, acceptez ma sélection toute subjective des comptes rendus proposés.Terres d’ici ou d’ailleurs. La thématique retenue par le FIG sera déclinée sous toutes ses formes puisque la terre est le terrain de jeu des géographes. La terre c’est un sol, plus ou moins fertile, reposant sur un sous-sol, plus ou moins riche en minerais. Elle est à présent très largement appropriée ou convoitée. Elle est donc à l’origine de l’essentiel des conflits violents que nous connaissons.
Les Cafés géographiques, sous la direction de l’ADFIG (association pour le développement du FIG) et de ses vice-présidents, Gilles Fumey et Catherine Viry, ont organisé plusieurs rencontres dont voici quelques titres :
Protéger les terres. Les géographes s’engagent. C’est le titre d’un ouvrage publié aux éditions du CNRS, sous la direction d’Adrien Baysse-Laine et Florence Nussbaum, codirecteurs scientifiques du FIG 2024.
Comment étudier la terre en géographie ? Nous écouterons Denis Mercier, géomorphologue, auteur d’un Atlas des glaciers paru aux éditions Autrement.
Où commencent et où finissent les Alpes ? Ici se rejoignent les deux thématiques du FIG. C’est Xavier Bernier, auteur d’un Atlas des montagnes paru aux éditions Autrement, qui vient nous éclairer.
Où en est la révolution verte en Inde ? Frédéric Landy qui a publié un ouvrage intitulé, L’Inde, du développement à l’émergence, éditions Armand Colin, essaie de faire un bilan d’une politique qui devait mettre le sous-continent à l’abri des famines.
Cohabitons nous propose Michel Lussault, dans un livre paru aux éditions du Seuil. Il intime : Cohabitons pour une urbanité planétaire ! Il s’inquiète d’une crise d’habitabilité de la planète soumise à des prédateurs. Il propose un « habiter autrement ».Hmong nous est présenté par Vicky Lyfoung, autrice de BD.
Cette fois nous mettons le cap sur l’Asie, avec Vicky, jeune femme qui nous raconte, dans un amphithéâtre de Saint-Dié, avec sensibilité et humour la vie de sa famille.
Son peuple vient d’Indochine et plus précisément du Laos. Peuple sans écriture et donc perçu comme peuple sans histoire, les Hmongs (ou Mongs) n’ont d’autre religion que l’animisme. En outre ils sont divisés en 18 clans, le plus puissant étant celui des Mongs blancs. La place des femmes dans la société n’est autre que celle de faire des enfants. Vicky est la plus jeune d’une famille de 8 enfants. Ne renonçant pas à leur âme, ils furent encore et encore massacrés, perdant à chaque fois des terres laborieusement mises en valeur.
Considérés comme rebelles au Laos, confinés par procuration du mauvais côté de l’histoire car ils avaient choisi de combattre aux côtés des Français puis des Américains. Ils ont fui aux Etats-Unis (300 000) et en France (80 000). Une partie d’entre eux habite à présent en Guyane. L’Etat français leur a donné des terres sur lesquelles ils cultivent des fruits et des légumes. Hmong signifie « être libre ».
Couverture de l’album Hmong (Delcourt, 2023)
Conférences et Rencontres « terres rurales / terres urbaines »
De quoi le ZAN est-il le nom ? C’est quoi le ZAN ? C’est l’objectif Zéro Artificialisation Nette, fixé à 2050 par la loi Climat et résilience, votée en 2021. C’est la mise en cause du modèle dominant de développement dans les territoires ruraux ou dans les villes où prolifère l’habitat pavillonnaire. On pourrait dire « là où le ZAN passe, la bétonisation trépasse…. ».
Certes, la responsabilité de l’aménagement revient aux collectivités locales mais la question se pose de savoir si elles ont des marges de manœuvre et des moyens à la hauteur de cet objectif.
Plusieurs conférences ont été organisées sur le sujet avec comme intervenants : Eric Charmes, Rémi Delattre, Morgane Brissaud, Michel Fournier, Stella Gass.Quelle agriculture en France en 2050 ? Autour de cette table ronde on écoute Monique Poulot, Philippe Mauguin, Eric Fottorino, Hélène Béchet et Thibault Sardier. Dans l’actualité de l’année écoulée, les agriculteurs ont souvent manifesté leur défiance vis-à-vis des politiques mises en œuvre. On se rappelle la mobilisation contre les mégabassines….
Atterrissements et sols artificialisés des villes dans l’anthropocène. Eric Verdeil s’interroge sur le devenir des périphéries urbaines à partir des cas de Paris, Dubaï, Tokyo, Beyrouth et New York : ici et là, l’artificialisation combine des excavations ou des accumulations toujours plus massives de déblais et de déchets.
Transitions en tension : les valeurs de la terre face à l’exploitation du lithium dans le Massif Central. Marie Forget et Camille Girault étudient à Echassières, commune rurale de l’Allier, la perspective de la mise en valeur d’une mine de lithium qui résulte de la volonté du Green deal européen de relocaliser les ressources minières en Europe pour réaliser la transition énergétique.
L’usage des terres, source de conflits entre villages des Vosges (18ème et 19ème siècles). Jean-Claude Fombaron, historien, a étudié les heurts et procès entre villages et seigneuries ou entre villageois dans le bassin de la Meurthe et aussi les conflits parfois sanglants. Cette étude régionale pourrait s’appliquer à la quasi-totalité de la planète !
Colombie : quand la monoculture maintient son emprise, entre marchés politiques et violences. Benjamin Lévy analyse le maintien de la monoculture au regard de la reproduction du régime local de contrôle de la terre et de la violence politique étatique.
Rapports conflictuels à des lieux sacrés
Rencontre autour de « Nos lieux communs ». Il s’agit d’un ouvrage paru aux éditions Fayard, qui explore le monde par des lieux, des plus banals aux plus exceptionnels. Les récits sont de Laurent Carroué, Fabrice Argounes et Martine Drozdz.
Les rapports à la terre des migrantes ukrainiennes en Pologne. Camille Robert-Bœuf et Cristina Del Baggio, s’intéressent à l’ancrage territorial des femmes ukrainiennes en Pologne.
Les réfugiés recensés en Pologne sont à 65 % des femmes, âgées de à 52 % de 18 à 59 ans et qui pour 20 % s’installent dans des communes rurales. Les hommes ne peuvent pas partir, ils doivent aller au front.
Avant la guerre, il s’agissait surtout de migrants saisonniers. A présent il s’agit de réfugiés auxquels les autorités polonaises essayent, tant bien que mal de procurer un toit et des repas et d’assurer la scolarisation des enfants.
Jérusalem, une terre disputée
Le plan de partage de la Palestine de 1947 prévoyait « deux Etats indépendants arabe et juif » et aussi « un régime international » pour la ville de Jérusalem. Bernard Philippe, ancien fonctionnaire européen nous explique la non-résolution de ces pactes.
Lieux sacrés et terres saintes : accessibles au commun des mortels ?

Jean-Robert Pitte et Eduardo Castillo (photo de l’auteur)
Jean-Robert Pitte, président de la Société de Géographie, installé dans la cathédrale, lieu des plus symboliques pour son intervention, nous parle d’une humanité toujours habitée par la spiritualité mais où beaucoup d’endroits sont réservés aux croyants.
Il prend d’abord l’exemple du Japon, qu’il connaît très bien : à Tokyo (30 millions d’habitants) les 300 ha du Palais impérial sont interdits au commun des mortels. Le Palais a été bâti sur le modèle chinois de la Cité impériale. Ni avions, ni drones ne peuvent le survoler. Seuls quelques chefs d’Etat y sont conviés.
Il prend ensuite l’exemple de la forêt de la Sainte-Baume, en France. Située au nord de Marseille, la forêt fut bois sacré celtique puis romain. Marie-Madeleine y vint se retirer dans une grotte en étant nourrie par les anges.
A Jérusalem, l’esplanade des mosquées est interdite aux Juifs, elle fut pourtant récemment foulée par un ministre d’Israël.
Il y a des lieux interdits aux hommes, dans les monastères carmélites et des lieux interdits aux femmes chez les Chartreux. Les harems n’ont pas disparu…
La liste des lieux interdits à une partie de l’humanité sont infinis : à Uluru (Australie) les Aborigènes interdisent la montée sur le rocher aux non Aborigènes ; à Bali il y a 22 montagnes sacrées, etc.… Que de mystères encore en ce début de XXIème siècleCarte blanche à Christian Grataloup pour son Atlas historique du ciel
Christian Grataloup, fidèle du FIG et Pierre Léna viennent de publier un Atlas historique du ciel (Les Arènes). Le géographe et l’astrophysicien se sont associés pour nous faire comprendre que l’intérêt pour l’observation du ciel n’est pas récent. Le ciel de l’Eurasie est exploré à l’œil nu dès 3000 ans avant notre ère, puis cartographié. De Galilée (1610) à Gagarine en 1995, les hommes se sont passionnés pour le ciel et l’espace.
A présent notre ciel est encombré d’objets, de messages les plus divers. Et si nous devions renoncer à cela ? A qui es-tu, la terre ? A qui es-tu, l’espace ?
Christian Grataloup est aussi intervenu sur Le pouvoir des Cartes lors d’une rencontre animée par Etienne Augris.Pour rester d’humeur légère, une dernière proposition : Bienvenue en Géozarbie avec Olivier Marchon. La série Bienvenue en Géozarbie, diffusée sur Arte.tv raconte les histoires baroques de petits morceaux de terre aux statuts étranges : enclaves, territoires prêtés, zones disputées, micro-Etats, îles fantasmées…
Le FIG de 2024 nous aura ouvert ou entrouvert bien des portes. L’an prochain il nous amènera en Indonésie et nous proposera comme thématique de réfléchir à la notion de Pouvoir. Nous avons hâte de revenir.
N’oublions pas de signaler :
– La revue La Géographie n°1594, Automne 2024, Terre des Hommes
– L’Atlas publié par l’IGN : Cartographier l’anthropocène à l’ère de l’Intelligence Artificielle
– Le Salon de la gastronomie qui cette année à Saint-Dié faisait la part belle aux tartes aux myrtilles, aux bières et aux fromages locaux.
– Le Salon du Livre, qui sous un grand chapiteau propose un choix important des œuvres publiées par les intervenants, souvent présents, entre deux conférences et soucieux d’échanger avec leurs lecteurs.Maryse Verfaillie, octobre 2024
-
sur QGIS: ajouter automatiquement l’attribut d’une autre couche
Publié: 29 October 2024, 10:56am CET par Florian Delahaye
Vous dessinez un point sur une couche SIG et vous voulez connaître la commune associée? Dans QGIS, il est possible d’ajouter automatiquement l’attribut d’une autre couche dans une donnée cible. Dans ce tutoriel SIG, on ne traite pas de jointure par champ attributaire ni de jointure spatiale. Il s’agit d’utiliser… Continuer à lire →
L’article QGIS: ajouter automatiquement l’attribut d’une autre couche est apparu en premier sur GEOMATICK.
-
sur Bonjour tout le monde !
Publié: 28 October 2024, 11:25am CET par admin_veillecarto2024
Bienvenue sur WordPress. Ceci est votre premier article. Modifiez-le ou supprimez-le, puis commencez à écrire !
L’article Bonjour tout le monde ! est apparu en premier sur Veillecarto2-0.fr.
-
sur Biophysical parameter retrieval from Sentinel-2 images using physics-driven deep learning for PROSAIL inversion
Publié: 27 October 2024, 9:54am CET par zerahy
The results presented here are based on published work: Y. Zérah, S. Valero, and J. Inglada. « Physics-constrained deep learning for biophysical parameter retrieval from sentinel-2 images: Inversion of the prosail model« , in Remote Sensing of Environment, doi: 10.1016/j.rse.2024.114309. This work is part of the PhD of Yoël Zérah, supervised by Jordi Inglada and Silvia Valero. […]
-
sur Data visualisation sur la responsabilité et la vulnérabilité par rapport au changement climatique
Publié: 26 October 2024, 8:55am CEST
Sacha Schlumpf, Mapping Climate Change [Cartographier le changement climatique].
Notre société est confrontée à une crise climatique immense. Tous les pays ne sont pas également responsables et, surtout, tous ne subiront pas les mêmes conséquences. En utilisant le procédé de l'« imitation cartographique », Sacha Schlumpf a créé une data visualisation représentant les pays du monde. Leurs positions sont déterminées non par leur localisation, mais par leur responsabilité et leur vulnérabilité par rapport au changement climatique. Comme le montre le code couleur, les pays riches (en foncé) ont tendance à polluer davantage et sont moins vulnérables que les pays pauvres (en clair).
Responsabilité et vunérabilité par rapport au changement climatique (crédit : Sacha Schlumpf)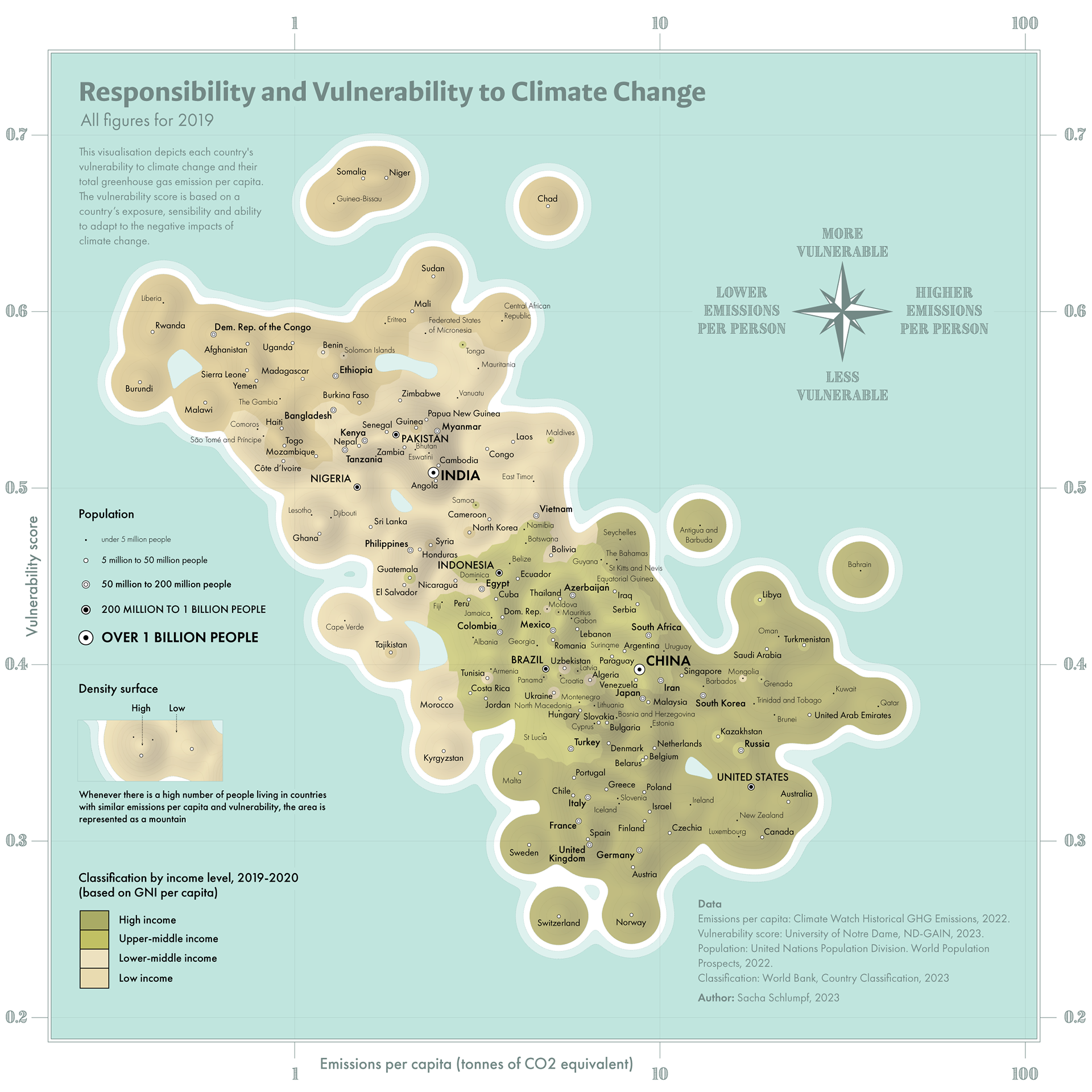
Contrairement à une carte classique, les pays ne sont pas placés en fonction de leur localisation réelle, mais en fonction de deux variables : les émissions de gaz à effet de serre par habitant (axe horizontal) et la vulnérabilité au changement climatique (axe vertical). Les couleurs représentent le revenu par habitant. Les pays plus riches ont tendance à contribuer beaucoup plus au changement climatique que les pays les plus pauvres, tout en étant moins vulnérables à ses conséquences. Cette « carte » a été réalisée dans le cadre d'une thèse à l'Université de technologie de Vienne, en collaboration avec HarperCollins Publishers, qui publie une version modifiée de cette visualisation dans la 16e édition du Comprehensive Times Atlas of the World.Le procédé de l'« imitation de carte » (map imitation) a été étudié par Sacha Schlumpf et ses collègues. Voir cet article :
Schlumpf, S., Gartner, G., Engelhardt, Y., and Lennox, J. (2024). Space as a Metaphor – Design Guidelines and Evaluation of Map Imitation [L'espace comme métaphore – Lignes directrices pour la conception et l'évaluation de l'imitation de cartes], Abstr. Int. Cartogr. Assoc., 7, 146.
L'imitation de carte est un type de visualisation de données où les données sont affichées sur une visualisation ressemblant à une carte. Bien que des imitations de cartes existent depuis le XVIIe siècle, les exemples d'imitations de cartes complètes sont rares. L'inspiration de cette recherche est l'atlas d'Hermann et Leuthold (2003). Aucune imitation de carte complète n'a jamais été testée dans une étude utilisateur, bien qu'il existe des recherches sur des couches individuelles d'imitations de cartes (Hogräfer et al., 2020). Par imitation complète, on entend une visualisation avec plusieurs couches et éléments visuels d'une carte conventionnelle. Par conséquent, cette recherche contribue au domaine en fournissant une procédure pour la production d'une imitation de carte complète, ainsi qu'en testant la perception et la compréhension de l'utilisateur. En raison de l'absence d'un terme commun, une nouvelle définition de l'imitation de carte est donnée. Dans cette recherche, l'imitation de carte est définie comme une visualisation de type carte utilisant des données non géospatiales, créée à partir de données individuelles sur des coordonnées non géospatiales, mais conçue pour ressembler à une carte à l'aide d'éléments cartographiques.
Hermann, M., & Leuthold, H. (2003). Atlas der politischen Landschaften. Ein weltanschauliches Porträt der Schweiz. Vdf Hochschulverlag Ag.
L'Atlas des paysages politiques examine les mentalités politiques régionales en Suisse. Il montre le pays dans une perspective nouvelle et inhabituelle. Les villes, régions et villages sont présentés comme des paysages politiques dans un système de coordonnées idéologiques. Entre les pôles "gauche", "droite", "libéral" et "conservateur", ils se situent comme des "îles", des "montagnes" et des "fossés" et montrent quelles sont les valeurs entre la ville et la campagne, les régions industrielles et touristiques ou Zones germanophones et francophones. C'est ainsi que vous pouvez créer une carte politique de la Suisse. Une partie introductive explique comment les facteurs économiques et culturels influencent la formation des valeurs et comment, au cours de la mondialisation, de nouvelles différences de mentalité émergent tandis que d'autres disparaissent. Dans des portraits approfondis, toutes les caractéristiques des cantons sont décrites et comparées les unes aux autres. "Pourquoi les Franches-Montagnes agricoles sont-elles positionnées à gauche, alors que l'arrière-pays industrialisé de Glaris est positionné à droite ?" ou "Pourquoi l'écart entre l'Argovie et Zurich se creuse-t-il alors que le Mittelland se rapproche ?" sont des questions qui seront explorées. Voir un aperçu de l'atlas sur Google Books.
Atlas politique de la Suisse (Office fédéral de la statistique)
L'Atlas politique de la Suisse contient tous les résultats des élections au Conseil national depuis 1919 et des référendums fédéraux depuis 1866.Articles connexes
Les plus gros émetteurs directs de CO? en France
Climate Change Explorer, un outil cartographique pour visualiser les projections climatiques
Qualité de l'air et centrales thermiques au charbon en Europe : quelle transition énergétique vraiment possible ?Calculer le bilan carbone de nos déplacements aériens
La France est-elle préparée aux dérèglements climatiques à l'horizon 2050 ?
Climate Trace, une plateforme pour visualiser et télécharger des données sur les émissions de gaz à effet de serre (GES)
Environnement et justice dans les paysages anthropisés. Une exposition virtuelle du Leventhal Center
Etudier la vulnérabilité environnementale et sociale en Amazonie colombienne à travers un outil de cartographie en ligne
Cartographier les arbres. Entre visions esthétiques et enjeux environnementaux
-
sur Atlas des migrations dans le monde (Migreurop)
Publié: 26 October 2024, 7:42am CEST
Migreurop publie sur son site un certain nombre de cartes issues de son « Atlas des migrations dans le monde. Libertés de circulation, frontières, inégalités », publié en 2022.
Ce 4ème atlas de Migreurop « propose un traitement original et éclairant des enjeux migratoires contemporains à partir de la notion polysémique de « liberté de circulation ». Slogan utilisé pour marquer un rejet radical des politiques migratoires actuelles, cette notion est également l’un des piliers de la construction européenne, comme d’autres espaces régionaux. Pour mieux la cerner, ce 4ème Atlas propose une analyse critique des politiques qui ont été mises en œuvre par les États pour faciliter les mobilités de manière générale. Il donne également à voir la manière dont les migrant-e-s affrontent et détournent quotidiennement les politiques d’immigration restrictives pour mettre en œuvre leur propre liberté de circulation. »- La solidarité à l’épreuve de la liberté de circulation
- Conditions d’accès et de cessation du droit à la résidence des diffe?rents espaces de libre circulation
- Pratiques de résistance et solidarités en Méditerranée
- Transhumance et nomadisme en Afrique de l’Ouest
- Les migrations environnementales dans l’histoire
- Personnes trans en migration
- Les battantes de la frontière maroco-espagnole
- L’espace socialiste de libre circulation (1945-1970)
Migreurop est un réseau euro-africain d’associations de défense des droits, de militant·e·s et de chercheuses et chercheurs. Son objectif est d’identifier, faire connaître et dénoncer les conséquences des politiques migratoires européennes sur les conditions de vie et le respect des droits des personnes en migration, tout au long du parcours d’exil (les entraves à la mobilité, la fermeture des frontières, l’enfermement formel et informel, les formes diverses d’expulsion, ainsi que l’externalisation des contrôles migratoires et de l’asile pratiquée par l’Union européenne et ses États membres). Le réseau Migreurop contribue ainsi à la défense des droits fondamentaux des exilé·e·s (dont celui de "quitter tout pays y compris le sien") et à promouvoir la liberté de circulation et d’installation pour toutes et tous.
Articles connexes
MigrExploreR pour géo-visualiser des migrations internationales
Cartographier les dérives de migrants en mer Égée (Forensic Architecture)
Rapport mondial 2023 sur les déplacements internes (Conseil norvégien pour les réfugiés)
Cartographier les migrations internationales
Étudier les migrations à l'échelle infranationale pour l'ensemble des pays du monde
Consulter ou élaborer des cartes de flux dynamiques sur Internet (flow maps)
Une data-story sur les flux de migrations en Afrique
Une data visualisation pour étudier les vagues d'immigration aux Etats-Unis (1790-2016)
Analyser et discuter les cartes des "pays à éviter" pour les voyageurs
-
sur Cartes et données sur la population mondiale (Population & Sociétés, 2024)
Publié: 25 October 2024, 8:13pm CEST
Gilles Pison et Svitlana Poniakina, « Tous les pays du monde (2024) », Population & Sociétés, n° 626, INED, octobre 2024 (disponible au format pdf).
Tous les deux ans, la revue Population & Sociétés publie un numéro intitulé « Tous les pays du monde » qui présente un tableau de la population mondiale s’appuyant sur les estimations et projections des Nations unies. La population mondiale compte 8,2 milliards d’habitants en 2024. Elle a été multipliée par plus de huit depuis deux siècles, et devrait continuer à croître jusqu’à atteindre peut-être 10 milliards à la fin du XXIe siècle. Comment est-elle répartie dans le monde ? Quels sont les pays dont la fécondité est la plus forte ? Ceux où l’espérance de vie est la plus élevée ?
Les indicateurs démographiques sont identiques aux éditions précédentes :
- superficie,
- population (estimée à la mi-2024),
- taux de natalité et de mortalité,
- taux de mortalité infantile,
- indice synthétique de fécondité,
- part des moins de 15 ans et des 65 ans et plus dans la population totale,
- espérances de vie masculine et féminine à la naissance,
- revenu national brut par habitant en parité du pouvoir d’achat.
Il faut noter que la plupart des indicateurs sont des estimations, car les données de recensement ou d’enquête et les statistiques d’état civil ne sont pas encore disponibles pour l’année 2024 elle-même.
Dans chacun des dix-huit petits tableaux, les pays ou entités sont classés selon un indicateur par ordre croissant ou décroissant. Dans les sept premiers tableaux, le total mondial est indiqué et une ligne sépare les pays dont le cumul dépasse la moitié du total mondial. Par exemple dans le tableau 2, les sept pays les plus peuplés (Inde, Chine, États-Unis, Indonésie, Pakistan, Nigeria, Brésil) totalisent 4,2 milliards d’habitants, soit plus de la moitié de la population mondiale estimée à 8,2 milliards. Les pays figurant dans les tableaux 8 à 18 ont été sélectionnés en combinant différents critères comme les pays en tête et en queue de classement, les pays les plus peuplés, les plus vastes, les pays francophones. Dans le tableau 10, les pays sont classés selon le taux de mortalité. Il peut paraître étonnant qu’avec 8 décès pour 1 000 habitants en 2024, le Burkina Faso soit mieux classé que le Japon qui en compte 12 ‰. Le nombre de décès relativement faible au Burkina Faso vient du fait que sa population est jeune et que la proportion de personnes âgées y est très faible, alors qu’à l’inverse elle est élevée au Japon. Le calcul de l’espérance de vie, qui tient compte de la répartition par âge de la population, donne une idée plus juste des contrastes de mortalité (tableau 12). Le Japon se retrouve alors en tête du classement avec l’espérance de vie la plus élevée du monde (85 ans), alors que le Burkina Faso se situe presque en fin du classement (61 ans). Dans le dix-septième et avant-dernier petit tableau, les pays sont classés selon la proportion des 15-64 ans dans la population totale. Elle donne une idée de l’importance de la population d’âge actif. Elle est particulièrement élevée dans les petits États du golfe Persique qui accueillent une importante population de travailleurs immigrés venus sans leur famille, et dans les pays où la fécondité a fortement baissé pour atteindre des niveaux bas (Espagne, Russie, Corée du Sud, Chine, Iran). La pyramide des âges de ces pays s’est rétrécie à la base, alors que leur sommet est encore très étroit. Cette situation ne devrait pas durer, et la proportion de 15-64 ans pourrait se réduire au fur et à mesure du vieillissement de la population.
Pour en savoir plus sur la population mondiale consultez le site de l’Ined : www.ined.fr
Nations unies, Division de la population, 2024, World Population Prospects : The 2024 Revision, New York
[esa.un.org]Banque mondiale : [https:]]
Pour compléter
Le site Géoconfluences reprend ces données et propose une série de cartes thématiques à partir d'elles. Le fichier est à télécharger directement au format csv ou xls. Les cartes peuvent être réalisées dans le logiciel Khartis (fichier projet mis à disposition).
Population mondiale par pays en 2024 et projections 2050 via @InedFr et @ONU_fr
— Géoconfluences (@Geoconfluences) October 25, 2024
?? [https:]]
La croissance démographique mondiale va se poursuivre mais ralentir, d'après l'ONU. @Geoconfluences en profite pour faire quelques cartes. pic.twitter.com/Lshp4AwAnuLa Cité des sciences a une page internet sur laquelle on peut suivre en direct l'évolution de la population urbaine par continent. Il suffit de cliquer sur les chiffres pour voir l'augmentation par seconde. Il s'agit de l'adaptation web d'une manipulation présentée dans le cadre de l'exposition "Mutations urbaines, la ville est à nous !" proposée à la Cité des sciences et de l'industrie du 14 juin 2016 au 5 mars 2017.
[https:]]Articles connexes
Utiliser Khartis dans le cadre de la géographie scolaire
Datavisualisation : une population mondiale à 8 milliards d’habitants (Visual Capitalist)
Journée mondiale de la population : 8 milliards d'habitants en 2022
Utiliser la grille mondiale de population de la plateforme Humanitarian Data Exchange
Données carroyées de population à l'échelle mondiale sur le site WorldPop
Le vieillissement de la population européenne et ses conséquences
Les villes face au changement climatique et à la croissance démographique
-
sur L’Europe et les Etats-Unis
Publié: 25 October 2024, 4:52pm CEST par r.a.

P. Etienne au Café de Flore
Les Cafés géographiques reçoivent, ce mardi 15 octobre, Philippe Etienne, diplomate qui a exercé sa carrière dans plusieurs villes européennes (Belgrade, Bonn, Moscou, Bruxelles, Bucarest) avant d’être nommé ambassadeur de France aux Etats-Unis de 2019 à 2023. Il a donc une bonne connaissance des deux mondes qui se font face de part et d’autre de l’Atlantique nord et de l’évolution de leurs relations, dans un contexte international dangereux et complexe (terrorisme, transition climatique…). 80 ans après la Libération, la guerre en Ukraine a ramené l’Europe dans un monde brutal alors que l’U.E., fille de la IIe Guerre mondiale, était censée lui apporter paix et prospérité « éternellement ». Comment aujourd’hui nos démocraties peuvent-elles défendre nos valeurs ?
L’Europe doit faire face à l’évolution des Etats-Unis.Dans les décennies d’après-guerre, il était évident que la sécurité européenne était assurée par les Etats-Unis dans le cadre de l’OTAN. Mais actuellement les pays européens s’inquiètent d’une double évolution de leur grand allié. D’une part il est dans une phase de retrait mondial après avoir connu des échecs (en Afghanistan par exemple). D’autre part la priorité de sa politique extérieure réside dans sa compétition avec la Chine, notamment sur le plan technologique. Quel que soit le résultat des élections présidentielles du mois prochain, cette priorité subsistera. Mais les conséquences ne seront pas les mêmes pour l’Ukraine, donc pour l’Europe, car D. Trump arrêtera de la soutenir militairement.
L’Europe est donc vulnérable.
Quelle est la situation actuelle de l’U.E. ?Le problème majeur de l’U.E. aujourd’hui est son retard de compétitivité en matière technologique, ce qui a des conséquences sur sa sécurité et son indépendance.
L’U.E. est pourtant capable de bonnes réactions, mais prises avec retard. On peut distinguer trois points positifs.
En premier, l’U.E. a réussi à réagir avec succès face à deux crises, la crise financière de 2007/2008 (le pire a été évité grâce à des décisions comme la création d’un fonds de stabilisation) et la crise sanitaire de la COVID-19.
En second, on peut relever que les Européens ont pris conscience du rôle positif de la solidarité européenne et le concept de souveraineté européenne est bien accepté aujourd’hui.
Le troisième point concerne la défense, longtemps dévolue à la seule OTAN. Aujourd’hui l’U.E. doit développer ses propres moyens grâce à des instruments financiers permettant des projets de recherche puis des productions communes (munitions…). Mais ce processus est trop lent. Sommes-nous capables de l’accélérer face aux risques ?
Le rapport que Mario Draghi a remis à la Commission européenne, en septembre dernier, sur la compétitivité européenne donne des pistes sur ce qu’il faut faire. Il faut développer l’innovation et construire une véritable politique industrielle européenne. Les investissements d’avenir doivent être de l’ordre de 700 milliards € par an grâce à des investissements publics et privés. Pour ce, on peut faire appel à l’épargne, abondante en Europe, mais qui ne fonctionne pas en faveur de l’économie. Il faut aussi faciliter la fusion des entreprises et améliorer le fonctionnement des start-up.
Que va faire l’U.E. du rapport Draghi ?
Questions du public- Q : dans le passé, les questions sur une défense européenne étaient taboues. Est-ce lié à l’échec de la CED ?
R : jusqu’en 1955, l’Allemagne n’a pas d’armée, puis elle recrée une armée parlementaire. C’est pour l’encadrer qu’est conçu le projet de C.E.D., mais la France attachée à sa culture stratégique particulière ne veut pas la perdre et fait échouer le projet. - Q : dans le conflit ukrainien, ce sont les Etats-Unis qui ont la main et au Moyen-Orient ce sont eux qui défendent Israël. La démocratie peut-elle être un modèle pour les pays du Sud ?
R : il est exact qu’en Ukraine ce sont les Américains qui ont la main (mais l’aide militaire américaine profite aux industries américaines), alors que les Européens sont concernés de prime abord. Aujourd’hui même les Etats-Unis ont du mal à répondre aux besoins ukrainiens. Il faudrait un effort supplémentaire de l’industrie européenne, trop lente à suivre.
Au Moyen-Orient, la France souhaiterait défendre une position plus équilibrée que celle des Etats-Unis. Possédant les communautés juive et musulmane les plus importantes d’Europe, elle a le souci de la cohésion de sa société. Mais les pays de l’U.E. connaissent des divergences sur ce sujet. Certains membres ont reconnu un Etat de Palestine alors que l’Allemagne, en mémoire de la Shoah, soutient Israël.
- Q : dans la guerre en Ukraine, quelle est la capacité militaire russe ?
R : la Russie fait de gros efforts mais elle bénéficie aussi d’un soutien notable de l’Iran et de la Corée du Nord.
- Q : les Etats-Unis sont un Etat fédéral alors que les peuples de l’U.E. ont un mal fou à se sentir européens.
R : il est exact que l’U.E. n’est pas une fédération, ce qui est un facteur de ralentissement, mais la diversité est à la base de l’identité européenne. Les Européens peuvent accélérer la prise de décision quand c’est nécessaire car ils ont de nombreux intérêts communs.
- Q : il est difficile aux Européens de s’approprier une vision commune à cause de l’incapacité de l’U.E. à faire connaître tout ce qui est fait en faveur de tous les Européens.
R : tout à fait d’accord. En plus les gouvernements ont tendance à rejeter tous les problèmes sur l’U.E.
- Q : un des fondements de l’identité européenne ne serait-il pas le refus d’assumer la puissance ? Les Européens sont dans l’incapacité de reconnaître la guerre idéologique menée par la Russie, la Chine, l’Iran…
R : en effet en-dehors de la France, beaucoup d’Etats refusent la notion de « puissance », mais les choses sont en train de changer. On assiste à une prise de conscience de la nécessité de réagir, notamment face à la « guerre informationnelle » conçue pour nous diviser. Des instruments de vigilance sont développés, mais cette prise de conscience est encore insuffisante.
- Q : le rapport Draghi a eu peu de diffusion en France. Comment a-t-il été pris en compte au niveau des instances européennes ?
R : des parties de ce rapport font l’objet de travaux (par exemple sur les autos électriques, les titres européens…). Mais il faudrait que les gouvernements européens fassent un plan de travail à partir de l’ensemble du rapport.
- Q : faut-il laisser la politique de Défense aux mains des marchés financiers ?
R : M. Draghi préconise une politique industrielle d’Etat avec deux sources possibles de financement, publique et privée. Il n’est pas question de confier la Défense aux marchés financiers.
- Q : les Européens n’ont pas la culture du risque (qu’il s’agisse de risques financiers ou face aux agressions militaires).
R : tout à fait d’accord. L’aversion aux risques est une des raisons de notre retard technologique. A la différence des Etats-Unis, on ne reconnaît pas chez nous le droit à l’erreur. Néanmoins les jeunes Européens sont plus disposés à prendre des risques.
- Q : si la Russie faisait une percée importante en Ukraine, l’Europe pourrait-elle faire quelque chose ?
R : on constate actuellement une usure de l’Ukraine sur le plan humain, mais il ne faut pas minimiser les fortes pertes russes. L’U.E. doit rester aux côtés de l’Ukraine. - Q : les aides de l’U.E. sont très éparpillées.
R : d’accord. Il faudrait les recentrer sur les programmes industriels d’intérêt commun. - Q : la politique de Défense européenne est imposée par le retrait américain.
R : les Américains voudraient que nous augmentions nos capacités, mais qu’ils restent les chefs.
- Q : les présidents américains n’ont plus de racines européennes.
R : les Wasps ont des rapports complexes avec l’Europe et la population est composée de plus en plus de latinos et d’Asiatiques. Cette évolution a des conséquences sur les relations avec l’Europe.
- Q : qu’en est-il de la règle des 3% de déficit public ?
R : la règle des 3% ne doit pas pénaliser les investissements dans l’avenir. Il y a eu un assouplissement après la COVID-19.
- Q : quel est votre avis sur les élections américaines à venir ? y a-t-il un risque de guerre civile si Kamala Harris est élue ?
R : Trump ne reconnaitra pas sa défaite. Il y a un risque de contestation des deux côtés, ce qui est favorisé par le système électoral. L’élection de Trump engendrerait beaucoup de conflits avec l’Europe (guerre commerciale…). Dans le corps électoral, il y a beaucoup de divisions. Les femmes votent démocrate en majorité, ce qui est le contraire chez les hommes. Les divisions sont aussi fortes sur la politique à mener au Moyen-Orient.
Compte rendu de Michèle Vignaux
- Q : dans le passé, les questions sur une défense européenne étaient taboues. Est-ce lié à l’échec de la CED ?
-
sur [Stage Développement logiciel] - Refonte de l'interface d’administration d'un outil de valorisation des sentiers et activités outdoor
Publié: 25 October 2024, 9:08am CEST par Lise Benazeth
Contrat : Stage
Lieu : Toulouse